- A-Z Commands
- Privacy Policy
- Terms & Conditions
- Google News

Top 10 Best Open Source Speech Recognition Tools for Linux

Speech is a popular and smart method in modern time to make interaction with electronic devices. As we know, there are many open source speech recognition tools available on different platforms. From the beginning of this technology, it has been improved simultaneously in understanding the human voice. This is the reason; it has now engaged a lot of professionals than before. The technical advancement is strong enough to make it more clear to the common people.
Open Source Speech Recognition Tools
Open source voice recognition tool is not much available like the typical software we use in our daily lives in Linux platform. After a long way of research, we found some well-featured applications for you with a short description. Let’s have a look at the points below!
Kaldi is a special kind of speech recognition software, started as a part of a project at John Hopkins University. This toolkit comes with an extensible design and written in C++ programming language. It provides a flexible and comfortable environment to its users with a lot of extensions to enhance the power of Kaldi.

Noteworthy Features of Kaldi
- A free and flexible open source voice recognition application, under the Apache license.
- Runs on multiple platforms, including GNU/Linux , BSD, and Microsoft Windows.
- Provides support to install and configure the application to your system.
- Besides the speech recognition system, it also supports deep neural networks and linear transforms.
2. CMUSphinx
CMUS Sphinx comes with a group of featured-enriched systems with several pre-built packages related to speech recognition. It is an open source program , developed at Carnegie Mellon University. You will get this speaker-independent recognition tool in several languages, including French, English, German, Dutch, and more.

Noteworthy Features of CMUSphinx
- It is an easy-to-use and fast speech recognition system with a user-friendly interface.
- Comes with a flexible design and efficient system, even in low resource platforms.
- Provides acoustic model training tools through its Sphinxtrain package.
- Helps to perform different types of tasks through its helpful packages, including keyword spotting, pronunciation evaluation, alignment, and more.
- It is a cross-platform tool that supports both Windows and Linux systems.
Get CMUSphinx
3. DeepSpeech
DeepSpeech is an open source speech recognition engine to convert your speech to text. It is a free application by Mozilla. To run DeepSearch project to your device, you will need Python 3.r or above. Also, it needs a Git extension file, namely Git Large File Storage. It is used for versioning large files while you run it to your system.

Noteworthy Features of DeepSpeech
- DeepSpeech uses TensorFlow framework to make the voice transformation more comfortable.
- It supports NVIDIA GPU, which helps to perform quicker inference.
- You can use the DeepSearch inference in three different ways; The Python package, Node.JS package, or Command-line client .
- Each time you want to run this software to your system, you’ll need to activate the virtual environment by Python command.
- It needs a Linux or Mac environment to run this application.
Get DeepSpeech
4. Wav2Letter++
WavLetter++ is a modern and popular speech recognition tool, developed by the Facebook AI Research team. It is another open source program under the BCD license. This superfast voice recognition software was built in C++ and introduced with a lot of features. It provides the facility of language modeling, machine translation, speech synthesis, and more to its users in a flexible environment.
Noteworthy Features of Wav2Letter++
- It contains an active community in popular platforms like Facebook and Google group to assist its users worldwide.
- WavLetter++ is a fast and flexible toolkit which uses ArrayFire tensor library for the maximum efficiency.
- It lets you work with a high-performance framework like wav2letter++, which helps to do a successful research and model tuning.
- Also, it provides complete documentation through the tutorial sections.
- In the recipes folder, you will get the detailed recipes for WSJ, Timit, and Librispeech.
Get Wav2Letter++
Julius is comparatively an older open source voice recognition software developed by Lee Akinobu. This tool is written in the C programming language by the developers of Kawahara Lab, Kyoto University. It is a high-performance speech recognition application having a large vocabulary. You can use it in both English and Japanese languages. It can be a great choice if you want to use it for academic and research purposes.

Noteworthy Features of Julius
- Julius is a highly configurable application that can set different search parameters to tune its performance.
- This tool is based on a 2-pass strategy which provides you a real-time and high-quality performance.
- It is a cross-platform project that runs on Linux, BSD, Windows, and Android Systems.
- Integrated with Julian, a grammar-based recognition parser.
- Besides supporting rule-based grammar, it also provides Word graph output, Confidence scoring, GMM-based input rejection, and many more facilities.
Get Julius
Simon comes with a modern and easy-to-use speech recognition software, developed by Peter Grasch. It is another open source program under the GNU General Public License. You are free to use Simon in both Linux and Windows systems. Also, it provides the flexibility to work with any language you want.

Noteworthy Features of Simon
- Using its voice-controlled calculator, Simon provides the facility to do various arithmetic operations.
- Compatible with Skype and other popular VOIP programs to establish an easy communication system with friends and relatives.
- It allows users to watch slide shows and videos, listen to music , and more with a few simple voice commands.
- Also, it is an essential tool in reading newspapers and surfing the internet.
Mycroft comes with an easy-to-use open source voice assistant for converting voice to text. It is regarded as one of the most popular Linux speech recognition tools in modern time, written in Python. It allows users to make the best use of this tool in a science project or enterprise software application. Also, it can be used as a practical assistant, that can tell you the time, date, weather, and more like these.
Noteworthy Features of Mycroft
- Integrated with the most popular social media and professional platforms, including Facebook, Github , LinkedIn, and more.
- You can run this application on different software and hardware platforms. It can be a desktop or a Raspberry Pi .
- Besides being a smart voice assistant, it provides the facility of the audio record, machine learning, software library, and more.
- It lets users convert the natural language to machine-readable data through Adapt, an intent parser of Mycroft.
Get Mycroft
8. OpenMindSpeech
Open Mind Speech is one of the essential Linux speech recognition tools aims to convert your speech to text for free. It is a part of Open Mind Initiative, runs its operation, especially for developers. This program was introduced with different names like VoiceControl, SpeechInput, and FreeSpeech before getting the present name.
Noteworthy Features of OpenMindSpeech
- It uses the Overflow environment in the voice recognition operation to make the complex applications flexible.
- Open Mind Speech is mostly compatible with Linux and UNIX-based platforms.
- Using the internet, it can collect speech data from e-citizens, who are the contributors of raw data.
Get OpenMindSpeech
9. SpeechControl
Speech Control is a free speech recognition application, suitable for any Ubuntu distro. It comes with a graphical user interface based on Qt. Though it is still in its early development stage, you can use it for your simple project.

Noteworthy Features of SpeechControl
- Speech Control is an open source program under the General Public License (GPL).
- It aims to work as a virtual assistant that provides repetitive task guidance to execute the process smoothly.
- It is mostly suitable for Linux-based platforms.
- Also, provides easy-to-understand user documentation with project details.
Get SpeechControl
10. Deepspeech.pytorch
Deepspeech.pytorch is another mentionable open source speech recognition application which is ultimately implementation of DeepSpeech2 for PyTorch. It contains a set of powerful networks based DeepSpeech2 architecture. With many helpful resources, it can be used as one of the essential Linux speech recognition tools for research and project development.
Noteworthy Features of Deepspeech.pytorch
- Supports noise augmentation that helps to increase robustness at the time of loading audio.
- To send the post request to the server, it provides a basic server script.
- Support several datasets for downloading, including TEDLIUM, AN4, Voxforge, and LibriSpeech.
- Lets you add noise into the training data through noise injection.
- Supports Visdom and Tensorboard for visualizing training on scientific experimentation.
Get Deepspeech.pytorch
Finishing Thoughts
So, we have reached the finishing point on open source speech recognition tools for Linux. Hope, you got comprehensive information regarding this topic. The above-mentioned applications are free, easy-to-use, and ready to be a part of your academic or personal project.
Which one do you prefer most? If you have any other choices, then don’t hesitate to let us know. Please do share this article with your community, if you get it helpful. Till then, have a nice time. Thanks!

I dont understand alot of this github stuff i just need a deb
i just want to talk to my computer
I frequently make live videos (usually streamed by Instagram or Facebook) and I would like to know if there is a software that can automatically transcribe what I say in these videos, like Youtube does automatically for subtitles. Anyone can help? Thanks
I’m searching for a simple speech recognition to create a variable to select audio files to play for a blind person. This lady only wants to listen to a Bible version called The Message Bible. Unfortunately it isn’t available in a manner that doesn’t require the User to respond to visual selections. I envision a simple command line file triggered by a variable created by her voice when she says something like “Goto the book of Psalms, chapter 23. (since Psalms is indexed by Psalm they would be inside folders marked as chapters.
LEAVE A REPLY Cancel reply
Save my name, email, and website in this browser for the next time I comment.
You May Like It!
11 best reference manager and bibliography tools for linux, visual studio code – a free and open source code editor for ubuntu, linux supported fastest supercomputer in the world is here- “the summit”, the 20 best to-do list apps for android device, trending now, the 20 best science apps for android device, 10 best vpn apps for iphone and ipad, ultimate maia gtk theme and icon packs for gnome and plasma, 15 best torrent clients for linux system, 15 best internet of things (iot) books you should read in 2024, linux or windows: 25 things to know while choosing the best platform, 5 most popular linux distros: which one is right for you, studio by creative fabrica: what’s so good, waiting for you, top 20 best cryptocurrency exchange platforms in 2024, 15 independent linux distros you should know in 2024.
© 2024. All Rights Reserved. Ubuntu is a registered trademark of Canonical Ltd . Proudly Hosted on Vultr .
The Linux Portal Site

13 Best Free Linux Speech Recognition Tools
Speech is an increasingly popular method of interacting with electronic devices such as computers, phones, tablets, and televisions. Speech is probabilistic, and speech engines are never 100% accurate. But technological advances have meant speech recognition engines offer better accuracy in understanding speech. The better the accuracy, the more likely customers will engage with this method of control. And, according to a study by Stanford University, the University of Washington and Chinese search giant Baidu, smartphone speech is three times quicker than typing a search query into a screen interface.
Witness the rise of intelligent personal assistants, such as Siri for Apple, Cortana for Microsoft, and Mycroft for Linux. The assistants use voice queries and a natural language user interface to attempt to answer questions, make recommendations, and perform actions without the requirement of keyboard input. And the popularity of speech to control devices is testament to dedicated products that have dropped in large quantities such as Amazon Echo. Speech recognition is also used in smart watches, household appliances, and in-car assistants. In-car applications have lots of mileage (excuse the pun). Some of the in-car applications include navigation, asking for weather forecasts, finding out the traffic situation ahead, and controlling elements of the car, such as the sunroof, windows, and music player.
The key challenge for developing speech recognition software, whether it’s used in a computer or another device, is that human speech is extremely complex. The software has to cope with varied speech patterns, and individuals’ accents. And speech is a dynamic process without clearly distinguished parts. Fortunately, technical advancements have meant it’s easier to create speech recognition tools. Powerful tools like machine learning and artificial intelligence, coupled with improved speech algorithms, have altered the way these tools are developed. You don’t need phoneme dictionaries. Instead, speech engines can employ deep learning techniques to cope with the complexities of human speech.
There aren’t that many speech recognition toolkits available, and some of them are proprietary software. Fortunately, there are some very exciting open source speech recognition toolkits available. These toolkits are meant to be the foundation to build a speech recognition engine.
This article highlights the best open source speech recognition software for Linux. The rating chart summarizes our verdict.

Let’s explore the 13 free speech recognition tools at hand. For each title we have compiled its own portal page with a full description and an in-depth analysis of its features.

This site uses Akismet to reduce spam. Learn how your comment data is processed .

What is really wrong with the license terms of HTK?

This clause is particularly damning:
2.2 The Licensed Software either in whole or in part can not be distributed or sub-licensed to any third party in any form.

…and nothing else matters…

Sadly my machine doesn’t have sufficient RAM on my graphics card to experiment with DeepSpeech. Any recommendations for a good GPU that works well with DeepSpeech?

Thanks for the comprehensive info regarding the open source tools. From the perspective of a visually impaired person, what I would like to know is which of these would be most suitable (now or in near future) for dictating to get text that could go into documents, e-mail, etc. Is that Simon?

Yes, Simon is very good for what you’re looking for. Most of the other open source speech recognition tools are not really aimed at a desktop user e.g. they are for academic research etc.

Is there any speech to text tool like Dragon Nat in linux? I work as a translator and I have it on windows but I wonder if there is something like that out there.

Baidu is required by Chinese laws to act, as and when demanded, as an arm of the Chinese Communist Party. Not sure I would trust a tool created by them.

I think you are jumping on the Hauwei bandwagon with absolutely no justification.
A few of the open source programs here are using speech recognition models based on Baidu DeepSpeech2. But the model is an approach, not a means of capturing data or doing anything else nefarious.
What concerns are you raising? The source code of the programs here (DeepSpeech etc) are open source, so you can see exactly what they are doing.

completely agree

This account is solely made for saying yes to other accounts called “john”

LinuxLinks doesn’t have accounts

Could Android speech recognition be ported to Linux desktop packages, since android is open source?

Top 11 Open Source Speech Recognition/Speech-to-Text Systems

Last Updated on: March 21, 2024
Table of Contents:
What is a Speech Recognition Library/System?
What is an open source speech recognition library, what are the benefits of using open source speech recognition, 1. project deepspeech, 4. flashlight asr (formerly wav2letter++), 5. paddlespeech (formerly deepspeech2), 6. openseq2seq, 10. whisper, 11. styletts2, what is the best open source speech recognition system.
A speech-to-text (STT) system , or sometimes called automatic speech recognition (ASR) is as its name implies: A way of transforming the spoken words via sound into textual data that can be used later for any purpose.
Speech recognition technology is extremely useful. It can be used for a lot of applications such as the automation of transcription, writing books/texts using sound only, enabling complicated analysis on information using the generated textual files and a lot of other things.
In the past, the speech-to-text technology was dominated by proprietary software and libraries. Open source speech recognition alternatives didn’t exist or existed with extreme limitations and no community around.
This is changing, today there are a lot of open source speech-to-text tools and libraries that you can use right now.
It is the software engine responsible for transforming voice to texts.
It is not meant to be used by end users. Developers will first have to adapt these libraries and use them to create computer programs that can enable speech recognition to users.
Some of them come with preloaded and trained dataset to recognize the given voices in one language and generate the corresponding texts, while others just give the engine without the dataset, and developers will have to build the training models themselves.
You can think of them as the underlying engines of speech recognition programs.
If you are an ordinary user looking for speech recognition, then none of these will be suitable for you, as they are meant for development use only.
The difference between proprietary speech recognition and open source speech recognition, is that the library used to process the voices should be licensed under one of the known open source licenses, such as GPL, MIT and others.
Microsoft and IBM for example have their own speech recognition toolkits that they offer for developers, but they are not open source. Simply because they are not licensed under one of the open source licenses in the market.
Mainly, you get few or no restrictions at all on the commercial usage for your application, as the open source speech recognition libraries will allow you to use them for whatever use case you may need.
Also, most – if not all – open source speech recognition toolkits in the market are also free of charge, saving you tons of money instead of using the proprietary ones.
The benefits of using open source speech recognition toolkits are indeed too many to be summarized in one article.
Top Open Source Speech Recognition Systems

In our article we’ll see a couple of them, what are their pros and cons and when they should be used.
This project is made by Mozilla, the organization behind the Firefox browser.
It’s a 100% free and open source speech-to-text library that also implies the machine learning technology using TensorFlow framework to fulfill its mission. In other words, you can use it to build training models by yourself to enhance the underlying speech-to-text technology and get better results, or even to bring it to other languages if you want.
You can also easily integrate it to your other machine learning projects that you are having on TensorFlow. Sadly it sounds like the project is currently only supporting English by default. It’s also available in many languages such as Python (3.6).
However, after the recent Mozilla restructure, the future of the project is unknown, as it may be shut down (or not) depending on what they are going to decide .
You may visit its Project DeepSpeech homepage to learn more.
Kaldi is an open source speech recognition software written in C++, and is released under the Apache public license.
It works on Windows, macOS and Linux. Its development started back in 2009. Kaldi’s main features over some other speech recognition software is that it’s extendable and modular: The community is providing tons of 3rd-party modules that you can use for your tasks.
Kaldi also supports deep neural networks, and offers an excellent documentation on its website . While the code is mainly written in C++, it’s “wrapped” by Bash and Python scripts.
So if you are looking just for the basic usage of converting speech to text, then you’ll find it easy to accomplish that via either Python or Bash. You may also wish to check Kaldi Active Grammar , which is a Python pre-built engine with English trained models already ready for usage.
Learn more about Kaldi speech recognition from its official website .
Probably one of the oldest speech recognition software ever, as its development started in 1991 at the University of Kyoto, and then its ownership was transferred to as an independent project in 2005. A lot of open source applications use it as their engine (Think of KDE Simon).
Julius main features include its ability to perform real-time STT processes, low memory usage (Less than 64MB for 20000 words), ability to produce N-best/Word-graph output, ability to work as a server unit and a lot more.
This software was mainly built for academic and research purposes. It is written in C, and works on Linux, Windows, macOS and even Android (on smartphones). Currently it supports both English and Japanese languages only.
The software is probably available to install easily using your Linux distribution’s repository; Just search for julius package in your package manager.
You can access Julius source code from GitHub.
If you are looking for something modern, then this one can be included.
Flashlight ASR is an open source speech recognition software that was released by Facebook’s AI Research Team. The code is a C++ code released under the MIT license.
Facebook was describing its library as “the fastest state-of-the-art speech recognition system available” up to 2018.
The concepts on which this tool is built makes it optimized for performance by default. Facebook’s machine learning library Flashlight is used as the underlying core of Flashlight ASR. The software requires that you first build a training model for the language you desire before becoming able to run the speech recognition process.
No pre-built support of any language (including English) is available. It’s just a machine-learning-driven tool to convert speech to text.
You can learn more about it from the following link .
Researchers at the Chinese giant Baidu are also working on their own speech recognition toolkit, called PaddleSpeech.
The speech toolkit is built on the PaddlePaddle deep learning framework, and provides many features such as:
- Speech-to-Text support.
- Text-to-Speech support.
- State-of-the-art performance in audio transcription, it even won the NAACL2022 Best Demo Award ,
- Support for many large language models (LLMs), mainly for English and Chinese languages.
The engine can be trained on any model and for any language you desire.
PaddleSpeech ‘s source code is written in Python, so it should be easy for you to get familiar with it if that’s the language you use.
Developed by NVIDIA for sequence-to-sequence models training.
While it can be used for way more than just speech recognition, it is a good engine nonetheless for this use case. You can either build your own training models for it, or use models which are shipped by default. It supports parallel processing using multiple GPUs/Multiple CPUs, besides a heavy support for some NVIDIA technologies like CUDA and its strong graphics cards.
As of 2021 the project is archived; it can still be used but looks like it is no longer under active development.
Check its speech recognition documentation page for more information, or you may visit its official source code page .
One of the newest open source speech recognition systems, as its development just started in 2020.
Unlike other systems in this list, Vosk is quite ready to use after installation, as it supports 10 languages (English, German, French, Turkish…) with portable 50MB-sized models already available for users (There are other larger models up to 1.4GB if you need).
It also works on Raspberry Pi, iOS and android devices, and provides a streaming API which allows you to connect to it to do your speech recognition tasks online. Vosk has bindings for Java, Python, JavaScript, C# and NodeJS.
Learn more about Vosk from its official website .
An end-to-end speech recognition engine which implements ASR.
Written in Python and licensed under the Apache 2.0 license. Supports unsupervised pre-training and multi-GPUs training either on same or multiple machines. Built on the top of TensorFlow.
Has a large model available for both English and Chinese languages.
Visit Athena source code .
Written in Python on the top of PyTorch.
Also supports end-to-end ASR. It follows Kaldi style for data processing, so it would be easier to migrate from it to ESPnet. The main marketing point for ESPnet is the state-of-art performance it gives in many benchmarks, and its support for other language processing tasks such as speech-to-text (STT), machine translation (MT) and speech translation (ST).
Licensed under the Apache 2.0 license.
You can access ESPnet from the following link .
The newest speech recognition toolkit in the family, developed by the famous OpenAI company (the same company behind ChatGPT ).
The main marketing point for Whisper is that it does not specialize in a set of training datasets for specific languages only; instead, it can be used with any suitable model and for any language. It was trained on 680 thousand hours of audio files, one third of which were non-English datasets.
It supports speech-to-text, text-to-speech, speech translation. And the company claims that its toolkit has 50% less errors in the output compared to other toolkit in the market.
Learn more about Whisper from its official website .
The newest speech recognition library on the list, which was just released in the middle of November, 2023. It employs diffusion techniques with large speech language models (SLMs) training in order to achieve more advanced results than other models.
The makers of the model published it along with a research paper, where they make the following claim about their work:
This work achieves the first human-level TTS synthesis on both single and multispeaker datasets, showcasing the potential of style diffusion and adversarial training with large SLMs.
It is written in Python, and has some Jupyter notebooks shipped with it to demonstrate how to use it. The model is licensed under the MIT license.
There is an online demo where you can see different benchmarks of the model: https://styletts2.github.io/
If you are building a small application that you want to be portable everywhere, then Vosk is your best option, as it is written in Python and works on iOS, android and Raspberry pi too, and supports up to 10 languages. It also provides a huge training dataset if you shall need it, and a smaller one for portable applications.
If, however, you want to train and build your own models for much complex tasks, then any of PaddleSpeech, Whisper and Athena should be more than enough for your needs, as they are the most modern state-of-the-art toolkits.
As for Mozilla’s DeepSpeech , it lacks a lot of features behind its other competitors in this list, and isn’t really cited a lot in speech recognition academic research like the others. And its future is concerning after the recent Mozilla restructure, so one would want to stay away from it for now.
Traditionally, Julius and Kaldi are also very much cited in the academic literature.
Alternatively, you may try these open source speech recognition libraries to see how they work for you in your use case.
The speech recognition category is starting to become mainly driven by open source technologies, a situation that seemed to be very far-fetched a few years ago.
The current open source speech recognition software are very modern and bleeding-edge, and one can use them to fulfill any purpose instead of depending on Microsoft’s or IBM’s toolkits.
If you have any other recommendations for this list, or comments in general, we’d love to hear them below!
FOSS Post has been providing high-quality content about open source and Linux software for around 7 years now. All of our content is free so that you can enjoy it whenever you like. However, consider buying us a cup of coffee by joining our Patreon campaign or doing a one-time donation to support our efforts!
Our community platform is here. Join it now so that you can explore tons of interesting and fun discussions about various open source aspects and issues!
Are you stuck following one of our articles or technical tutorials? Drop us a support request in the forum and we'll get right back to you.
You can take a number of interesting and exciting quizzes that the FOSS Post team prepared about various open source software from FOSS Quiz.

Hanny is a computer science & engineering graduate with a master degree, and an open source software developer. He has created a lot of open source programs over the years, and maintains separate online platforms for promoting open source in his local communities.
Hanny is the founder of FOSS Post.

Enter your email address to subscribe to our newsletter. We only send you an email when we have a couple of new posts or some important updates to share.
Social Links
Recent comments.
Open Source Directory
Join the force.
For the price of one cup of coffee per month:
- Support the FOSS Post to produce more content.
- Get a special account on our website.
- Remove all the ads you are seeing (including this one!).
- Get an OPML file containing +70 RSS feeds for various FOSS-related websites and blogs, so that you can import it into your favorite RSS reader and stay updated about the FOSS world!
Become a Supporter
Sign up in our modern forum to discuss various issues and see a lot of insightful, entertaining and informational content about Linux and open source software! Your content is yours and you can take it with you wherever you go.
* Premium members get a special badge.
No thanks, I’m not interested!
Originally published on August 23, 2020, Last Updated on March 21, 2024 by M.Hanny Sabbagh
'ZDNET Recommends': What exactly does it mean?
ZDNET's recommendations are based on many hours of testing, research, and comparison shopping. We gather data from the best available sources, including vendor and retailer listings as well as other relevant and independent reviews sites. And we pore over customer reviews to find out what matters to real people who already own and use the products and services we’re assessing.
When you click through from our site to a retailer and buy a product or service, we may earn affiliate commissions. This helps support our work, but does not affect what we cover or how, and it does not affect the price you pay. Neither ZDNET nor the author are compensated for these independent reviews. Indeed, we follow strict guidelines that ensure our editorial content is never influenced by advertisers.
ZDNET's editorial team writes on behalf of you, our reader. Our goal is to deliver the most accurate information and the most knowledgeable advice possible in order to help you make smarter buying decisions on tech gear and a wide array of products and services. Our editors thoroughly review and fact-check every article to ensure that our content meets the highest standards. If we have made an error or published misleading information, we will correct or clarify the article. If you see inaccuracies in our content, please report the mistake via this form .
How to enable speech-to-text in Linux with this simple app

I'm not a big user of speech-to-text but that's only because I "word" for a living and still have fingers that are capable of typing very fast. That's not something I ever take for granted. And given I've known many people over the years who depended on speech-to-text, I am always very grateful to point out the means to make an operating system more accessible.
So, when I came across the Speech Note app, I was thrilled to find it was quite simple to add speech-to-text in Linux. However, once I installed the app and started using it, I realized that it comes with a considerable caveat…it requires power (and a lot of it).
Also: How to turn on flash notifications on Android 14
The reason this app requires so much power is that speech-to-text processing happens offline, which means it will depend on your CPU (and GPU if you have one) to carry the heavy lifting. If your machine is underpowered, one of two things will happen: the computer will crash while trying to process speech-to-text, or it will happen very slowly. So, if you don't have a powerful desktop computer, you might want to depend on a third-party speech-to-text service, such as that found in Google Docs (which only works with the Chrome browser).
If you have a powerful enough machine, you can turn to the open-source Speech Note app. This app can be installed on any Linux distribution that supports Flatpak . It's important to note, however, that the base installation is very small. However, downloading the language model can take up to 2GB of space, so keep that in mind if your system has limited local storage.
Once installed and ready, Speech Note does a great job of processing speech-to-text on Linux.
Let me show you how to install and prepare Speech Note for use.
How to install Speech Note
What you'll need: To get Speech Note installed, you'll need a Linux machine with Flatpak installed and over 2GB of free internal storage. That's it. Let's make it happen.
1. Open your terminal window and install
Log into your desktop and open the terminal window app. Once the app is open, paste the following command and hit Enter on your keyboard:
Make sure to answer Y to the questions to complete the installation.
2. Open Speech Note
Click your desktop menu and look for the Speech Note launcher. If you don't see it, you might have to log out and log back into your desktop to make it appear.
Speech Note is a simple-to-use GUI app for speech to text on Linux.
3. Download your language model
From the main Speech Note window, click Languages. In the resulting pop-up, locate the language you want to download. Hover over that language and click the associated Download button. When the language model has been downloaded, click Close.
You can download as many language models as you need (so long as your machine has the storage space for it).
4. Configure Speech Note
Click the three-dot menu button in the upper left corner. From the resulting dropdown, click Settings. In the Settings popup, you'll want to consider two changes. The first is the Audio source. Click the dropdown and make sure to select the source associated with your mic. If you're using a built-in mic, you'll probably want to stick Auto. If you're using an external mic, make sure to select it from the list.
Also: Do you need a speech therapist? Now you can consult AI
The next setting is the Listening mode, for which there are three choices: one sentence, press and hold, and always on. One sentence will listen to one sentence at a time. As soon as you stop speaking, Speech Note will stop listening.
Press and hold means it will keep listening as long as you hold the Listen button. Always on means as soon as you click Listen, it will listen and continue to do so until you stop it.
There are a number of configurations you can undertake but these will get you up and running right away.
5. Use Speech Note
Using Speech Note is simple. Click the Listen button and start talking. There will be a lag between your speaking and Speech Notes transcribing. Depending on the speed of your hardware, that lag can be considerable (if the machine is underpowered).
And that's all there is to using the Speech Note app for easy speech-to-text on Linux. Remember, if your machine isn't powerful enough to handle the processing, you can always turn to Google Chrome and Google Docs (which does work quite well on Linux).
How to use Android's 'Photomoji' feature in Google Messages (and why you should)
Openai's voice engine can clone a voice from a 15-second clip. listen for yourself, how to screen calls on your android phone and stop the spam deluge.
- About AssemblyAI
Kaldi Speech Recognition for Beginners - A Simple Tutorial
Want to learn how to use Kaldi for Speech Recognition? Check out this simple tutorial to start transcribing audio in minutes.

Developer Educator at AssemblyAI
In this tutorial, we’ll use the open-source speech recognition toolkit Kaldi in conjunction with Python to automatically transcribe audio files. By the end of the tutorial, you’ll be able to get transcriptions in minutes with one simple command!
Important Note
For this tutorial, we are using Ubuntu 20.04.03 LTS (x86_64 ISA) . If you are on Windows, the recommended procedure is to install a virtual machine and follow this tutorial exactly on a Debian-based distro (preferably the exact one mentioned above - you can find an ISO here )
Before we can get started with Kaldi for Speech Recognition, we'll need to perform some installations.
Installations
Prerequisites.
The most notable prerequisite is time and space . The Kaldi installation can take hours, and consumes almost 40 GB of disk space, so prepare accordingly. If you need transcriptions ASAP, check out the Cloud Speech-to-Text APIs section!
Automatic Installation
If you would like to manually install Kaldi and its dependencies, you can move on to the next subsection . If you are comfortable with an automatic installation, you can follow this subsection.
You will need wget and git installed on your machine in order to follow along. wget comes installed natively on most Linux distributions, but you may need to open a terminal and install git with
Next, navigate into the directory in which you would like to install Kaldi, and then fetch the installation script with
This command downloads the setup.sh file, which effectively just automates the manual installation below. Be sure to open this file in a text editor and inspect it to make sure you understand it and are comfortable running it. You can then perform the setup with
Install Note
If you have multiple CPUs, you can perform a parallel build by supplying the number of processors you would like to use. For example, to use 4 CPUs, enter sudo bash setup.sh 4
Running the above command will install all of Kaldi's dependencies, and then Kaldi itself. You will be required to confirm that all dependencies are installed at one point (several minutes into the installation). We suggest checking and confirming, but if you are following along on a fresh Ubuntu 20.04.03 LTS install (perhaps on a virtual machine), then you can skip confirming by instead running
In this case, you do not need to interact with the terminal at all during installation. The installation will likely take several hours, so you can leave and come back to it when the installation is complete. Once the installation is complete, enter the project directory with
and then move on to transcribing an audio file .
Manual Installation
Before manually installing Kaldi, we’ll need to install some additional packages. First, open a terminal, and run the following commands:
Additional Information
- You can copy these commands and paste them into the terminal by right clicking in terminal and selecting “Paste”.
- We’ll also need Intel MKL , which we will install later via Kaldi if you do not have it already.
Installing Kaldi
Now we can get started installing Kaldi for Speech Recognition. First, we need to clone the Kaldi repository. In the terminal, navigate to the directory in which you’d like to clone the repository. In this case, we are cloning to the Home directory.
Run the following command:
Installing Tools
To begin our Kaldi installation, we’ll first need to perform the tools installation. Navigate into the tools directory with the following command:
and then install Intel MKL if you don’t already have it. This will take time - MKL is a large library.
Now we check to ensure all dependencies are installed. Given our preparatory installations, you should get a message telling you that all dependencies are indeed installed.
If you do not have all dependencies installed, you will get an output telling you which dependencies are missing. Install any remaining packages you need, and then rerun the extras/check_dependencies.sh command . New required installations may now appear as a result of the dependencies you just installed. Continue alternating between these two steps (checking missing dependencies and installing them) until you receive a message saying that all dependencies are installed ("all OK.") .
Finally, run make . See the install note below if you have a multi-CPU build.
If you have multiple CPUs, you can do a parallel build by supplying the "-j" option to make in order to expedite the install. For example, to use 4 CPUs, enter make -j 4
Installing Src
Next, we need to perform src install. First, cd into src
And then run the following commands. See the install note below if you have a multi-CPU build. This build may take several hours for uniprocessor systems.
Again, you can supply the -j option to both make depend and make if you have multiple CPUs in order to expedite the install. For example, to use 4 CPUs, enter make depend -j 4 and make -j 4
Cloning the Project Repository
Now it’s time to clone the project repository provided by AssemblyAI, which hosts the code required for the remainder of the tutorial. The project repository follows the structure of the other folders in kaldi/egs (the “examples” directory in Kaldi root) and includes additional files to automate the transcription generation for you.
Navigate into egs folder, clone the project repository, and then navigate into the s5 subdirectory
At this point you can delete all other folders in the egs directory. They take up about 10 GB of disk space, but consist of other examples that you may want to check out after this tutorial.
Transcribing an Audio File - Quick Usage
Now we’re ready to get started transcribing an audio file! We’ve provided everything you need to automatically transcribe a .wav file in a single line of code.
For a minimal example, all you need to do is run
This command will transcribe the provided example audio file gettysburg.wav - a 10 second .wav file containing the first line of the Gettysburg Address. The command will take several minutes to execute, after which you will find the transcription in kaldi-asr-tutorial/s5/out.txt
You will need an internet connection the first time you run main .py in order to download the pre-trained models.
If you would like to transcribe your own .wav file, first place it in the s5 subdirectory , and then run:
Where you replace gettysburg.wav with the name of your file. If the only .wav file in the s5 subdirectory is your target audio file, you can simply run python3 main.py without specifying the filename.
This automated process will work best with a single speaker and a relatively short audio. For more complicated usage, you’ll have to read the next section and modify the code to suit your needs, following along with the Kaldi documentation .
Resetting the Directory
Each time you run main.py it will call reset_directory.py , which removes all files/folders generated by main.py (except the downloaded tarballs of the pre-trained models) in order to start each run with a clean slate. This means that your out.txt transcription will be deleted if you call main.py on another file , so be sure to move out.txt to another directory if you would like to keep it before transcribing another file.
If you interrupt the main.py execution while the pre-trained models are downloading, you will receive errors downstream. In this case, run the following command to completely reset the directory (i.e. remove the pre-trained model tarballs in addition to the files/folder removed by reset_directory.py )
Transcribing an Audio File - Understanding the Code
If you’re interested in understanding how Kaldi's Speech Recognition generated the transcription in the previous section, then read on!
We’re going to dive into main.py in order to understand the entire process of generating a transcription with Kaldi. Keep in mind that our use case is a toy example to showcase how to use pre-trained Kaldi models for ASR. Kaldi is a very powerful toolkit which accommodates much more complicated usage; but it does have a sizable learning curve, so learning how to properly apply it to more complicated tasks will take some time.
Also, we’ll give brief overviews of the theory behind what’s going on in different sections, but ASR is a complicated topic, so by nature our conversation will be surface level!
Let’s get started.
We kick things off with some imports. First, we call the reset_directory.py file that clears the directory of files/folders generated by the rest of main.py so we can start with a clean slate. Then we import subprocess so we can issue bash commands, as well as some other packages which we’ll use for os navigation and file manipulation.
Argument Validation
Next, we perform some argument validation. We ensure that there is a maximum of one additional argument passed in to main.py ; and, if there is one, we ensure that is a .wav file. If there is no argument given, then we simply choose the first .wav file found by glob.glob , if such a file exists.
We save the filename (with and without extension) in variables for later use.
Kaldi File Generation
Now it’s time to create some standard files that Kaldi requires to generate transcriptions. We save the s5 directory path into a variable so that we can easily navigate back to it, and then create and navigate into a data/test directory that we will store our data in.
The first file we’ll generate is called spk2utt , which maps speakers to their utterances. For our purposes, we assume that there is one speaker and one utterance , so the file is easy to generate automatically.
Next, we create the inverse mapping in the utt2spk file. Note that this file is one-to-one, unlike the one-to-many nature of spk2utt (one speaker may have multiple utterances, but each utterance can have only one speaker). For our purposes it is once again easy to generate this file:
The last file we create is called wav.scp . It maps audio file identifiers to their system paths. We again generate this file automatically.
Finally, we return to the root directory
Note that these are not the only possible input files that Kaldi can use, just the bare minimum. For more advanced usage, such as gender mapping, check out the Kaldi documentation .
MFCC Configuration File Modification
To perform ASR with Kaldi on our audio file, we must first determine some method of representing this data in a format that a Kaldi model can handle. For this, we use Mel-frequency cepstral coefficients (MFCCs) . MFCCs are a set of coefficients that define the mel-frequency cepstrum of the audio, which itself is a cosine transform of the logarithmic power spectrum of a nonlinear mapping (mel-frequency) of the Fourier transform of the signal. If that sounds confusing, don’t worry - it’s not necessary to understand for the purposes of generating transcriptions! The important thing to know is that MFCCs are a low dimensional representation of an audio signal that are inspired by human auditory processing .
There is a configuration file that we use when we are generating MFCCs, located in ./conf/mfcc_hires.conf. The only thing we need to know from a practical standpoint is that we must modify this file to list the proper sample rate for our input .wav file . We do this automatically as follows:
First, we call a subprocess which opens a bash shell and uses sox to get the audio information of the .wav file. Then, we perform string manipulation to isolate the sample rate of the .wav file.
Next, we open and read the MFCC configuration file so that we can modify it
And identify the line that sets the sample frequency and isolate it.
Next, we reformat this line to list the sample rate of our .wav file as identified by the soxi command.
Finally, we replace the relevant line in the lines list, collapse this list back into a string, and then write this string to the MFCC configuration file.
Feature Extraction
Now we can get started processing our audio file. First, we open a file for logging our bash outputs, which we will use for every bash command going forward. Then, we copy our .wav file into the ./data/test directory, and then copy the whole ./data/test directory into a new directory (./data/test_hires) for processing.
Next, we generate MFCC features using our data and the configuration file we previously modified.
More information about the arguments of the bash command can be found here:
- steps/make_mfcc.sh : specifies the location of the shell script which generates mfccs
- --nj 1 : specifies the number of jobs to run with. If you have a multi-core machine, you can increase this number
- --mfcc-config conf/mfcc_hires.conf : specifies the location of the configuration file we previously modified
- data/test_hires : specifies the data folder containing the relevant data we will operate on
This command generates the conf , data , and log directories as well as the feats.scp , frame_shift , utt2dur , and utt2num_frames files (all within the data/test_hires directory)
After this, we compute the cepstral mean and variance normalization ( CMVN ) statistics on the data, which minimizes the distortion caused by noise contamination. That is, CMVN helps make our ASR system more robust against noise.
Finally, we use the fix_data_dir.sh shell script to ensure that the files within the data directory are properly sorted and filtered, and also to create a data backup in data/test_hires/.backup .
Pre-trained Model Download and Extraction
Now that we have performed MFCC feature extraction and CMVN normalization, we need a model to pass the data through. In this case we will be using the Librispeech ASR Model , found in Kaldi’s pre-trained model library , which was trained on the LibriSpeech dataset. This model is composed of four submodels:
- An i-vector extractor
- A TDNN-F based chain model
- A small trigram language model
- An LSTM-based model for rescoring
To download these models, we first check to see if these tarballs are already in our directory. If they are not, we download them using wget
and extract them using tar .
This creates the exp/nnet3_cleaned , exp/chain_cleaned , data/lang_test_tgsmall , and exp/rnnlm_lstm_1a directories.
- nnet3_cleaned is the i-vector extractor directory
- chain_cleaned is the chain model directory
- tgsmall is the small trigram language model directory
- and rnnlm is the LSTM-based rescoring model
If the wget process is interrupted during download, you will run into errors downstream. In this case, run the below in terminal to delete any model tarballs that are there and completely reset the directory. We call reset_directory.py rather than reset_directory_completely.py by default so we don't have to download the models (~430 MB compressed) each time we run main.py .
Decoding Generation
Extracting i-vectors.
Next up, we’ll extract i-vectors, which are used to identify different speakers. Even though we have only one speaker in this case, we extract i-vectors anyway for the general use case, and because they are expected downstream.
We create a directory to store the i-vectors and then run a bash command to extract them:
- steps/online/nnet2/extract_ivectors_online.sh : specifies the location of the shell script which extracts the i-vectors
- data/test_hires : specifies the location of the data directory
- exp/nnet3_cleaned/extractor : specifies the location of the extractor directory
- exp/nnet3_cleaned/ivectors_test_hires : specifies the location to store the i-vectors
Constructing the Decoding Graph
In order to get our transcription, we need to pass our data through the decoding graph . In our case, we will construct a fully-expanded decoding graph ( HCLG ) that represents the language model, lexicon (pronunciation dictionary), context-dependency, and HMM structure in the model.
The output of the decoding graph is a Finite State Transducer that has word-ids on the output, and transition-ids on the input (the indices that resolve to pdf-ids)
HCLG stands for a composition of functions, where
- H contains HMM definitions, whose inputs are transition-ids and outputs are context-dependent phones
- C is the context-dependency, that takes in context-dependent phones and outputs phones
- L is the lexicon, which takes in phones and outputs words
- and G is an acceptor that encodes the grammar or language model, which both takes in and outputs words
The end result is our decoding , in this case a transcription of our single utterance.
Before we can pass our data through the decoding graph, we need to construct it. We create a directory to store the graph, and then construct it with the following command.
- utils/mkgraph.sh : specifies the location of the shell script which constructs the decoding graph
- --self-loop-scale 1.0 : Scales self-loops by the specified value relative to the language model 1
- --remove-oov : remove out-of-vocabulary (oov) words
- data/lang_test_tgsmall : specifies the location of the language directory
- exp/chain_cleaned/tdnn_1d_sp : specifies the location of the model directory
- exp/chain_cleaned/tdnn_1d_sp/graph_tgsmall : specifies the location to store the constructed graph
Decoding using the Generated Graph
Now that we have constructed our decoding graph, we can finally use it to generate our transcription!
First we create a directory to store the decoding information, and then decode using the following command.
- steps/nnet3/decode.sh : specifies the location of the shell script which runs the decoding
- --acwt 1.0 : Sets the acoustic scale. The default is 0.1, but this is not suitable for chain models 2
- --post-decode-acwt 10.0 : Scales the acoustics by 10 so that the regular scoring script works (necessary for chain models)
- --online-ivector-dir exp/nnet3_cleaned/ivectors_test_hires : specifies the i-vector directory
- exp/chain_cleaned/tdnn_1d_sp/graph_tgsmall : specifies the location of the graph directory
- exp/chain_cleaned/tdnn_1d_sp/decode_test_tgsmall : specifies the location to store the decoding information
Transcription Retrieval
It’s time to retrieve our transcription! The transcription lattice is stored as a GNU zip file in the decode_test_tgsmall directory, among other files (including word-error rates if you have input a Kaldi text file).
We store the directory paths of our zip file and graph word.txt file, and then pass these into a command variable which stores our bash command. This command unzips our zip file, and then writes the optimal path through the lattice (the transcription) to a file called out.txt in our s5 directory.
- ../../../src/latbin/lattice-best-path : specifies the location of the file which navigates the lattice to generate the decoding
- ark:'gunzip -c {0} |' : pipes the command to unzip the lattice file to shell via popen() 3
- 'ark,t:| utils/int2sym.pl -f 2- {1} > out.txt' : writes the decoding to out.txt 4
Let’s take a look at how our generated transcription compares to the true transcription!
FOUR SCORE AND SEVEN YEARS AGO OUR FATHERS BROUGHT FORTH ON THIS CONTINENT A NEW NATION CONCEIVED IN LIBERTY AND DEDICATED TO THE PROPOSITION THAT ALL MEN ARE CREATED EQUAL
Transcription:
FOUR SCORE AN SEVEN YEARS AGO OUR FATHERS BROUGHT FORTH UND IS CONTINENT A NEW NATION CONCEIVED A LIBERTY A DEDICATED TO THE PROPOSITION THAT ALL MEN ARE CREATED EQUAL
Out of 30 words we had 5 errors, yielding a word error rate of about 17%.
Rescoring with LSTM-based Model
We can rescore with the LSTM-based model using the below command:
- ../../../scripts/rnnlm/lmrescore_pruned.sh : specifies the location of the shell script which runs the rescoring 5
- --weight 0.45 : specifies the interpolation weight for the RNNLM
- --max-ngram-order 4 : approximates the lattice-rescoring by merging histories in the lattice if they share the same ngram history which prevents the lattice from exploding exponentially
- data/lang_test_tgsmall : specifies the old language model directory
- exp/rnnlm_lstm_1a : specifies the RNN language model directory
- data/test_hires : specifies the data directory
- exp/chain_cleaned/tdnn_1d_sp/decode_test_tgsmall : specifies the input decoding directory
- exp/chain_cleaned/tdnn_1d_sp/decode_test_rescore : specifies the output decoding directory
We again output the transcription to a .txt file, in this case called out_rescore.txt :
In our case, rescoring did not change our generated transcription, but it may improve yours!
Advanced Kaldi Speech Recognition
Hopefully this tutorial gave you an understanding of the Kaldi basics and a jumping off point for more complicated NLP tasks! We just used a single utterance and a single .wav file, but we might also consider cases where we want to do speaker identification, audio alignment, or more.
You can also go beyond using pre-trained models with Kaldi. For example, if you have data to train your own model, you could make your own end-to-end system, or integrate a custom acoustic model into a system that uses a pre-trained language model. Whatever your goals, you can use the building blocks identified in this article to help you get started!
There are a ton of different ways to process audio to extract useful information, and each way offers its own subfield rich with task-specific knowledge and a history of creative approaches. If you want to dive deeper into Kaldi to build your own complicated NLP systems, you can check out the Kaldi documentation here .
Cloud Speech-to-Text APIs
Kaldi is a very powerful and well-maintained framework for NLP applications, but it’s not designed for the casual user. It can take a long time to understand how Kaldi operates under the hood, an understanding that is necessary to put it to proper use.
In this vein, Kaldi is consequently not designed for plug-and-play speech processing applications. This can pose difficulties for those who don’t have the time or know-how to customize and train NLP models, but who want to implement speech recognition in larger applications.
If you want to get high quality transcripts in just a few lines of code, AssemblyAI offers a fast, accurate, and easy-to-use Speech-to-Text API . You can sign up for a free API token here and gain access to state-of-the-art models that provide:
- Asynchronous Speech-to-Text
- Real-Time Speech-to-Text
- Summarization
- Emotion Detection
- Sentiment Analysis
- Topic Detection
- Content Moderation
- Entity Detection
- PII Redaction
- And much more!
Grab a token and check out the AssemblyAI docs to get started.
1) Link to "Scaling of transition of acoustic probabilities" in the Kaldi documentation
2) Link to "Decoding with 'chain' models" in the Kaldi documentation
3) Link to "Extended filenames: rxfilenames and wxfilenames" in the Kaldi documentation
4) Link to "Table I/O" in the Kaldi documentation
5) Link to the lmrescore_pruned.sh script in the Kaldi ASR GitHub repo
6) For other beginner resources on getting started with Kaldi, check out this , this , or this resource. Elements from these sources have been adapted for use within this article.
Popular posts

AI trends in 2024: Graph Neural Networks

AI for Universal Audio Understanding: Qwen-Audio Explained

Combining Speech Recognition and Diarization in one model

How DALL-E 2 Actually Works

- Download
- Documentation
- Get involved
- Forum
- File a Bug
Developer Blogs
- Simon 0.4.90 beta released
- Simon 0.4.80 alpha released
- New life in Simon speech recognition
- Simon on OS X
- Open Academy
Suramya's Blog : Welcome to my crazy life…
January 21, 2022, nerd-dictation: a fantastic open source speech to text software for linux.
After a long time of searching I finally found a speech to text software for Linux that actually works well enough that I can use it for dictating without having to jump through too many hoops to configure and use. The software is called nerd-dictation and is an open source software. It is fairly easy to setup as compared to the other voice-to-text systems that are available but still not at a stage where a non-tech savvy person would be able to install it easily. (There is effort ongoing to fix that)
The steps to install are fairly simple and documented below for reference:
- pip3 install vosk
- git clone https://github.com/ideasman42/nerd-dictation.git
- cd nerd-dictation
- wget https://alphacephei.com/kaldi/models/vosk-model-small-en-us-0.15.zip
- unzip vosk-model-small-en-us-0.15.zip
- mv vosk-model-small-en-us-0.15 model
nerd-dictation allows you to dictate text into any software or editor which is open so I can dictate into a word document or a blog post or even the command prompt. Previously I have used tried using software like otter.ai which actually works quite well but doesn’t allow you to edit the text as you’re typing, so you basically dictate the whole thing and the system gives you the transcription after you are done. So, you have to go back and edit/correct the transcript which can be a pain for long dictations. This software works more like Microsoft dictate which is built into Word. Unfortunately my word install on Linux using Crossover doesn’t allow me to use the built in dictate function and I have no desire to boot into windows just so that I can dictate a document.
This downloads the software in the current directory. I set it up on /usr/local but it is up to you where you want it. In addition, I would recommend that you install one of the larger dictionaries/models which makes the voice recognition a lot more accurate. However, do keep in mind that the larger models use up a lot more memory so you need to ensure that your computer has enough memory to support the larger models. The smaller ones can run on systems as small as a raspberry pi, so depending on your system configuration you can choose. The models are available here .
The software does have some quirks, like when you are talking and you pause it will take it as a start of a new sentence and for some reason it doesn’t put a space after the last word. So unless you’re careful you need to go back and add spaces to all the sentences that you have dictated, which can get annoying. (I started manually pressing space everytime I paused to add the space). Another issue is that it doesn’t automatically capitalize the words when you dictate such as those at the beginning of the sentence or the word ‘I’. This requires you to go back and edit, but that being said it still works a lot better than the other software that I have used so far on Linux. For Windows system Dragon Voice Dictation works quite well but is expensive. I tested it out by typing out this post using it and for the most part it does work it worked quite well.
Running the software again requires you to run commands on the commandline, but I configured shortcut keys to start and stop the dictation which makes it very convenient to use. Instructions on how to configure custom shortcut keys are available here . If you don’t want to do that, then you can start the transcription by issuing the following command (assuming the software is installed in /usr/local/nerd-dictation):
This starts the software and tells it that we are going to dictate for a long time. More details on the options available are available on the project site. To stop the software you should run the following command:
I suggest you try this if you are looking for a speech-to-text software for Linux. Well this is all for now. Will post more later.
Thanks to Hacker News: Nerd-dictation, hackable speech to text on Linux for the link.
– Suramya
No Comments »
No comments yet.
RSS feed for comments on this post. TrackBack URL
Leave a comment
Name (required)
Mail (will not be published) (required)
XHTML: You can use these tags: <a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>
- Article Releases
- Astronomy / Space
- Reviews-Fantasy
- Reviews-Paranormal
- Reviews-Romance
- Reviews-Science Fiction
- Reviews-Thriller
- Reviews-Urban Fantasy
- Reviews-Young Adult Fantasy
- Computer Hardware
- Security Tools
- Security Tutorials
- Computer Software
- Computer Tips
- Artificial Intelligence
- Quantum Computing
- General/News
- Interesting Sites
- Knowledgebase
- Linux/Unix Related
- My Thoughts
- Computer Related
- Science Related
- Tech Related
- Travel/Trips
- Uncategorized
- Website Updates
- Search for:
- Suramya on Fixing problems with nvidia-driver on Debian Unstable after latest upgrade : “ @asd, I am running the Unstable branch, which is what is used to perform the E2E testing that you are… ” Apr 1, 14:59
- asd on Fixing problems with nvidia-driver on Debian Unstable after latest upgrade : “ It shouldn’t happen in the first place, this software should’ve been extensively unit and E2E tested by a large team… ” Mar 30, 02:25
- pelorustech on Internet of Things (IoT) Forensics: Challenges and Approaches : “ This insightful blog on IoT forensics is a gem! Your in-depth exploration of challenges and approaches is truly commendable. It’s… ” Aug 30, 16:07
- Abhishek on My Trip to Gujarat : “ Very nice post with beautiful pictures!!! ” May 23, 17:16
- February 2024
- January 2024
- December 2023
- November 2023
- October 2023
- September 2023
- August 2023
- February 2023
- January 2023
- December 2022
- November 2022
- October 2022
- September 2022
- August 2022
- January 2022
- September 2021
- August 2021
- February 2021
- January 2021
- November 2020
- October 2020
- September 2020
- August 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- January 2019
- September 2018
- August 2018
- February 2018
- January 2018
- December 2017
- October 2017
- September 2016
- February 2016
- January 2016
- October 2015
- September 2015
- August 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- February 2013
- November 2012
- October 2012
- August 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- December 2010
- October 2010
- September 2010
- August 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- February 2009
- January 2009
- December 2008
- November 2008
- October 2008
- September 2008
- August 2008
- February 2008
- January 2008
- December 2007
- November 2007
- October 2007
- September 2007
- August 2007
- February 2007
- January 2007
- December 2006
- November 2006
- October 2006
- September 2006
- August 2006
- February 2006
- January 2006
- December 2005
- November 2005
- October 2005
- September 2005
- August 2005
- February 2005
- January 2005
- December 2004
- November 2004
- October 2004
- Entries feed
- Comments feed
- WordPress.org
Powered by WordPress
Ubuntu Speech-to-Text Tutorial
We love Ubuntu at Picovoice. Our standard dev machines are running Ubuntu. No offence to macOS and Windows fans 😉
Today you can run Ubuntu on a single-board computer (SBC) like Raspberry Pi, NVIDIA Jetson, or BeagleBone. At the same time, one can have it on a server or a desktop. Below we look at options for running Speech-to-Text on an Ubuntu machine. Then we dive deeper into how to run Picovoice Leopard Speech-to-Text Engine on Ubuntu.
Speech-to-Text on Ubuntu
You can use any API: Google Speech-to-Text, Amazon Transcribe, IBM Watson Speech-to-Text, or Azure Cognitive Services Speech-to-Text. The downside? They are pretty expensive for anything other than a proof of concept but are relatively accurate. Additionally, you need to send raw audio data to the cloud, which means extra power consumption and bandwidth cost. The latter is only a concern if you are on a cellular connection.
Alternatively, you can use free and open-source (FOSS) software. Kaldi (derivations of such as Vosk), Mozilla DeepSpeech (derivations of such as Coqui), and many more. The upside is that they are free, but the downside is that they hardly match the accuracy of API-based ASRs nor have all the features you might require (e.g. custom words and keyword boosting). If you care about the runtime efficiency, they are not necessarily optimized. These can be good starting points if you decide to build your own.
Picovoice Leopard Speech-to-Text processes voice locally on the device while matching the accuracy of API alternatives from Big Tech. Developers can start transcribing in seconds with Picovoice’s Free Plan , even for commercial projects.
Leopard comes with a total package size of 20MB (compared to GBs of FOSS alternatives). Leopard runtime efficiency enables it to run even on Raspberry Pi 3 using only a quarter of only one of the CPU cores.
Leopard Python SDK
Install Leopard Python package using PIP:
Sign up for Picovoice Console and copy your AccessKey to the clipboard. AccessKey handles authentication and authorization.
Create an instance of Leopard STT and transcribe a file:
Node.js, Rust, Go, Java, .NET, ...
Subscribe to our newsletter
More from Picovoice

Learn how to perform Speech Recognition in JavaScript, including Speech-to-Text, Voice Commands, Wake Word Detection, and Voice Activity Det...

Have you ever thought of getting a summary of a YouTube video by sending a WhatsApp message? Ezzeddin Abdullah built an application that tra...

The launch of Leopard Speech-to-Text and Cheetah Speech-to-Text for streaming brought cloud-level automatic speech recognition (ASR) to loca...

Transcribe speech-to-text in real-time using Picovoice Cheetah Streaming Speech-to-Text React.js SDK. The SDK runs on Linux, macOS, Windows,...

Transcribe speech to text using Picovoice Leopard speech-to-text React.js SDK. The SDK runs on Linux, macOS, Windows, Raspberry Pi, and NVID...

Learn how to create a custom speech-to-text model on the Picovoice Console using the Leopard & Cheetah Speech-to-Text Engines

Add speech-to-text to a Django project using Picovoice Leopard Speech-to-Text Python SDK. The SDK runs on Linux, macOS, Windows, Raspberry P...

Perform keyword spotting on Arm Cortex-M microcontrollers using Picovoice Porcupine Wake Word. Run NLU on MCUs using Picovoice Rhino Speech-...
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
speech-to-text
Here are 2,809 public repositories matching this topic..., ggerganov / whisper.cpp.
Port of OpenAI's Whisper model in C/C++
- Updated Apr 12, 2024
mozilla / DeepSpeech
DeepSpeech is an open source embedded (offline, on-device) speech-to-text engine which can run in real time on devices ranging from a Raspberry Pi 4 to high power GPU servers.
- Updated Feb 18, 2024
leon-ai / leon
🧠 Leon is your open-source personal assistant.
- Updated Feb 25, 2024
kaldi-asr / kaldi
kaldi-asr/kaldi is the official location of the Kaldi project.
- Updated Jan 31, 2024
m-bain / whisperX
WhisperX: Automatic Speech Recognition with Word-level Timestamps (& Diarization)
- Updated Apr 11, 2024
SYSTRAN / faster-whisper
Faster Whisper transcription with CTranslate2
Uberi / speech_recognition
Speech recognition module for Python, supporting several engines and APIs, online and offline.
- Updated Apr 2, 2024
speechbrain / speechbrain
A PyTorch-based Speech Toolkit
nl8590687 / ASRT_SpeechRecognition
A Deep-Learning-Based Chinese Speech Recognition System 基于深度学习的中文语音识别系统
- Updated Jan 16, 2024
alphacep / vosk-api
Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node
- Updated Apr 8, 2024
- Jupyter Notebook
TalAter / annyang
💬 Speech recognition for your site
- Updated Oct 3, 2022
jianchang512 / pyvideotrans
Translate the video from one language to another and add dubbing. 将视频从一种语言翻译为另一种语言,并添加配音
snakers4 / silero-models
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple
- Updated Oct 18, 2023
sanchit-gandhi / whisper-jax
JAX implementation of OpenAI's Whisper model for up to 70x speed-up on TPU.
- Updated Apr 3, 2024
tensorflow / lingvo
Toverainc / willow.
Open source, local, and self-hosted Amazon Echo/Google Home competitive Voice Assistant alternative
- Updated Mar 2, 2024
pannous / tensorflow-speech-recognition
🎙Speech recognition using the tensorflow deep learning framework, sequence-to-sequence neural networks
- Updated Jan 17, 2024
coqui-ai / STT
🐸STT - The deep learning toolkit for Speech-to-Text. Training and deploying STT models has never been so easy.
- Updated Mar 11, 2024
MahmoudAshraf97 / whisper-diarization
Automatic Speech Recognition with Speaker Diarization based on OpenAI Whisper
- Updated Mar 12, 2024
mesolitica / NLP-Models-Tensorflow
Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 < Tensorflow < 2.0
- Updated Jul 20, 2020
Improve this page
Add a description, image, and links to the speech-to-text topic page so that developers can more easily learn about it.
Curate this topic
Add this topic to your repo
To associate your repository with the speech-to-text topic, visit your repo's landing page and select "manage topics."
Command-line tools for speech and intent recognition on Linux
voice2json is a collection of command-line tools for offline speech/intent recognition on Linux. It is free, open source ( MIT ), and supports 18 human languages .
Getting Started
- Data Formats
- Node-RED Plugin
From the command-line:
produces a JSON event like:
when trained with this template :
Tools like Node-RED can be easily integrated with voice2json through MQTT .
voice2json is optimized for :
- Sets of voice commands that are described well by a grammar
- Commands with uncommon words or pronunciations
- Commands or intents that can vary at runtime
It can be used to:
- Add voice commands to existing applications or Unix-style workflows
- Provide basic voice assistant functionality completely offline on modest hardware
- Bootstrap more sophisticated speech/intent recognition systems
Supported speech to text systems include:
- CMU’s pocketsphinx
- Dan Povey’s Kaldi
- Mozilla’s DeepSpeech 0.9
- Kyoto University’s Julius
- Install voice2json
- Your profile settings will be in $HOME/.local/share/voice2json/<PROFILE>/profile.yml
- Edit sentences.ini in your profile and add your custom voice commands
- Train your profile
- See the recipes for more possibilities
Supported Languages
voice2json supports the following languages/locales. I don’t speak or write any language besides U.S. English very well, so please let me know if any profile is broken or could be improved! I’m mostly Chinese Room-ing it .
- ca-es_pocketsphinx-cmu
- cs-cz_kaldi-rhasspy
- de_deepspeech-aashishag
- de_deepspeech-jaco
- de_kaldi-zamia (default)
- de_pocketsphinx-cmu
- el-gr_pocketsphinx-cmu
- en-in_pocketsphinx-cmu
- en-us_deepspeech-mozilla
- en-us_kaldi-rhasspy
- en-us_kaldi-zamia (default)
- en-us_pocketsphinx-cmu
- es_deepspeech-jaco
- es_kaldi-rhasspy (default)
- es-mexican_pocketsphinx-cmu
- es_pocketsphinx-cmu
- fr_deepspeech-jaco
- fr_kaldi-guyot (default)
- fr_kaldi-rhasspy
- fr_pocketsphinx-cmu
- hi_pocketsphinx-cmu
- it_deepspeech-jaco
- it_deepspeech-mozillaitalia (default)
- it_kaldi-rhasspy
- it_pocketsphinx-cmu
- ko-kr_kaldi-montreal
- kz_pocketsphinx-cmu
- nl_kaldi-cgn (default)
- nl_kaldi-rhasspy
- nl_pocketsphinx-cmu
- pl_deepspeech-jaco (default)
- pl_julius-github
- pt-br_pocketsphinx-cmu
- ru_kaldi-rhasspy (default)
- ru_pocketsphinx-cmu
- sv_kaldi-montreal
- sv_kaldi-rhasspy (default)
- vi_kaldi-montreal
- zh-cn_pocketsphinx-cmu
Unique Features
voice2json is more than just a wrapper around pocketsphinx , Kaldi , DeepSpeech , and Julius !
- Training produces both a speech and intent recognizer. By describing your voice commands with voice2json ’s templating language , you get more than just transcriptions for free.
- Re-training is fast enough to be done at runtime (usually < 5s), even up to millions of possible voice commands . This means you can change referenced slot values or add/remove intents on the fly.
- All of the available commands are designed to work well in Unix pipelines , typically consuming/emitting plaintext or newline-delimited JSON . Audio input/output is file-based , so you can receive audio from any source .
How it Works
voice2json needs a description of the voice commands you want to be recognized in a file named sentences.ini . This can be as simple as a listing of [Intents] and sentences:
A small templating language is available to describe sets of valid voice commands, with [optional words] , (alternative | choices) , and <shared rules> . Portions of (commands can be){annotated} as containing slot values that you want in the recognized JSON.
When trained , voice2json will transform audio data into JSON objects with the recognized intent and slots .
Assumptions
voice2json is designed to work under the following assumptions:
- Speech can be segmented into voice commands by a wake word + silence , or via a push-to-talk mechanism
- A voice commands contains at most one intent
- Intents and slot values are equally likely
Why Not That
Why not just use Google , Dragon , or something else?
Cloud-based speech and intent recognition services, such as Google Assistant or Amazon’s Alexa, require a constant Internet connection to function. Additionally, they keep a copy of everything you say on their servers. Despite the high accuracy and deep integration with other services, this approach is too brittle and uncomfortable for me.
Dragon Naturally Speaking offers local installations and offline functionality. Great! Unfortunately, Dragon requires Microsoft Windows to function. It is possible to use Dragon in Wine on Linux or via a virtual machine, but is difficult to set up and not officially supported by Nuance .
Until relatively recently, Snips offered an impressive amount of functionality offline and was easy to interoperate with . Unfortunately, they were purchased by Sonos and have since shut down their online services (required to change your Snips assistants). See Rhasspy if you are looking for a Snips replacement, and avoid investing time and effort in a platform you cannot control!
If you feel comfortable sending your voice commands through the Internet for someone else to process, or are not comfortable with Linux and the command line, I recommend taking a look at Mycroft .
No Magic, No Surprises
voice2json is not an A.I. or gee-whizzy machine learning system. It does not attempt to guess what you want to do, and keeps everything on your local machine. There is no online account sign-up needed, no privacy policy to review, and no advertisements. All generated artifacts are in standard data formats ; typically just text.
Once you’ve installed voice2json and downloaded a profile , there is no longer a need for an Internet connection. At runtime, voice2json will only every write to your profile directory or the system’s temporary directory ( /tmp ).
Contributing
Community contributions are welcomed! There are many different ways to contribute:
- Pull requests for bug fixes, new features, or corrections to the documentation
- Testing to make sure the acoustic models and default pronunciation dictionaries are working
- Translations of the example voice commands
- Example WAV files of you speaking with text transcriptions for performance testing
- Contributing to Mozilla Common Voice
- Assist other voice2json community members
- Implement or critique one of my crazy ideas
Here are some ideas I have for making voice2json better that I don’t have time to implement.
Yet Another Wake Word Library
Porcupine is the best free wake word library I’ve found to date, but it has two major limitations for me:
- I can’t build it for architecture that aren’t currently supported
- I can’t include custom wake words in pre-built packages/images
Picovoice has been very generous to release porcupine for free, so I’m not suggesting they change anything. Instead, I’d love to see a free and open source wake word library that has these features:
- Free and completely open source
- Performance close to porcupine or snowboy
- Able to run on a Raspberry Pi alongside other software (no 100% CPU usage)
- Can add custom wake words without hours of training
Mycroft Precise comes close, but requires a lot of expertise and time to train custom wake words. It’s performance is also unfortunately poorer than porcupine (in my limited experience).
I’ve wondered if Mycroft Precise’s approach ( a GRU ) could be extended to include Pocketsphinx’s keyword search mode as an input feature during training and at runtime. On it’s own, Pocketsphinx’s performance as a wake word detector is abysmal . But perhaps as one of several features in a neural network, it could help more than hurt.
Acoustic Models From Audiobooks
The paper LibriSpeech: An ASR Corpus Based on Public Domain Audio Books describes a method for taking free audio books from LibriVox and training acoustic models from it using Kaldi . For languages besides English, this may be a way of getting around the lack of free transcribed audio datasets! Although not ideal, it’s better than nothing.
For some languages, the audiobook approach may be especially useful with end-to-end machine learning approaches, like Mozilla’s DeepSpeech and Facebook’s wav2letter . Typical approaches to building acoustic models require the identification of a language’s phonemes and the construction of a large pronunciation dictionary . End-to-end approaches go directly from acoustic features to graphemes (letters), subsuming the phonetic dictionary step. More data is required, of course, but books tend to be quite long.
Android Support
voice2json uses pocketsphinx , Kaldi , and Julius for speech recognition. All of these libraries have at least a proof-of-concept Android build:
- Pocketsphinx on Android
- Compile Kaldi for Android
- Julius on Android
It seems feasible that voice2json could be ported to Android, providing decent offline mobile speech/intent recognition.
Browser-Based voice2json
Could empscripten be used to compile WebAssembly versions of voice2json ’s dependencies? Combined with something like pyodide , it might be possible to run (most of) voice2json entirely in a modern web browser.
Stack Exchange Network
Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Convert speech (mp3 audio files) to text
I am looking for simple converter from mp3 to txt. I have tried, without success: julius, CMU Sphinx, ... In the past 4 hours I did not find a way how to use them (or properly install them).
What I am looking for is something like:
I am also fine with GUI application since I only have a few files to convert and can click around.
Edit: With the help of this answer Speech-recognition app to convert MP3 to text? I manged to get it working but it produces no output. Well, actually it produces a couple of blank lines (no words detected)...
- software-recommendation
- speech-recognition
- What is the exact command you run and the output you see? – Nikolay Shmyrev Oct 15, 2016 at 16:56
- 1 $ pocketsphinx_continuous -infile 1.wav -hmm en-us/cmusphinx-en-us-5.2 -lm en-us/en-70k-0.2.lm -logfn /dev/null &>otput.txt is the exact command as per @NikolayShmyrev question. I have downloaded the models from sourceforge.net/projects/cmusphinx/files/… . – Samo Oct 17, 2016 at 12:09
3 Answers 3
pocketsphinx will do speech to text from an existing audio file. Depending on the initial format of the mp3, you may need two separate commands.
First convert your existing audio file to the mandatory input format:
The run pocketsphinx
the created file myspeech.txt will have what you're looking for.
In case you are new to ubuntu, you would need to install the above programs using this command:
- 1 Funny how pocketsphinx-en-us isn't a dependency or even not having it installed doesn't generate an error when executing. – Adam Jun 23, 2020 at 20:15
OpenAI's Whisper (link to press release ) is a relatively new free and open-source alternative, with pretty good performance in multiple languages.
There are a few ways to install it, you can do so via pip , python's package manager: pip install -U openai-whisper
A comment below points out that the use of a python "virtual environment" may be suggested. This is a way for python's pip to install software in a subdirectory, therefore not impacting the rest of your system:
- This sounds like a great answer, but I think it can be improved. Typing pip install -U openai-whisper gives some error message about this being an external environment and requiring a virtual environment, blah blah, lots of things that are incomprehensible unless you're an experienced Python developer. – k314159 Mar 26 at 15:30
- 1 @k314159 It didn't display this for me last time I tried it, but I added a short tutorial to my answer instead of leaving that in my previous comment (which I am deleting). – MayeulC Mar 27 at 15:16
- 1 Thanks, that looks good. Another way to install whisper, which I tried successfully yesterday, is to use pipx . – k314159 Mar 27 at 15:25
Mozilla SpeechDeep opensource speech-to-text tool will do. You will need to install the application on your linux desktop. Or you can try Transcribear a browser based speech-to-text tool that does not require installation, but you will need to be connected online to upload the recording to the server.
You must log in to answer this question.
Not the answer you're looking for browse other questions tagged software-recommendation speech-recognition ..
- The Overflow Blog
- Climbing the GenAI decision tree sponsored post
- Diverting more backdoor disasters
- Featured on Meta
- New Focus Styles & Updated Styling for Button Groups
- Upcoming initiatives on Stack Overflow and across the Stack Exchange network
- AI-generated content is not permitted on Ask Ubuntu
- Let's organize some chat workshops
Hot Network Questions
- Why do self cleaning windows use titanium dioxide (specifically in nanoparticle form)?
- Haste creature under The Akroan War chapter 2 ability
- Possibility of using a heat pump to exchange cool air from a ground floor with third floor room
- Novella about man reminiscing about his girlfriend/wife while standing by her dead body
- People who frequently travel in planes are called…?
- PNP transistor not pulling up completely : what is wrong in my schematic?
- How do we measure the position of a body?
- Replicate a "thermometer" with color gradient
- Does value of a TRS only involve past price movement and not expected returns?
- To what extent can citizens of democracies be held responsible for the acts of their governments?
- Does a homeomorphism preserve the open sets?
- What is a safe way to transport an e-bike battery on planes?
- Beginner: Solder won’t flow onto thermostat tabs
- FizzFizzFizzBuzz!
- Philosophy - is there any point exploring?
- Number of ways in which 5 girls and 5 boys can be arranged in a line such that only 4 girls stand adjacent to one another
- "Pure Imaginary" or "Purely Imaginary"?
- What is a word for battery "longevity"?
- Is there any difference between a heavy meal and a large meal, between a light meal and a small meal?
- How to say politely not to doze off during progress meeting?
- Differences Between `/dev/null` and Devices Under `null_blk` Driver
- Problem with ST_Difference in PostGIS
- What were the major things that caused TCP/IP to become the internet standard protocol?
- Did Goethe say this quote praising the Prophet Muhammed?

Speech Note Transcribes Voice to Text on Linux
- Posted by by Scott Bouvier
- August 28, 2023
Speech Note is an offline, AI-powered app able to transcribe your speech into text in a variety of different languages.
A reader got in touch to point me towards the app — thanks, David! — and given that it sounds pretty cool I figured I’d give it a spotlight on the site.
Speech Note use OpenAI’s Whisper and a stack of other open-source libraries, voice engines, and other doohickeys to perform its transliterative magic.
It supports Speech to Text (i.e you speak, it types), Text to Speech (i.e. you type, it speaks), and machine translation to translate text/speech from one language to another.

“Text and voice processing take place entirely offline, locally on your computer, without using a network connection. Your privacy is always respected. No data is sent to the Internet,” assures the application’s Flathub listing.
Those with a supported GPU will want to turn GPU acceleration on as will hugely improve processing times (which are on the slow side if only using CPU processing).
Speech Note is a 620MB download from Flathub (excluding any runtimes or platforms required) and takes up around ~2GB when installed – if you’re data or disk constrained, do keep those factors in mind.
• Get Speech Note on Flathub
Home > Apps > Speech Note Transcribes Voice to Text on Linux

Scott Bouvier
An international man of mystery, Scott enjoys personal computing, mobile technology, and outdoor pursuits. He once went wing-walking on a biplane over London – scary, huh?
Linux and Dev Portal
Speech Recognition to Text in Linux, Ubuntu using Google Docs

This is how you can convert speech to text in Linux systems, including Ubuntu.
There is not much speech recognition software available in Linux systems, including native desktop apps. There are some apps available that use IBM Watson and other APIs to convert speech to text, but they are not user-friendly and require an advanced level of user interactions, e.g. a little bit of programming or scripting in respective languages.
However, not many users know that Google Docs provides an advanced level of Speech Recognition using its own AI technologies, which can be accessed via Chrome in Google Docs.
Any user can use this feature to convert speech to text, requiring no advanced level of computer knowledge. The best thing about this feature of Google Docs is you can use it in any Ubuntu derivatives or any Linux distribution where Chrome is available.
Let’s take a look at how you can enable it in Ubuntu.
Table of Contents
How to convert speech to text
The prerequisites are having Chrome installed in your system and a Google account. You can visit this page for the Chrome installation guide if you don’t have Chrome installed.
Also, if you don’t have a Google account, you can create one using this link for free.
Step 1: Open Google Docs
Open https://docs.google.com from Chrome and create a blank document.

Step 2: Launch Voice Typing
After the blank document is loaded, click Tools > Voice typing from the menu.

Step 3: Click on speak button
On the left-hand side, you can see a microphone icon. Click the microphone icon. Google Chrome will ask for microphone permission first time. Hit Allow to give access.

By default, it uses your system language as the detecting language of voice while converting it into the text; however, you can change it to any language you want per the available list of languages. So far, more than 60+ languages are supported and recognized in Google Docs while converting them to text.
Step 4: Speak and record
After you click allow, the microphone icon will turn orange, and now it’s ready to accept or recognize your voice. Start speaking anything you want, and voila! You will see your speech is being converted to text and written in the document.

That’s it. You have successfully converted voice to text in Ubuntu via Google Chrome and Google docs.
This amazing feature is available for all Linux users for free. Drop a comment below using the comment box if you are aware of other apps that can convert voice to text in Linux. Also, let me know whether you found this helpful article.
Troubleshooting
1. If the above feature is not working in your browser, make sure to check out the following.
- Open the Settings window (in GNOME desktop in Ubuntu or another distro).
- Go to Privacy > Microphone .
- And make sure it’s enabled.

2. Since many users reported about problem with the above method in Linux Mint, I have tried and it works perfectly in Linux Mint (Tried in 21). However, you need to change sound settings, because for some reason Linux Mint input mic sound is muted by default!
- Open “Sound” from the menu.
- Then go to “Input” tab. Under device settings, increase the volume to 100% to louder.

- Close the window and it will now work in Linux Mint.
Wrapping Up
Although, there is a cloud-based solution available recently, such as Amazon Polly and others. But they come with a steep price. Plus requires a bit of useful knowledge as well.
Whereas Google Chrome’s built-in speech recognition feature is simple and easy to use. It can get the job done for average users, although it’s a little slow.
That said, I hope this guide helps you to convert voice to text and do let me know in the comment box if you know of such an application which does the same for free.
Share this:

Posted by Arindam

This site uses Akismet to reduce spam. Learn how your comment data is processed .
forgot password
eSpeak: Text To Speech Tool For Linux

eSpeak is a command line tool for Linux that converts text to speech. This compact speech synthesizer provides support for English and many other languages. It is written in C.
eSpeak reads the text from the standard input or input file. The voice generated, however, is nowhere close to a human voice. But it is still a compact and handy tool if you want to use it in your projects.
Some of the main features of eSpeak are:
- Speaks text from a file or from stdin
- Shared library version to be used by other programs
- SAPI5 version for Windows, so it can be used with screen-readers and other programs that support the Windows SAPI5 interface
- Ported to other platforms, including Android, Mac OSX etc.
- Several voice characteristics to choose from
- Speech output can be saved as .WAV file
- SSML ( Speech Synthesis Markup Language ) is supported partially along with HTML
- Uses a “formant synthesis” method. This allows many languages to be provided in a small size.
- Tiny in size, the complete program with language support, etc is under 2 MB.
- Can translate text into phoneme codes so that it could be adapted as a front end for another speech synthesis engine.
- Development tools are available for producing and tuning phoneme data
- Supports several languages; however, in many cases these are initial drafts and need more work
Install eSpeak
To install eSpeak in Ubuntu based system, use the command below in a terminal:
eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Fedora. You can install eSpeak easily using the respective package manager. I
n case of Arch Linux, the repository has espeak-ng in place, which is described in the next section.
To use eSpeak, enter espeak in the terminal. It waits for input. You can start typing your text. When you press enter (new line), you can hear the text you had entered.
You can continue adding text in lines to hear it out. Use Ctrl+C to close the running program .

There are several other options available. You can browse through them through the help section of the program.

GUI Version: espeakedit
If you prefer the GUI version over the command line, you can install espeakedit which provides a GTK front end to eSpeak.
Use the command below to install espeakedit:
Once installed, you need to copy the data on /usr/lib/x86_64-linux-gnu/espeak-data/ to your home directory. For this, open a terminal and run:
Once done, you can open the espeakedit application. It will look like:

You can enter the text on the field provided and press speak to start. You can save the file as .WAV file and listen later.
The interface is straightforward and easy to use. You can explore the submenus and functions all by yourself.
A New Tool: eSpeak NG
The eSpeak NG is a compact open-source text-to-speech synthesizer, based on eSpeak engine created by Jonathan Duddington.
It offers the features of eSpeak and is in active development. The project also provides a separate espeak-ng-data package, to avoid conflict with the espeak-data package offered by eSpeak project.
To install this, on Ubuntu, run:
The new eSpeak NG project is a significant departure from the eSpeak project, aiming to clean up the existing codebase, add new features, and add to and improve the supported languages.
Also, it is important to note that espeakedit GUI is not part of this new project.
Some of the notable features:
- Uses the same command-line options as espeak with several additions.
- Provides new functionality such as specifying the output audio device name to use.
- Has been ported to other platforms, including Solaris and Mac OSX.
- Includes different voices whose characteristics can be altered.
- Available as a command-line program for Linux and Windows to speak text from a file or from stdin.
- Available as a shared library version for use by other programs.
Wrapping Up
On It’s FOSS, we use Play.ht to provide audio formats of selected articles. The espeak tools are not as good as the professional AI tools.
However, if you want something basic and free to be used in your project, you can give it a try.
Abhishek Prakash
Created It's FOSS 11 years ago to share my Linux adventures. Have a Master's degree in Engineering and years of IT industry experience. Huge fan of Agatha Christie detective mysteries 🕵️♂️
Meet DebianDog - Puppy sized Debian Linux
Reduce computer eye strain with this nifty tool in linux, install open source dj software mixxx version 2.0 in ubuntu, install adobe lightroom alternative rawtherapee in ubuntu linux, complete guide to installing linux on chromebook, become a better linux user.
With the FOSS Weekly Newsletter, you learn useful Linux tips, discover applications, explore new distros and stay updated with the latest from Linux world

Great! You’ve successfully signed up.
Welcome back! You've successfully signed in.
You've successfully subscribed to It's FOSS.
Your link has expired.
Success! Check your email for magic link to sign-in.
Success! Your billing info has been updated.
Your billing was not updated.
- Trending Blogs
- Geeksforgeeks NEWS
- Geeksforgeeks Blogs
- Tips & Tricks
- Website & Apps
- ChatGPT Blogs
- ChatGPT News
- ChatGPT Tutorial
- How to edit WhatsApp messages on Android and iOS devices
- DragGAN AI Editing Tool : AI powered Image Tool
- Microsoft CEO Raises Important Questions about A.I.'s Impact on Jobs and Education
- Level up your ChatGPT Game with OpenAI's Free Course on Prompt Engineering for Developers
- ChatGPT app for iPhone - How to Download and Use on iOS
- WhatsApp Introduces Chat Lock To Enhance Your Privacy
- Microsoft brings Bing Chat AI Widget to Android and iOS users
- Google to Delete Inactive Accounts Starting December
- Amazon Lays off 500 Employees in India, Tech Layoffs Continue in Q2
- Google Bard Can Now Generate And Debug Code
- 70+ ChatGPT Plugins And Web Browsing Beta Rollout For Plus Users
- ONDC is Destroying Swiggy-Zomato and People are Happy About It!
- AI Could Replace 80% of Jobs in Near Future, Expert Warns
- Warren Buffett Compares AI to Atom Bomb - Shocking Reason Unveiled!
- Gmail Introduces Blue Checkmarks To Boost Email Security
- Discord Removes Four-Digit Numbers from Usernames, Citing User Feedback
- Google Rolls Out New Passkey Login Feature, Says Goodbye to Passwords
- Reddit Launches New Features To Simplify Content Sharing Across Social Media Platforms
- Google Loses "Father of AI" as Geoffrey Hinton Quits Google Over Chatbot Concerns
10 Best Whisper AI Alternatives for Speech-to-Text Services in 2024
Today, performing multilingual transcription, speech translation, and language detection are made easy with AI-powered speech recognition tools. This software’s API (Application Programming Interface) provides the ability to call a service to transcribe audio-containing speech into written text.
One of the most well-known choices among speech recognition tools is Whisper AI. The platform converts spoken language into text and is used as a chatbot, voice assistant, speech translator, and transcriptor. It is also known for automating the process of taking notes during meetings.
With so many features, still, this tool may not be an ideal choice for your organization if your project involves real-time processing of streaming voice data or if you need to train a custom model.
The vast number of speech transcription options can be overwhelming and make it difficult to make an informed choice. This article breaks down the best Whisper AI alternatives , outlining their top features, pros and cons, and pricing. So, let’s check out the ranking of all these leading speech-to-text APIs.
10 Best Whisper AI Alternatives in 2024
Google speech-to-text, microsoft azure, speechmatics, amazon transcribe, what is the best speech-to-text tool in 2024.
Here are some of the best Whisper AI Alternatives for you to look at:

Google Speech-to-Text is provided as a part of the Google Cloud Platform. It processes over 1 billion voices every month and boasts close to the human level of understanding of numerous languages. It enables developers to translate the audio from text by applying robust neural network models in an easy-to-use API.
- It integrates well with Google Drive, Google Meet, Google Docs, etc.
- This platform provides multi-channel recognition
- It is powered by machine learning.
It offers 0-60 minutes/month for free. The premium plan is for Speech Recognition (without data logging – default):
- Standard Plan- $0.024 / minute
- Medical Plan- $0.078 / minute
- Speech Recognition (with data logging opt-in)- $0.016 / minute.
Link: https://cloud.google.com/speech-to-text

Microsoft Azure allows you to translate text swiftly and accurately in over 90 languages. It is one of the most advanced voice-recognition platforms around. The platform uses deep learning algorithms to overcome poor sound quality and adapt to numerous speaking styles to deliver accurate audio transcriptions.
- Its speaker recognition feature allows to recognize who’s speaking in a meeting
- You can customize translations for the organization’s specific terms in a preferred programming language
- Allows you to deploy your endpoint to use in your application.
It offers a free plan. After you use free credits, move to pay as you go to keep using the same services.
Link: https://azure.microsoft.com/en-us/products/ai-services/speech-to-text

AssemblyAI’s speech-to-text APIs enable you to translate audio and video files and live audio streams into text. This tool offers faster transcription speed than public cloud service providers and decent across. It is an all-in-one speech recognition platform built to serve startups, SMBs, SMEs, and agencies.
- Large Language Models, or LLMs, allow the creation of Generative AI tools on top of voice data
- It offers a speech summarization feature
- Quickly detects and monitors sensitive content, such as hate speech
It offers a free plan. The premium plan starts at $0.12/hr.
Link: https://www.assemblyai.com/

Rev AI is one of the best Whisper AI alternatives that offers automated speech-to-text services powered by advanced machine learning algorithms. It is a wonderful option for highly accurate English language use cases that deliver high accuracy when essential text-to-speech software does not.
- It provides online integrations that improve workflow
- The tool generates transcription in real-time
- You can get positive, negative, and neutral statements from the text.
It offers three pay-as-you-go plans:
- Machine Translation: $0.02/minute
- Human Transcription: $1.50/minute
- Forced Alignment: $0.02/minute
- You can also opt for the Enterprise plan which can be customized.
Link: https://www.rev.ai/

Speechmatics is the most accurate and inclusive speech-to-text API engine that provides accurate and flexible solutions. It is one of the leading experts in the field as it combines the best technologies, i.e., AI and ML, to unlock the business value of human speech. Whether you need transcription or translation, the platform provides a solution that can be integrated into your organization without any trouble.
- It offers real-time transcription, translation, and summarization
- It also provides numeral formatting
- The tool includes profanity and disfluency detection.
It offers a free plan. There are two premium plans:
- Pay as you grow- Starts at $0.30/hour
- Enterprise Plan- Contact the sales team.

IBM Watson is one of the best Whisper AI alternatives , enabling fast and accurate transcriptions in various languages. It provides keyword spotting and profanity filtering to filter specific words or inappropriate content. The best thing is that it is deployable on any cloud—public, private, hybrid, multi-cloud, or on-premises.
- It provides an automatic speech recognition option
- Allows you to analyze and correct weak audio signals before transcription starts
- It can detect up to 6 different speakers
The tool offers 30-day free trial. There are 4 paid price plans:
- Plus- Starting at $500
- Enterprise- Starts at $5000
- Premium- Customized (Contact the sales team)
- IBM Cloud Pak for Data Cartridge- Customized (Contact the sales team)
Link : https://www.ibm.com/products/speech-to-text

Kaldi is an excellent speech recognition tool famous in the research community for numerous years. It is highly accurate and allows you to train your own models.
- Supports multiple languages
- It provides real-time streaming support
It is free to use.
Link : https://kaldi-asr.org/

LumenVox is one of the best Whisper AI alternatives , as its flexible speech-enabling technology allows you to create a solution that caters to your specific requirements.
- Accurate speech detection with speech tuning
- Easy implementation for any network architecture
- Accelerated ability to add new languages and dialects
Its free to use.
Link: https://www.lumenvox.com/

Power your apps with real-time speech recognition (speech-to-text and text-to-speech) with Deepgram. It is one of the best Whisper alternatives known for its low latency, data labeling and flexible deployment options.
- It is a developer-focused provider with a rich ecosystem, dedicated support, and diverse SDK options.
- The tool is proficient in handling pre-recorded audio and real-time streams from numerous sources.
- Deepgram supports smart formatting, multiple languages, filler words, and speaker diarization.
It offers a pay-as-you-go plan that gives you $200 in credit absolutely free. You can also opt for its 2 other annual plans :
- Growth-$4k – 10k per year
- Enterprise- Contact the sales team to customize the pricing as per your requirements
Link: https://deepgram.com/

Amazon Transcribe model is part of the AWS platform that supports over 100 languages. It produces easy-to-read transcripts, improves accuracy with customization, ingests diverse audio input, and filters content to enhance customer privacy.
- Easy to integrate if you are already in the AWS ecosystem
- Its Amazon Transcribe API enables you to analyze audio files stored in Amazon S3 and have the service return a text file of the transcribed speech.
- The tool offers domain-specific models tuned to telephone calls or multimedia video content.
Sign up and get started for free for the first 12 months. The Amazon Transcribe Free Tier allows you to analyze up to 60 audio minutes monthly. However, if you want more minutes, you can choose other paid plans:
- T1- $0.02400 (First 250,000 minutes)
- T2- $0.01500 (Next 750,000 minutes)
- T3- $0.01020 (Next 4,000,000 minutes)
- T4- $0.00780 (Over 5,000,000 minutes)
Link: https://aws.amazon.com/transcribe/?nc=sn&loc=0
Considering all factors, Google Speech-to-Text offers the most convenient and flexible solution that can be integrated with other Google Cloud services. This model is best utilized by a GCP customer who wants to keep everything within one ecosystem. The tool is also known for its machine learning algorithms that reduce errors by 64% compared to other regular models and for adding real-time subtitles in your streaming content.
The mechanisms for evaluating a speech-to-text API have remained constant, including speed, accuracy, and price. These tools must match the cutting-edge offerings of a new company to bring value to the table.
We hope this list of 10 best Whisper AI alternatives has demystified the confusion by helping you choose the right speech recognition tool for your particular use case. These easy-to-use platforms offer a highly accurate transcription feature and support customization to suit your industry.
Is there a better model than Whisper AI?
Some leading speech recognition tools supporting multilingual recognition, spoken language identification, and translation include Google Speech-to-Text, Microsoft Azure, and AssemblyAI.
What is the fastest Whisper AI?
Whisper JAX is known as the fastest Whisper AI. It is an optimized implementation of the Whisper model that runs on JAX with a TPU v4-8 in the backend.
Is Whisper Open AI free?
Before March 2023, Whisper AI used to offer its services for free. However, today it costs $0.006 per minute or $0.10 per 1000 seconds.
Please Login to comment...
Similar reads.
- Alternatives
- Websites & Apps
- Google Releases ‘Prompting Guide’ With Tips For Gemini In Workspace
- Google Cloud Next 24 | Gmail Voice Input, Gemini for Google Chat, Meet ‘Translate for me,’ & More
- 10 Best Viber Alternatives for Better Communication
- 12 Best Database Management Software in 2024
- 30 OOPs Interview Questions and Answers (2024)
Improve your Coding Skills with Practice
What kind of Experience do you want to share?

How to Get Started With Google Cloud’s Text-to-Speech API
Share this article

- Introducing Google’s for Text-to-Speech API
- Using Google’s for Text-to-Speech API
- Finetuning Google’s Text-To-Speech Parameters
- Frequently Asked Questions (FAQs) about Google Cloud’s Text-to-Speech API
In this tutorial, we’ll walk you through the process of setting up and using Google Cloud’s Text-to-Speech API, including examples and code snippets .
Introducing Google’s for Text-to-Speech API
As a software engineer, you often need to integrate various APIs into your applications to enhance their functionality. Google Cloud’s Text-to-Speech API is a powerful tool that converts text into natural-sounding speech.
The most common use cases for the Google TTS API include:
- Accessibility : One of the primary applications of TTS technology is to improve accessibility for individuals with visual impairments or reading difficulties. By converting text into speech, the API enables users to access digital content through audio, making it easier for them to navigate websites, read articles, and engage with online services
- Virtual Assistants : The TTS API is often used to power virtual assistants and chatbots, providing them with the ability to communicate with users in a more human-like manner. This enhances user experience and enables developers to create more engaging and interactive applications.
- E-Learning : In the education sector, the Google TTS API can be utilized to create audio versions of textbooks, articles, and other learning materials. This enables students to consume educational content while on the go, multitasking, or simply preferring to listen rather than read.
- Audiobooks : The Google TTS API can be used to convert written content into audiobooks, providing an alternative way for users to enjoy books, articles, and other written materials. This not only saves time and resources on manual narration but also allows for rapid content creation and distribution.
- Language Learning : The API supports multiple languages, making it a valuable tool for language learning applications. By generating accurate and natural-sounding speech, the TTS API can help users improve their listening skills, pronunciation, and overall language comprehension.
- Content Marketing : Businesses can leverage the TTS API to create audio versions of their blog posts, articles, and other marketing materials. This enables them to reach a broader audience, including those who prefer listening to content over reading it.
- Telecommunications : The TTS API can be integrated into Interactive Voice Response (IVR) systems, enabling businesses to automate customer service calls, provide information to callers, and route them to the appropriate departments. This helps companies save time and resources while maintaining a high level of customer satisfaction.
Using Google’s for Text-to-Speech API
Prerequisites.
Before we start, ensure that you have the following:
- A Google Cloud Platform (GCP) account. If you don’t have one, sign up for a free trial here .
- Basic knowledge of Python programming.
- A text editor or integrated development environment of your choice.
Step 1: Enable the Text-to-Speech API
- Log in to your GCP account and navigate to the GCP console .
- Click on the project dropdown and create a new project or select an existing one.
- In the left sidebar, click on APIs & Services > Library .
- Search for Text-to-Speech API and click on the result.
- Click Enable to enable the API for your project.
Step 2: Create API credentials
- In the left sidebar, click on APIs & Services > Credentials .
- Click Create credentials and select Service account .
- Fill in the required details and click Create .
- On the Grant this service account access to project page, select the Cloud Text-to-Speech API User role and click Continue .
- Click Done to create the service account.
- In the Service Accounts list, click on the newly created service account.
- Under Keys , click Add Key and select JSON .
- Download the JSON key file and store it securely, as it contains sensitive information.
Step 3: Set up your Python environment
Install the Google Cloud SDK by following the instructions here .
Install the Google Cloud Text-to-Speech library for Python:
Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to the path of the JSON key file you downloaded earlier:
(Replace /path/to/your/keyfile.json with the actual path to your JSON key file.)
Step 4: Create a Python Script
Create a new Python script (such as text_to_speech.py ) and add the following code:
This script defines a synthesize_speech function that takes a text string and an output filename as arguments. It uses the Google Cloud Text-to-Speech API to convert the text into speech and saves the resulting audio as an MP3 file.
Step 5: Run the script
Execute the Python script from the command line:
This will create an output.mp3 file containing the spoken version of the input text “Hello, world!”.
Step 6 (optional): Customize the voice and audio settings
You can customize the voice and audio settings by modifying the voice and audio_config variables in the synthesize_speech function. For example, to change the language, replace en-US with a different language code (such as es-ES for Spanish). To change the gender, replace texttospeech.SsmlVoiceGender.FEMALE with texttospeech.SsmlVoiceGender.MALE . For more options, refer to the Text-to-Speech API documentation .
Finetuning Google’s Text-To-Speech Parameters
Google’s Speech-to-Text API offers a wide range of configuration parameters that allow developers to fine-tune the API’s behavior to meet specific use cases. Some of the most common configuration parameters and their use cases include:
- Audio Encoding : specifies the encoding format of the audio file being sent to the API. The supported encoding formats include FLAC , LINEAR16 , MULAW , AMR , AMR_WB , OGG_OPUS , and SPEEX_WITH_HEADER_BYTE . Developers can choose the appropriate encoding format based on the input source, audio quality, and the target application.
- Audio Sample Rate : specifies the rate at which the audio file is sampled. The supported sample rates include 8000, 16000, 22050, and 44100 Hz. Developers can select the appropriate sample rate based on the input source and the target application’s requirements.
- Language Code : specifies the language of the input speech. The supported languages include a wide range of options such as English, Spanish, French, German, Mandarin, and many others. Developers can use this parameter to ensure that the API accurately transcribes the input speech in the appropriate language.
- Model : allows developers to choose between different transcription models provided by Google. The available models include default, video, phone_call , and command_and_search . Developers can choose the appropriate model based on the input source and the target application’s requirements.
- Speech Contexts : allows developers to specify specific words or phrases that are likely to appear in the input speech. This can improve the accuracy of the transcription by providing the API with context for the input speech.
These configuration parameters can be combined in various ways to create custom configurations that best suit specific use cases. For example, a developer could configure the API to transcribe a phone call in Spanish using a specific transcription model and a custom list of speech contexts to improve accuracy.
Overall, Google’s Speech-to-Text API is a powerful tool for transcribing speech to text, and the ability to customize its configuration makes it even more versatile. By carefully selecting the appropriate configuration parameters, developers can optimize the API’s performance and accuracy for a wide range of use cases.
In this tutorial, we’ve shown you how to get started with Google Cloud’s Text-to-Speech API, including setting up your GCP account, creating API credentials, installing the necessary libraries, and writing a Python script to convert text or SSML to speech. You can now integrate this functionality into your applications to enhance user experience, create audio content, or support accessibility features.
Frequently Asked Questions (FAQs) about Google Cloud’s Text-to-Speech API
What are the key features of google cloud’s text-to-speech api.
Google Cloud’s Text-to-Speech API is a powerful tool that converts text into natural-sounding speech. It offers a wide range of features including over 200 voices across 40+ languages and variants, giving you a lot of flexibility in terms of language support. It also provides a selection of neural network-powered voices for incredibly realistic speech. The API supports SSML tags, allowing you to add pauses, numbers, date and time formatting, and other pronunciation instructions. It also offers a high level of customization, including pitch, speaking rate, and volume gain control.
How can I get started with Google Cloud’s Text-to-Speech API?
To get started with Google Cloud’s Text-to-Speech API, you first need to set up a Google Cloud project and enable the Text-to-Speech API for that project. You can then authenticate your project and start making requests to the API. The API uses a simple syntax for converting text into speech, and you can customize the voice and format of the speech output.
Is Google Cloud’s Text-to-Speech API free to use?
Google Cloud’s Text-to-Speech API is not entirely free. It comes with a pricing model based on the number of characters you convert into speech. However, Google does offer a free tier for the API, which allows you to convert a certain number of characters per month for free.
How can I integrate Google Cloud’s Text-to-Speech API into my application?
You can integrate Google Cloud’s Text-to-Speech API into your application by making HTTP POST requests to the API. You need to include the text you want to convert into speech in the request, along with any customization options you want to apply. The API will then return an audio data response, which you can play or save as an audio file.
Can I use Google Cloud’s Text-to-Speech API for commercial purposes?
Yes, you can use Google Cloud’s Text-to-Speech API for commercial purposes. However, you should be aware that usage of the API is subject to Google’s terms of service, and you may need to pay for the API if you exceed the free tier limits.
What languages does Google Cloud’s Text-to-Speech API support?
Google Cloud’s Text-to-Speech API supports over 40 languages and variants, including English, Spanish, French, German, Italian, Dutch, Russian, Chinese, Japanese, and Korean. This makes it a versatile tool for applications that need to support multiple languages.
How can I customize the voice in Google Cloud’s Text-to-Speech API?
You can customize the voice in Google Cloud’s Text-to-Speech API by specifying a voice name, language code, and SSML gender in your API request. You can also adjust the pitch, speaking rate, and volume gain of the voice.
Can I use Google Cloud’s Text-to-Speech API offline?
No, Google Cloud’s Text-to-Speech API is a cloud-based service and requires an internet connection to function. You need to make HTTP requests to the API, and the API returns audio data over the internet.
What is the audio quality of the speech generated by Google Cloud’s Text-to-Speech API?
The audio quality of the speech generated by Google Cloud’s Text-to-Speech API is very high. The API uses advanced neural networks to generate natural-sounding speech that is almost indistinguishable from human speech.
Can I use Google Cloud’s Text-to-Speech API to create an audiobook?
Yes, you can use Google Cloud’s Text-to-Speech API to create an audiobook. You can convert large amounts of text into high-quality speech, and you can customize the voice to suit the content of the book. However, you should be aware that creating an audiobook with the API may involve a significant amount of data and may incur costs if you exceed the free tier limits.
Matt is the co-founder of SitePoint, 99designs and Flippa. He lives in Vancouver, Canada.


My 5 favorite Linux text editors (and why you should be using one)
L inux has always had text editors. Back in the early days, the infamous editor wars that pitted emacs against vi and those on either side of the fence were fiercely loyal to their choice.
That was then. Now, the text editor has become something quite different. It's no longer only for configuring Linux or writing code. Although text editors are still used for both of these tasks, they can also be used for note-taking, journals, and even writing a novel. Although I've never used a text editor to write a full-length book, I have used them for short stories and flash fiction.
Also: The best Linux distros for beginners: Expert tested
I expect to catch flack for this, but neither vi nor Emacs is included on this list. Why? Although both of those editors are exceptionally powerful, I've always found them to get in the way more than they help. Emacs and vi aren't for everyday use or for the average user -- and that's what I'm focused on here.
However, if you find the editors listed here too simple or not flexible enough, you can always turn to those two powerhouse tools to help you code, configure, and administer.
For those who appreciate tools that are easier to use (but still effective), read on.
The nano editor has been my go-to for decades. Yes, it's basic, but it gets the job done. Nano includes all the features I need in an editor (and not much more). With nano, you can write simple flat text files (meaning that they have no formatting), and enjoy features like interactive search-and-replace, undo/redo, syntax coloring, smooth scrolling, auto-indentation, go-to-line-and-column-number, feature toggles, file locking, and internationalization support.
Also: 5 Linux file and folder management commands you need to know
One thing to note: Nano is a terminal application, which means it doesn't have a GUI app. You open the terminal and issue the command nano filename (where filename is the file you want to either edit or create). There are several options you can use, such as --backup (which creates a backup of the previous version of the file), --tabstospaces (which converts typed tabs to spaces), --locking (which locks the file when editing), --smooth (for smooth scrolling), and many more.
Nano is free and comes pre-installed with most Linux distributions.
Gedit, the default text editor for the GNOME desktop , is a basic but effective GUI application. With Gedit you'll find features like tabs, support for internationalized text (UTF-8), syntax highlighting, markdown support, configurable fonts and colors, print support, auto-save, create auto backup, keyboard shortcuts, theming, full-screen mode, and more.
The thing that sells me on Gedit is its simplicity. Although I almost always default to nano, when I need a GUI, it's usually Gedit. Ultimately, however, one of the main reasons I keep Gedit around is that the nano editor has to be opened from the terminal window, which means clicking on a link to a text file doesn't exactly work as planned. Ergo, Gedit. There is, however, another reason why I sometimes will opt for Gedit. You can use this text editor in fullscreen mode, so when I want to edit a text file without distraction, I can go fullscreen and chase everything else away.
Also: The top 5 GNOME extensions I install first (and what they can do for you)
Gedit is free and ships with most GNOME-based desktop distributions.
3. COSMIC Text Editor
COSMIC Text Editor will be the default text editor for System76's COSMIC desktop (once it's finally released). However, the COSMIC Text Editor is already showing great progress and promises to be the Gedit equivalent of COSMIC. COSMIC will include a fairly typical feature set, such as syntax highlighting, standard keyboard shortcuts, find, spellcheck, project support, revert changes, document statistics, and even Git management support.
It's a rare occasion that I find a dark theme preferable, but with COSMIC Text Editor, it just seems fitting. Like Gedit, COSMIC Text Editor is very simple to use and can be employed for basic or even more complicated tasks (such as writing code). If you use Pop!_OS, you can get an idea of what COSMIC Text Editor will look and feel like by installing it from the Pop Shop .
COSMIC Text Editor is free and will be officially available when the COSMIC Desktop OS ships.
Also: Linux distro hopping is a fun way to find the perfect desktop operating system
Kate is to KDE Plasma what Gedit is to GNOME. The difference between the two is that Kate offers a few more features, such as multi-cursor and multi-cursor selection (which allows you to select multiple strings of text at once or even manipulate multiple strings at the same time). Kate also features project support, syntax highlighting, standard keyboard shortcuts, and even plugins. With the plugins feature, you can add SQL query support, GDB debugging, one-click project build, and more. Think of Kate as a supercharged version of Gedit that can also be used for creating and editing simple text files.
Kate is free and ships as the default text editor for the KDE Plasma desktop .
Also: My top 5 user-friendly GUI backup tools for the Linux desktop (and why you need one)
5. Sublime Text
Sublime Text is the only proprietary editor on the list. Sublime Text is also the most powerful (by far) of those listed. One thing to understand about Sublime is that it is geared toward programmers and proves it with features like GPU rendering support, tab multi-select, context-aware auto-complete, powerful syntax highlighting engine, in-editor code building, snippets, command palette (to launch specific commands with keyboard shortcuts), simultaneous editing, and more. Yes, Sublime can also be used for creating and editing basic text files, but that would be like going to the grocery store in a Ferrari.
Also: My 4 favorite Android note-taking apps for staying organized and on track
Sublime can be tested for free on Linux (as well as MacOS and Windows), but to continue using this powerful text editor, it will cost you a one-time payment of .
If you're just looking to create and edit simple text files (or edit Linux configuration files), stick with nano. If you prefer a GUI, any one of these tools will work for you. If you like the idea of Sublime Text (which is a fantastic tool), just remember it's probably more power than you'll ever need for simple text editing.
- The best Linux laptops for consumers and developers
- Want to save your aging computer? Try these 5 Linux distributions
- The best distros for beginners
- How to enable Linux on your Chromebook (and why you should)
")

AI + Machine Learning , Analyst Reports , Azure AI , Virtual Machines
New infrastructure for the era of AI: Emerging technology and trends in 2024
By Omar Khan General Manager, Azure Product Marketing
Posted on April 1, 2024 4 min read
- Tag: Azure confidential computing
- Tag: Generative AI
- Tag: High-performance computing
- Tag: Virtual Machines
This is part of a larger series on the new infrastructure of the era of AI, highlighting emerging technology and trends in large-scale compute. This month, we’re sharing the 2024 edition of the State of AI Infrastructure report to help businesses harness the power of AI now.
The era of AI is upon us. You’ve heard about the latest advancements in our technology, the new AI solutions powered by Microsoft, our partners, and our customers, and the excitement is just beginning. To continue the pace of these innovations, companies need the best hardware that matches the workloads they are trying to run. This is what we call purpose-built infrastructure for AI—it’s infrastructure that is customized to meet your business needs. Now, let’s explore how Microsoft cloud infrastructure has evolved to support these emerging technologies.

The State of AI Infrastructure
An annual report on trends and developments in AI infrastructure based on Microsoft commissioned surveys conducted by Forrester Consulting and Ipsos
Looking back at Microsoft’s biggest investments in AI infrastructure
2023 brought huge advancements in AI infrastructure . From new virtual machines to updated services, we’ve paved the way for AI advancements that include custom-built silicon and powerful supercomputers.
Some of the highlights of Microsoft AI infrastructure innovations in 2023 include:
- Launching new Azure Virtual Machines powered by AMD Instinct and NVIDIA Hopper graphics processing units (GPUs), optimized for different AI and high-performance computing (HPC) workloads, such as large language models, mid-range AI training, and generative AI inferencing.
- Introducing Azure confidential VMs with NVIDIA H100 GPUs—enabling secure and private AI applications on the cloud.
- Developing custom-built silicon for AI and enterprise workloads, such as Azure Maia AI accelerator series, an AI accelerator chip, and Azure Cobalt CPU series, a cloud-native chip based on Arm architecture.
- Building the third most powerful supercomputer in the world, Azure Eagle, with 14,400 NVIDIA H100 GPUs and Intel Xeon Sapphire Rapids processors and achieving the second best MLPerf Training v3.1 record submission using 10,752 H100 GPUs.
Understanding the state of AI and demand for new infrastructure
2024 is shaping up to be an even more promising year for AI than its predecessor. With the rapid pace of technological advancements, AI infrastructure is becoming more diverse and widespread than ever before. From cloud to edge, CPUs to GPUs, and application-specific integrated circuits (ASICs), the AI hardware and software landscape is expanding at an impressive rate.
To help you keep up with the current state of AI, its trends and challenges, and to learn about best practices for building and deploying scalable and efficient AI systems, we’ve recently published our Microsoft Azure: The State of AI Infrastructure report. The report addresses the following key themes:
- Using AI for organizational and personal advancement AI is revolutionizing the way businesses operate, with an overwhelming 95% of organizations planning to expand their usage in the next two years. Recent research commissioned by Microsoft highlights the role of AI in driving innovation and competition. Beyond mandates, individuals within these organizations recognize the value AI brings to their roles and the success of their companies. IT professionals are at the forefront of AI adoption and use, with 68% of those surveyed already implementing it in their professional work. But it doesn’t stop there—AI is also being used in their personal lives, with 66% of those surveyed incorporating it into their daily routines. AI’s transformative potential spans across industries, from improving diagnostic accuracy in healthcare to optimizing customer service through intelligent chatbots . As AI shapes the future of work, it’s essential for organizations to embrace its adoption to stay competitive in an ever-evolving business landscape.
- Navigating from AI exploration to implementation The implementation of AI in businesses is still in its early stages, with one-third of companies exploring and planning their approach. However, a significant segment has progressed to pilot testing, experimenting with AI’s capabilities in real-world scenarios. They’re taking that next critical step towards full-scale implementation. This phase is crucial as it allows businesses to gauge the effectiveness of AI, tailor it to their specific needs, and identify any potential issues before a wider rollout. Because of this disparity in adoption, organizations have a unique opportunity to differentiate themselves and gain a competitive advantage by accelerating their AI initiatives. However, many organizations will need to make significant tech and infrastructure changes before they can fully leverage AI’s benefits. Those who can quickly navigate from exploration to implementation will establish themselves as leaders in leveraging AI for innovation, efficiency, and enhanced decision-making.
- Acknowledging challenges of building and maintaining AI infrastructure To fully leverage AI’s potential, companies need to ensure they have a solid foundation to support their AI strategies and drive innovation. Like the transportation industry, a solid infrastructure to manage everyday congestion is crucial. However, AI infrastructure skilling remains the largest challenge, both within companies and in the job market. This challenge is multifaceted, encompassing issues such as the complexity of orchestrating AI workloads, a shortage of skilled personnel to manage AI systems, and the rapid pace at which AI technology evolves. These hurdles can impede an organization’s ability to fully leverage AI’s potential, leading to inefficiencies and missed opportunities.
- Leveraging partners to accelerate AI innovation Strategic partnerships play a pivotal role in the AI journey of organizations. As companies delve deeper into AI, they often seek out solution providers with deep AI expertise and a track record of proven AI solutions. These partnerships are instrumental in accelerating AI production and addressing the complex challenges of AI infrastructure. Partners are expected to assist with a range of needs, including infrastructure design, training, security, compliance, and strategic planning. As businesses progress in their AI implementation, their priorities shift towards performance, optimization, and cloud provider integration. Engaging the right partner can significantly expedite the AI journey for businesses of any size and at any stage of AI implementation. This presents a substantial opportunity for partners to contribute, but it also places a responsibility on them to ensure their staff is adequately prepared to provide consulting, strategy, and training services.
Discover more
To drive major AI innovation , companies must overcome many challenges at a breakneck pace. Our insights in The State of AI Infrastructure report underscore the need for a strategic approach to building and maintaining AI infrastructure that is agile, scalable, and capable of adapting to the latest technological advancements. By addressing these infrastructure challenges, companies can ensure they have a solid foundation to support their AI strategies and drive innovation.
- Annual Roundup of AI Infrastructure Breakthroughs for 2023
#AIInfraMarketPulse
Let us know what you think of Azure and what you would like to see in the future.
Provide feedback
Build your cloud computing and Azure skills with free courses by Microsoft Learn.
Explore Azure learning
Related posts
AI + Machine Learning , Azure AI , Azure VMware Solution , Events , Microsoft Copilot for Azure , Microsoft Defender for Cloud
Get ready for AI at the Migrate to Innovate digital event chevron_right
AI + Machine Learning , Azure AI Speech , Azure AI Studio , Azure OpenAI Service , Azure SQL Database
What’s new in Azure Data, AI, and Digital Applications: Helping you navigate the fast pace of change chevron_right
AI + Machine Learning , Announcements , Azure AI , Azure AI Search
Announcing updates to Azure AI Search to help organizations build and scale generative AI applications chevron_right
AI + Machine Learning , Azure AI , Industry trends
Azure Maia for the era of AI: From silicon to software to systems chevron_right
UbuntuHandbook
News, Tutorials, Howtos for Ubuntu Linux
- Ubuntu 24.04
- Ubuntu PPAs
- Install Ubuntu 22.04

Kodi 21 “Omega” Stable Officially Released! [How to Install]
After more than a year of development, Kodi media player 21, code-name “Omega”, is finally released!
Kodi 21 is a new major release. It’s now based on FFmpeg 6.0 , that features Radiance HDR image support, VAAPI decoding and QSV decoding for 10/12bit 422, 10/12bit 444 HEVC and VP9, MediaCodec decoder, and various other exciting new features, see ffmpeg.org for details.
For macOS, the release supports HiDPI (retina) displays using its native implementations for window displays. And, it fixed crash on speech recognition activation, improved window resizing when moving (or fallback when display disconnected) from one display to another, and implemented Hotkeycontroller for media keys.
For Windows, it added DXVA Video Super Resolution upscaler, that’s supported NVIDIA “RTX Video Super Resolution” and “Intel Video Super Resolution”, fixed blue/pink washed out colors on 10-bit displays. And, now it shows 119.88Hz and future higher fractional refresh rates correctly.
For Linux, the release allows Pipewire to properly identify HDMI for passthrough usage, adds xkb compose and dead-keys support for Wayland, and platforms using libinput/evdev.
Other changes include:
- Support LG webOS TV.
- Support M3U8 playlist files
- New in-game window to view which game port each player’s controller is currently connected to.
- AVIF images support
- HDR10 for Android
- Support to use font collection (.ttc) to subtitles
- Xbox support for HDR10 passthrough.
How to Install Kodi 21 in Ubuntu & other Linux
Kodi provides official packages available to download at its website via the link below:
For Linux, it’s a Flatpak package that works in most Linux Distributions. Linux Mint 21 and Fedora 38/39/40 (with 3rd party repository enabled) can search for and install it from either Software Manager or GNOME Software.

Kodi Flatpak package in Fedora GNOME Software
For Ubuntu, and other Linux , follow the steps below one by one to install the app as Flatpak package:
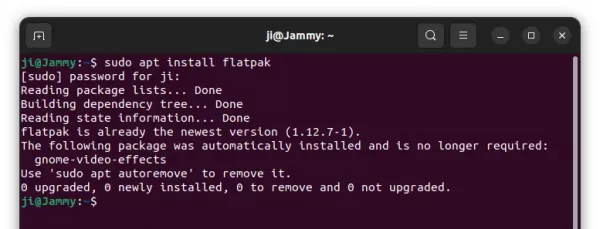
If you’ve already have the Flatpak package installed, then update it by running command:
Once installed, search for and launch the media player either from start menu or Gnome ‘Show Apps screen depends on your desktop environment (Log out and back in if app icon not visible).

Uninstall Kodi
To uninstall Kodi flatpak package, open terminal (for Ubuntu, press Ctrl+Alt+T) and run command:
Also run flatpak uninstall --unused to clear useless run-time libraries.

Posts --> Twitter
- Install & Manage Flatpak Apps...
- How to Install & Setup PeaZip...
No Comments
Be the first to start the conversation.
Leave a Reply Cancel reply
Text formatting is available via select HTML . <a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>
Current ye ignore me @r *
Leave this field empty
Subscribe to receive latest news and tutorials in your inbox !
We don’t spam! Read our privacy policy for more info.
Check your inbox or spam folder to confirm your subscription.
- MPV 0.37.0 Released with VideoToolbox hwdec (Ubuntu PPA) 5 comments since November 22, 2023


Play Minecraft Games with Game Pass
ALSO AVAILABLE ON:
Minecraft is available to play on the following platforms:

*Mac and Linux are compatible with Java Edition only.

Minecraft Preview 1.21.0.21
A Minecraft Bedrock Edition Preview
We always talk about squashing bugs in our changelogs, but this week we’re doing it with an enchanted mace for extra squashing power! Test out the Density, Breach, and Wind Burst enchantments, which are all unique to the mace, and see which fits your combat style the best. Just mind you don’t smash any of the walls of your base, because you might want to decorate them with another feature included in this testing release – five new Minecraft paintings. From blocky baroque stills to even blockier landscapes, this changelog has more ways to decorate your base and more ways to smash it all to pieces. Let’s dive in!
Here’s a list of what’s new in this week’s Preview and Beta! We’d love your feedback, as always, so please let us know what you think at feedback.minecraft.net , and report any bugs at bugs.mojang.com .
Experimental Features
- Wind Burst generates a burst of wind when successfully striking enemies, launching the wielder in the air!
- Density makes the already heavy Mace EVEN HEAVIER, adding additional heft to its Smash Attack!
- Breach allows the Mace to bypass a portion of an enemy's Armor, striking fear into the hearts of even the most protected enemies!
- Added a new explosive particle effect when executing a smash attack with the Mace to really show the player's power when using it!
- Known issues: Particles appear grey in water and on some leaves. Particles appear when target is hit in the air.
Mob Effects
- Instead of triggering a Raid directly, Bad Omen will transform into a Raid Omen variant with a duration of 30 seconds
- Once the Raid Omen expires, a Raid will start at the location the player gained the Raid Omen
- Like any other effect, players can drink a Bucket of Milk to clear the Raid Omen to prevent the Raid from starting
- Added activation sounds to Bad Omen, Trial Omen, and Raid Omen
- Prairie Ride
Trial Chambers
- Trial Chambers are now more consistently buried by terrain when found underground
Trial Spawner
- Ominous Trial Spawners now show a preview of the item that is about to be dropped
Features and Bug Fixes
- "coral_block" block is now split into unique instances: "tube_coral_block", "brain_coral_block", "bubble_coral_block", "fire_coral_block", "horn_coral_block", "dead_tube_coral_block", "dead_brain_coral_block", "dead_bubble_coral_block", "dead_fire_coral_block" and "dead_horn_coral_block"
- Chemistry items now appear in the creative inventory when the Education edition toggle is on
- Fixed a crash that could occur when teleporting to a region where a Piston is pushing a Chest ( MCPE-179440 )
- Fixed a crash that could occur when the player begins losing air
Hardcore Mode (Preview Only)
- The death screen now shows “Spectate World” option when playing in Hardcore Mode ( MCPE-180287 )
- Armadillos no longer repeatedly roll and unroll when receiving damage from blocks ( MCPE-180142 )
- Fixed several instances of periods being narrated as 'dot' on the Realms Stories 'Opt In' screen (Preview only)
Accessibility Features
- Added text-to-speech support for member search results in the Realms Stories Member tab (Preview Only)
- The Realms Stories Opt In screen now enumerates its active buttons with text-to-speech on (Preview Only)
User Interface
- Added slide-off persistence to new d-pad touch control scheme
- Changes positioning and scale of default new touch d-pad control scheme. Also allows for moving the dpad closer to the hotbar when customizing touch controls.
- Made the jump and ascend in water button overlap so now the player can stay above water more easily ( MCPE-179689 )
- Fix a bug that prevented navigating to previously sent messages with a keyboard on Xbox ( MCPE-174648 )
Technical Updates
Add-ons and script engine.
- Fixed some places in documentation generation where elements were accidentally overwritten. This caused a minor amount of documentation to appear or move in the Animations, Blocks, Entities, and Particles files
- This allows you to rotate the specified uv rect in 90 degree increments before applying it to a block face
- Supported from minecraft:geometry format version 1.21.0 and up
- Added pivot for scale in the Block Transformation Component
- Added pivot for rotation in the Block Transformation Component
Documentation
- Documentation for version v1.13.0 of "Decoration Features" is now up to date
Editor is now in v0.6 with the following new features:
- New Panel Layout – panels can be toggled, resized, and support auto-hide
- Widget Framework – editor extensions can now use custom entities and animations to mark information within the world
- Global Block Hotbar + Picker – customize and swap between your most common blocks to build even faster
- Brush Shape Framework – use our resizable brush shapes to quickly modify the world or add your own with editor extensions
- Summon Tool – quickly create, move, rotate, and delete entities
- Line Tool – build parkour maps, bridges, roads with our new line tool
- Improved performance, bug fixes, and many more!
See the full changelog for our v0.6 release on the Editor GitHub Discussion page!
Learn how to use the Editor, join the GitHub Discussion forum to engage with the team, and get started building extensions via the starter kit and samples .
Experimental Technical Updates
- get will now handle items whose names have changed so that scripts referencing old names will still work as intended
- Added ItemComponentUseOnEvent for beta
- Moved typeId and Block.matches from beta to stable
- BigInt support
- Array findLast and at
- Miscellaneous bug fixes
- Moved id API from beta to stable v1.11.0
- Moved BlockTypes API from beta to stable v1.11.0
- Moved type API from beta to stable v1.11.0
- Fixed heightmap textures not rendering correctly in the Deferred Technical Preview
SHARE THIS STORY
Community creations.
Discover the best add-ons, mods, and more being built by the incredible Minecraft community!
Block...Block...Block...

Twitter’s Clumsy Pivot to X.com Is a Gift to Phishers
On April 9, Twitter/X began automatically modifying links that mention “twitter.com” to read “x.com” instead. But over the past 48 hours, dozens of new domain names have been registered that demonstrate how this change could be used to craft convincing phishing links — such as fedetwitter[.]com , which until very recently rendered as fedex.com in tweets.
The message displayed when one visits goodrtwitter.com, which Twitter/X displayed as goodrx.com in tweets and messages.
A search at DomainTools.com shows at least 60 domain names have been registered over the past two days for domains ending in “twitter.com,” although research so far shows the majority of these domains have been registered “defensively” by private individuals to prevent the domains from being purchased by scammers.
Those include carfatwitter.com , which Twitter/X truncated to carfax.com when the domain appeared in user messages or tweets. Visiting this domain currently displays a message that begins, “Are you serious, X Corp?”
Update: It appears Twitter/X has corrected its mistake, and no longer truncates any domain ending in “twitter.com” to “x.com.”
Original story:
The same message is on other newly registered domains, including goodrtwitter.com (goodrx.com), neobutwitter.com (neobux.com), roblotwitter.com (roblox.com), square-enitwitter.com (square-enix.com) and yandetwitter.com (yandex.com). The message left on these domains indicates they were defensively registered by a user on Mastodon whose bio says they are a systems admin/engineer. That profile has not responded to requests for comment.
A number of these new domains including “twitter.com” appear to be registered defensively by Twitter/X users in Japan. The domain netflitwitter.com (netflix.com, to Twitter/X users) now displays a message saying it was “acquired to prevent its use for malicious purposes,” along with a Twitter/X username.
The domain mentioned at the beginning of this story — fedetwitter.com — redirects users to the blog of a Japanese technology enthusiast. A user with the handle “amplest0e” appears to have registered space-twitter.com , which Twitter/X users would see as the CEO’s “space-x.com.” The domain “ametwitter.com” already redirects to the real americanexpress.com.
Some of the domains registered recently and ending in “twitter.com” currently do not resolve and contain no useful contact information in their registration records. Those include firefotwitter[.]com (firefox.com), ngintwitter[.]com (nginx.com), and webetwitter[.]com (webex.com).
The domain setwitter.com, which Twitter/X until very recently rendered as “sex.com,” redirects to this blog post warning about the recent changes and their potential use for phishing.
Sean McNee , vice president of research and data at DomainTools, told KrebsOnSecurity it appears Twitter/X did not properly limit its redirection efforts.
“Bad actors could register domains as a way to divert traffic from legitimate sites or brands given the opportunity — many such brands in the top million domains end in x, such as webex, hbomax, xerox, xbox, and more,” McNee said. “It is also notable that several other globally popular brands, such as Rolex and Linux, were also on the list of registered domains.”
The apparent oversight by Twitter/X was cause for amusement and amazement from many former users who have migrated to other social media platforms since the new CEO took over. Matthew Garrett , a lecturer at U.C. Berkeley’s School of Information, summed up the Schadenfreude thusly:
“Twitter just doing a ‘redirect links in tweets that go to x.com to twitter.com instead but accidentally do so for all domains that end x.com like eg spacex.com going to spacetwitter.com’ is not absolutely the funniest thing I could imagine but it’s high up there.”
31 thoughts on “ Twitter’s Clumsy Pivot to X.com Is a Gift to Phishers ”
It’s been patched already, before anyone could abuse, click-bait article.
Came to say the same Krebs must no like X.
I started reporting this last night, when it was still very much a thing. The story has been updated to note that Twitter/X apparently has fixed its mistake.
Hopefully the coders behind this innovative case, and those who tested the work, do not go anywhere near the alleged blue-sky-one-day-promise self-driving vehicle elon keeps hyping to pump his stock. It is known Elon uses his companies interchangeably and brought Tesla people to X, so no doubt the reverse can happen. Or, perhaps, he lost the password to his fiverr account 🙂
Even if it was patched, this was a monumental blunder. Lessons learned in outsourcing your regex to high schoolers.
Yes, and unlikely to help the CEO with his efforts to win back advertisers and major brands, many of whom are probably hopping mad about this.
I’m sorry, did you mean regetwitter?
Ha! Ha! Nice, Gene
But the fact is that Twitter systems admins and operators made a newbie mistake, and didn’t test their changes. And we surely will take your word that the problem has been resolved…
Even if it has been patched, it shows a lack of quality control on the part of Twitter/X. This is an elementary mistake that should have easily been caught through proper testing. Also sounds like it took them at least 2 days to fix it given the increase in domain registrations ending in twitter.
Seriously? KOS doesn’t need to do click bait.
Everything Musk Touches Gets FU In Time.
Don’t cry you bitch
And on cue, the bot/troll accounts arrive to do their thing. Someone is submitting a lot of these comments. Typical.
You hit a lot of nerve with the russian trolls for sure. My guess is that “your love” for mother ruzzia is egging them on.
This is what happens when a manchild fires all the good developers.
Although, Brian, I’m not sure I understand how fedex.com turned into fedetwitter.com when they were replacing twitter.com with x.com?
You can call him a manchild if you like, but that manchild has more money than you…and was smart enough to purge Twitter/X of the indoctrinated horde…
And replaces them with sycophants too frightened to challenge him? Yep, that’s progress…
“was smart enough to purge Twitter/X of the indoctrinated horde…”
… and replaced them with a vile pit of indoctrinated Andrew Tate wannabees, costing said manchild billions in advertising revenue. LOL
Your comment is not the flex you think it is.
fedetwitter.com -> (replace all instances of ‘twitter.com’ with ‘x.com’) -> fede(twitter.com) -> fede(x.com) -> fedex.com
You don’t work for Twitter?
It’s interesting to go to the setwitter.com website.
I think we can just say, “Elon Musk” to explain this debacle! Glad it’s been found, being dealt with, and reported. Thank you, Kerbs on Security! You saved me from some major issues this morning, or yesterday with reports on Microsofts major security issues and required updates. I took care of that, immediately!
You are the top notifier of web security awareness!
This is an epic but ‘clbuttic’ text substitution mistake!
Needed a good chuckle this a.m. Thx, Brian.
krebs still big mad with TDS and his hate for elon and free speech.
Do they teach rudimentary English where you live? Or if this is your fifth language? I suppose we should be grateful that you’ve tried. Mostly when writing English, we use a capital letter (that is a B for big letter) at the start of a sentence.
Krebs IS still mad… (if so, I guess you have the evidence). As in use “is” – not the big letters that I used for emphasis.
Elon is a person’s name, so it also has a capital letter.
My daughter could understand this by, oh maybe the seventh grade, and English is her third language.
Even I can manage better and I have a visual handicap (so severe, for example, that I cannot drive a motor vehicle).
If you are going to insult somebody, try doing it properly.
You might not be American, neither am I, but even I have a rudimentary understanding of the concept of free speech and Constitutional protections in that country. Much of the same provisions are broadly applicable in most civilised countries anyway. Just because you might open your mouth and shout fire in a crowded theatre, when there is no fire, does not mean your free speech is emasculated when you appear in front of a judicial body.
Krebs is the Jon Stewart of security reporting.
-> back to Breitbart, human fleas.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *

IMAGES
VIDEO
COMMENTS
7. Mycroft. Mycroft comes with an easy-to-use open source voice assistant for converting voice to text. It is regarded as one of the most popular Linux speech recognition tools in modern time, written in Python. It allows users to make the best use of this tool in a science project or enterprise software application.
Learn about the best open source speech recognition software for Linux, such as Whisper, Flashlight, Kaldi, and DeepSpeech. These tools use machine learning and artificial intelligence to improve the accuracy and performance of speech to text recognition.
4. Flashlight ASR (Formerly Wav2Letter++) If you are looking for something modern, then this one can be included. Flashlight ASR is an open source speech recognition software that was released by Facebook's AI Research Team. The code is a C++ code released under the MIT license.
Linux Speech to Text August 17, 2023 · 1 min read. Engineering Speech-to-Text. Linux is versatile as it can power servers, desktops, and various embedded machines like Raspberry Pi or NVIDIA Jetson. Thankfully, Picovoice Speech-to-Text engines support all these variants of ...
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that reads in audio from .WAV files, a microphone, or system audio inputs and converts any speech found into text.
Open your terminal window and install. Log into your desktop and open the terminal window app. Once the app is open, paste the following command and hit Enter on your keyboard: flatpak install ...
In this tutorial, we'll use the open-source speech recognition toolkit Kaldi in conjunction with Python to automatically transcribe audio files. By the end of the tutorial, you'll be able to get transcriptions in minutes with one simple command! For this tutorial, we are using Ubuntu 20.04.03 LTS (x86_64 ISA).
Simon is an open source speech recognition program that can replace your mouse and keyboard. The system is designed to be as flexible as possible and will work with any language or dialect. Simon uses the KDE libraries, CMU SPHINX and / or Julius coupled with the HTK and runs on Windows and Linux. Check out a short demo. To find out more about ...
Here, we perform speech recognition on the convertedFile.wav audio file using both TensorFlow and Coqui STT. The recognized text is displayed in the second part of the output. Of course, the default is English, but we can set another language: $ spchcat --language=it_IT. In this case, we changed the default language to Italian. 6. Using whisper
After a long time of searching I finally found a speech to text software for Linux that actually works well enough that I can use it for dictating without having to jump through too many hoops to configure and use. The software is called nerd-dictation and is an open source software. It is fairly easy to setup as compared to the other voice-to ...
Learn how to run Speech-to-Text on Ubuntu with Picovoice Leopard, a free and open-source software that matches the accuracy of API alternatives. Follow the steps to install Leopard Python package, create an instance of Leopard STT, and transcribe a file.
DeepSpeech is an open source embedded (offline, on-device) speech-to-text engine which can run in real time on devices ranging from a Raspberry Pi 4 to high power GPU servers. machine-learning embedded deep-learning offline tensorflow speech-recognition neural-networks speech-to-text deepspeech on-device.
Unique Features. voice2json is more than just a wrapper around pocketsphinx, Kaldi, DeepSpeech, and Julius!. Training produces both a speech and intent recognizer. By describing your voice commands with voice2json's templating language, you get more than just transcriptions for free.; Re-training is fast enough to be done at runtime (usually < 5s), even up to millions of possible voice commands.
11. pocketsphinx will do speech to text from an existing audio file. Depending on the initial format of the mp3, you may need two separate commands. First convert your existing audio file to the mandatory input format: ffmpeg -i file.mp3 -ar 16000 -ac 1 file.wav. The run pocketsphinx.
All the above-mentioned native Linux solutions have both poor accuracy and usability (or some don't allow free-text dictation but only voice commands). By poor accuracy, I mean an accuracy significantly below the one the speech recognition software I mentioned below for other platforms have.
Speech Note use OpenAI's Whisper and a stack of other open-source libraries, voice engines, and other doohickeys to perform its transliterative magic. It supports Speech to Text (i.e you speak, it types), Text to Speech (i.e. you type, it speaks), and machine translation to translate text/speech from one language to another. Speech Note ...
Speech to text software, sometimes known as dictation software, can be used on desktop machines, or speech to text apps can be used on a smartphone. Speech to text software and apps can be standalone products, or built into existing applications. Compare the best Speech to Text software for Linux currently available using the table below.
This is how you can convert speech to text in Linux systems, including Ubuntu. There is not much speech recognition software available in Linux systems, including native desktop apps. There are some apps available that use IBM Watson and other APIs to convert speech to text, but they are not user-friendly and require an advanced level of user ...
eSpeak: Text To Speech Tool For Linux. eSpeak is a command line tool for Linux that converts text to speech. This compact speech synthesizer provides support for English and many other languages. It is written in C. eSpeak reads the text from the standard input or input file. The voice generated, however, is nowhere close to a human voice.
Many Linux tools convert text to speech or audio files from the command line, improving accessibility. Some of them also come with features like multiple voice options, multiple languages, pitch adjustment, and word gap control. In this tutorial, we'll discuss four commands for getting speech output from command line text. 2. espeak
Features. The VoxSigma software suite for Linux offers large vocabulary speech-to-text capabilities in multiple languages. It includes adaptive features allowing the transcription of noisy speech, such as speech over background music. The software suite has been designed for professional users needing to transcribe large quantities of audio and ...
First, you'll need to download and install the app onto your Linux system. Don't worry, it's a breeze to install and won't take up much space on your hard drive. Once installed, simply ...
Rev AI. Rev AI is one of the best Whisper AI alternatives that offers automated speech-to-text services powered by advanced machine learning algorithms. It is a wonderful option for highly accurate English language use cases that deliver high accuracy when essential text-to-speech software does not. Features:
Step 1: Enable the Text-to-Speech API. Log in to your GCP account and navigate to the GCP console. Click on the project dropdown and create a new project or select an existing one. In the left ...
Kate is free and ships as the default text editor for the. KDE Plasma desktop. . Also: My top 5 user-friendly GUI backup tools for the Linux desktop (and why you need one) Sublime Text. is the ...
Provision Windows and Linux VMs in seconds. Azure Virtual Desktop Enable a secure, remote desktop experience from anywhere. Azure SQL Migrate, modernize, and innovate on the modern SQL family of cloud databases ... Unified speech services for speech-to-text, text-to-speech and speech translation. Azure AI Language
For Ubuntu, and other Linux, follow the steps below one by one to install the app as Flatpak package:. First, press Ctrl+Alt+T on keyboard to open terminal, then run command to enable Flatpak support: sudo apt install flatpak. For other Linux, follow the official setup guide to enable the package format support.; Then, install the player as Flatpak package by running the command below in terminal:
Added text-to-speech support for member search results in the Realms Stories Member tab (Preview Only) The Realms Stories Opt In screen now enumerates its active buttons with text-to-speech on (Preview Only) User Interface. Added slide-off persistence to new d-pad touch control scheme
Twitter's Clumsy Pivot to X.com Is a Gift to Phishers. On April 9, Twitter/X began automatically modifying links that mention "twitter.com" to read "x.com" instead. But over the past 48 ...