Pilot Study in Research: Definition & Examples
Julia Simkus
Editor at Simply Psychology
BA (Hons) Psychology, Princeton University
Julia Simkus is a graduate of Princeton University with a Bachelor of Arts in Psychology. She is currently studying for a Master's Degree in Counseling for Mental Health and Wellness in September 2023. Julia's research has been published in peer reviewed journals.
Learn about our Editorial Process
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A pilot study, also known as a feasibility study, is a small-scale preliminary study conducted before the main research to check the feasibility or improve the research design.
Pilot studies can be very important before conducting a full-scale research project, helping design the research methods and protocol.

How Does it Work?
Pilot studies are a fundamental stage of the research process. They can help identify design issues and evaluate a study’s feasibility, practicality, resources, time, and cost before the main research is conducted.
It involves selecting a few people and trying out the study on them. It is possible to save time and, in some cases, money by identifying any flaws in the procedures designed by the researcher.
A pilot study can help the researcher spot any ambiguities (i.e., unusual things), confusion in the information given to participants, or problems with the task devised.
Sometimes the task is too hard, and the researcher may get a floor effect because none of the participants can score at all or can complete the task – all performances are low.
The opposite effect is a ceiling effect, when the task is so easy that all achieve virtually full marks or top performances and are “hitting the ceiling.”
This enables researchers to predict an appropriate sample size, budget accordingly, and improve the study design before performing a full-scale project.
Pilot studies also provide researchers with preliminary data to gain insight into the potential results of their proposed experiment.
However, pilot studies should not be used to test hypotheses since the appropriate power and sample size are not calculated. Rather, pilot studies should be used to assess the feasibility of participant recruitment or study design.
By conducting a pilot study, researchers will be better prepared to face the challenges that might arise in the larger study. They will be more confident with the instruments they will use for data collection.
Multiple pilot studies may be needed in some studies, and qualitative and/or quantitative methods may be used.
To avoid bias, pilot studies are usually carried out on individuals who are as similar as possible to the target population but not on those who will be a part of the final sample.
Feedback from participants in the pilot study can be used to improve the experience for participants in the main study. This might include reducing the burden on participants, improving instructions, or identifying potential ethical issues.
Experiment Pilot Study
In a pilot study with an experimental design , you would want to ensure that your measures of these variables are reliable and valid.
You would also want to check that you can effectively manipulate your independent variables and that you can control for potential confounding variables.
A pilot study allows the research team to gain experience and training, which can be particularly beneficial if new experimental techniques or procedures are used.
Questionnaire Pilot Study
It is important to conduct a questionnaire pilot study for the following reasons:
- Check that respondents understand the terminology used in the questionnaire.
- Check that emotive questions are not used, as they make people defensive and could invalidate their answers.
- Check that leading questions have not been used as they could bias the respondent’s answer.
- Ensure that the questionnaire can be completed in a reasonable amount of time. If it’s too long, respondents may lose interest or not have enough time to complete it, which could affect the response rate and the data quality.
By identifying and addressing issues in the pilot study, researchers can reduce errors and risks in the main study. This increases the reliability and validity of the main study’s results.
Assessing the practicality and feasibility of the main study
Testing the efficacy of research instruments
Identifying and addressing any weaknesses or logistical problems
Collecting preliminary data
Estimating the time and costs required for the project
Determining what resources are needed for the study
Identifying the necessity to modify procedures that do not elicit useful data
Adding credibility and dependability to the study
Pretesting the interview format
Enabling researchers to develop consistent practices and familiarize themselves with the procedures in the protocol
Addressing safety issues and management problems
Limitations
Require extra costs, time, and resources.
Do not guarantee the success of the main study.
Contamination (ie: if data from the pilot study or pilot participants are included in the main study results).
Funding bodies may be reluctant to fund a further study if the pilot study results are published.
Do not have the power to assess treatment effects due to small sample size.
- Viscocanalostomy: A Pilot Study (Carassa, Bettin, Fiori, & Brancato, 1998)
- WHO International Pilot Study of Schizophrenia (Sartorius, Shapiro, Kimura, & Barrett, 1972)
- Stephen LaBerge of Stanford University ran a series of experiments in the 80s that investigated lucid dreaming. In 1985, he performed a pilot study that demonstrated that time perception is the same as during wakefulness. Specifically, he had participants go into a state of lucid dreaming and count out ten seconds, signaling the start and end with pre-determined eye movements measured with the EOG.
- Negative Word-of-Mouth by Dissatisfied Consumers: A Pilot Study (Richins, 1983)
- A pilot study and randomized controlled trial of the mindful self‐compassion program (Neff & Germer, 2013)
- Pilot study of secondary prevention of posttraumatic stress disorder with propranolol (Pitman et al., 2002)
- In unstructured observations, the researcher records all relevant behavior without a system. There may be too much to record, and the behaviors recorded may not necessarily be the most important, so the approach is usually used as a pilot study to see what type of behaviors would be recorded.
- Perspectives of the use of smartphones in travel behavior studies: Findings from a literature review and a pilot study (Gadziński, 2018)
Further Information
- Lancaster, G. A., Dodd, S., & Williamson, P. R. (2004). Design and analysis of pilot studies: recommendations for good practice. Journal of evaluation in clinical practice, 10 (2), 307-312.
- Thabane, L., Ma, J., Chu, R., Cheng, J., Ismaila, A., Rios, L. P., … & Goldsmith, C. H. (2010). A tutorial on pilot studies: the what, why and how. BMC Medical Research Methodology, 10 (1), 1-10.
- Moore, C. G., Carter, R. E., Nietert, P. J., & Stewart, P. W. (2011). Recommendations for planning pilot studies in clinical and translational research. Clinical and translational science, 4 (5), 332-337.
Carassa, R. G., Bettin, P., Fiori, M., & Brancato, R. (1998). Viscocanalostomy: a pilot study. European journal of ophthalmology, 8 (2), 57-61.
Gadziński, J. (2018). Perspectives of the use of smartphones in travel behaviour studies: Findings from a literature review and a pilot study. Transportation Research Part C: Emerging Technologies, 88 , 74-86.
In J. (2017). Introduction of a pilot study. Korean Journal of Anesthesiology, 70 (6), 601–605. https://doi.org/10.4097/kjae.2017.70.6.601
LaBerge, S., LaMarca, K., & Baird, B. (2018). Pre-sleep treatment with galantamine stimulates lucid dreaming: A double-blind, placebo-controlled, crossover study. PLoS One, 13 (8), e0201246.
Leon, A. C., Davis, L. L., & Kraemer, H. C. (2011). The role and interpretation of pilot studies in clinical research. Journal of psychiatric research, 45 (5), 626–629. https://doi.org/10.1016/j.jpsychires.2010.10.008
Malmqvist, J., Hellberg, K., Möllås, G., Rose, R., & Shevlin, M. (2019). Conducting the Pilot Study: A Neglected Part of the Research Process? Methodological Findings Supporting the Importance of Piloting in Qualitative Research Studies. International Journal of Qualitative Methods. https://doi.org/10.1177/1609406919878341
Neff, K. D., & Germer, C. K. (2013). A pilot study and randomized controlled trial of the mindful self‐compassion program. Journal of Clinical Psychology, 69 (1), 28-44.
Pitman, R. K., Sanders, K. M., Zusman, R. M., Healy, A. R., Cheema, F., Lasko, N. B., … & Orr, S. P. (2002). Pilot study of secondary prevention of posttraumatic stress disorder with propranolol. Biological psychiatry, 51 (2), 189-192.
Richins, M. L. (1983). Negative word-of-mouth by dissatisfied consumers: A pilot study. Journal of Marketing, 47 (1), 68-78.
Sartorius, N., Shapiro, R., Kimura, M., & Barrett, K. (1972). WHO International Pilot Study of Schizophrenia1. Psychological medicine, 2 (4), 422-425.
Teijlingen, E. R; V. Hundley (2001). The importance of pilot studies, Social research UPDATE, (35)

How to Conduct Effective Pilot Tests: Tips and Tricks

Introduction
What is the main purpose of pilot testing, what qualitative research approaches rely on a pilot test, what are the benefits of a pilot study, how do you conduct a pilot study, steps after evaluation of pilot testing.
Successful qualitative research projects often begin with an essential step: pilot testing. Similar to beta testing for computer programs and online services, a pilot test, sometimes referred to as a small-scale preliminary study or pilot study, is to trial a design on a smaller scale before embarking on the main study.
Whether the focus is psychiatric research, a randomized controlled trial, or any other project, conducting a pilot test provides invaluable data, allowing research teams to refine their approach, optimize their evaluation criteria, and better predict the outcomes of a full-scale project.

Pilot testing, or the act of conducting a pilot study, is a crucial phase in the process, especially in qualitative and social science research . It serves as a preparatory step , a preliminary test, allowing researchers to evaluate, refine, and if necessary, redesign aspects of their study before full implementation, as well as determine the cost of a full study.
Pilot studies for assessing feasibility
One of the most significant purposes of a pilot test is to assess the feasibility of and identify potential design issues in the main study. It provides insights into whether a study's design is practical and achievable.
For instance, a research team might find that the originally planned method of interviewing is too time-consuming for a larger study or that participants may not be as forthcoming as hoped. Such insights from a feasibility study can save time, effort, and resources in the long run.
During pilot testing, a researcher can also determine how many or what kinds of participants might be needed for the main study to achieve meaningful results. It helps in ensuring that the target population is adequately represented without overwhelming the team with excessive data .

Refining research methods
A pilot study with a small sample size offers a testing ground for the instruments, tools, or techniques that the researchers plan to use.
For example, suppose a project involves using a new interview technique. In that case, the pilot group can provide feedback on the clarity of questions, the flow of the interview, or even the comfort level of the interaction. This feedback from a carefully selected group is vital in refining the tools to ensure that the main study captures the richest insights possible.
No design is perfect from the outset. Pilot testing acts as a litmus test, highlighting any potential challenges or issues that might arise during the full-scale project.
By identifying these hurdles in advance, researchers can preemptively devise solutions, ensuring smoother execution when the full study is conducted.

Gathering preliminary data
While the primary aim of pilot testing is not necessarily data collection for the main study, the knowledge garnered can be incredibly valuable for improving the current study or building toward a future study.
During the pilot phase of a research project, patterns, anomalies, or unexpected results can emerge. These can lead researchers to refine their propositions or research objectives, adjusting them to better align with observed realities.
Beyond its direct application to the design of the research, the initial findings from a pilot study can have broader, more strategic uses. When seeking funding for a full-scale project, having tangible results, even if they're preliminary, can lend credibility and weight to a research proposal.
Demonstrating that a concept has been tested, even on a small scale, and has yielded insightful data can make a compelling case to potential sponsors or stakeholders.
Pilot studies are a foundational component of many approaches in qualitative research . The exploratory and interpretative nature of qualitative methodologies means that research tools and strategies often benefit from preliminary testing to ensure their effectiveness.
In ethnographic research , where the goal is to study cultures and communities in-depth, pilot studies help researchers become familiar with the environment and its people. A brief preliminary visit can aid in understanding local dynamics, forging initial relationships, and refining methods to respect cultural sensitivities.
Grounded theory research , which seeks to develop theories grounded in empirical data, often starts with pilot studies. These preliminary tests aid in refining the interview protocols and sampling strategies, ensuring that the main study captures data that genuinely represents and informs the emerging theory.
Narrative research relies on the collection of stories from individuals about their experiences. Given the depth and nuance of personal narratives, a pilot test can be instrumental in determining the most effective ways to prompt and capture these stories while ensuring participants feel comfortable and understood.
Phenomenological research , which endeavors to understand the essence of participants' lived experiences around a phenomenon, often employs pilot testing to refine interview questions. It ensures that these questions elicit detailed, rich descriptions of experiences without leading or influencing the participants' responses.
In the field of case study research , where a particular case (or a few cases) is studied in-depth, pilot studies can help in delineating the boundaries of the case, deciding on the data collection methods , and anticipating potential challenges in data gathering or interpretation.
Lastly, psychiatric research, which delves into understanding mental processes, behaviors, and disorders, frequently employs pilot studies, especially when introducing new therapeutic techniques or interventions. A small-scale preliminary study can help identify any potential risks or issues before applying a new method or tool more broadly.
ATLAS.ti handles all research projects big and small
Qualitative analysis made easy with our powerful interface. See how with a free trial.
A pilot study, being a precursor to the main research, is not merely a preliminary step; it's a vital one for the researcher. These initial investigations through pilot studies, while smaller in scale, can prove consequential in terms of benefits they offer to the research process.
Ensuring methodological rigor
At its core, a pilot study is a testing ground for the tools, techniques, and strategies that will be employed in the main study. By test-driving these elements, you can identify weaknesses or areas of improvement in the methodology.
This helps in ensuring that when the full future study is conducted, the methods used are sound, reliable, and capable of yielding meaningful results. For instance, if an interview question consistently confuses participants during the pilot phase, you can revise it for clarity in the main study.
Optimizing resource allocation
One of the significant advantages of pilot testing is the potential for resource optimization. You can gain insights into the time, effort, and funds required for various activities, allowing for more accurate budgeting and scheduling.
Moreover, by preempting potential challenges or obstacles, a pilot study can prevent costly mistakes or oversights when scaling up to the full research. For example, discovering that a particular method is inefficient during the pilot phase can save countless hours and resources in the larger study.
Enhancing participant experience and ethical considerations
The qualitative researcher often delves deep into participants' personal experiences, emotions, and perceptions. A pilot study provides an opportunity to ensure that the research process is respectful, sensitive, and ethically sound.
By trialing interactions with a smaller group, those who conduct the study can refine their approach to ensure participants feel valued, understood, and comfortable. This not only enhances the quality of the insights collected but also fosters trust and rapport with the research subjects.
In sum, the benefits of conducting a pilot study extend far beyond mere preliminary testing. They fortify the research process, ensuring studies are rigorous, efficient, and ethically sound.
As such, pilot studies remain a cornerstone of robust qualitative research , laying the groundwork for meaningful and impactful insights.
A pilot study is an integral phase in the process , acting as a bridge between initial study design and the full-scale project by providing information for future guidance. To generate actionable insights and pave the way for a successful full study, there are key steps researchers need to follow.
Defining objectives and scope
Before diving into the pilot study, it's essential to clearly define its objectives. What specific aspects of the main study are you testing? Is it the data collection methods , the feasibility of the research design of the study, or the clarity of the interview questions?
When researchers answer these questions, they can gain insight on whether the pilot study remains manageable and yields specific, actionable insights from a completed pilot.
Selecting a representative sample
For a pilot study to be effective, the sample chosen should be a good representation of the target population. This doesn't mean it needs to be large; after all, it's a small-scale preliminary study.
However, it should capture the diversity and characteristics of the population to provide a realistic preview of how the research might unfold. Think about how your selected group addresses the needs of your study and evaluate whether their contributions to the research can help you answer your research questions.
Collecting and analyzing data
Once the objectives are set and the participants are chosen, the next step is data collection . Employ the same tools, methods, or interventions you plan to use in the research. Finally, analyze what you have collected with a keen eye for patterns, anomalies, or unexpected outcomes.
This phase isn't just about collecting preliminary insights for the main study but about gauging the effectiveness of your methods and drawing insights to refine your approach.

Reflections on the design of your study should follow pilot testing. The final design that you decide on should be comprehensively informed by any useful insight you gather from your pilot study.
Adjust study methods
Pilot studies are especially useful when they help identify design issues. You can adjust aspects of your study if you found they did not prove effective in collecting insights during your pilot study.
Identify opportunities for richer collection
Pilot testing is not merely a phase to iron out mistakes and shortcomings. A good pilot study should also allow you to identify aspects of your study that were successful and would be even more successful if fully optimized. If there are interview questions that resonated with research participants, for example, think about how those questions can be better utilized in a full-scale study.
Conduct and refine your research with ATLAS.ti
From study design to key insights, make ATLAS.ti the platform for your analysis. Download a free trial today.

- Open access
- Published: 31 October 2020
Guidance for conducting feasibility and pilot studies for implementation trials
- Nicole Pearson ORCID: orcid.org/0000-0003-2677-2327 1 , 2 ,
- Patti-Jean Naylor 3 ,
- Maureen C. Ashe 5 ,
- Maria Fernandez 4 ,
- Sze Lin Yoong 1 , 2 &
- Luke Wolfenden 1 , 2
Pilot and Feasibility Studies volume 6 , Article number: 167 ( 2020 ) Cite this article
81k Accesses
117 Citations
24 Altmetric
Metrics details
Implementation trials aim to test the effects of implementation strategies on the adoption, integration or uptake of an evidence-based intervention within organisations or settings. Feasibility and pilot studies can assist with building and testing effective implementation strategies by helping to address uncertainties around design and methods, assessing potential implementation strategy effects and identifying potential causal mechanisms. This paper aims to provide broad guidance for the conduct of feasibility and pilot studies for implementation trials.
We convened a group with a mutual interest in the use of feasibility and pilot trials in implementation science including implementation and behavioural science experts and public health researchers. We conducted a literature review to identify existing recommendations for feasibility and pilot studies, as well as publications describing formative processes for implementation trials. In the absence of previous explicit guidance for the conduct of feasibility or pilot implementation trials specifically, we used the effectiveness-implementation hybrid trial design typology proposed by Curran and colleagues as a framework for conceptualising the application of feasibility and pilot testing of implementation interventions. We discuss and offer guidance regarding the aims, methods, design, measures, progression criteria and reporting for implementation feasibility and pilot studies.
Conclusions
This paper provides a resource for those undertaking preliminary work to enrich and inform larger scale implementation trials.
Peer Review reports
The failure to translate effective interventions for improving population and patient outcomes into policy and routine health service practice denies the community the benefits of investment in such research [ 1 ]. Improving the implementation of effective interventions has therefore been identified as a priority of health systems and research agencies internationally [ 2 , 3 , 4 , 5 , 6 ]. The increased emphasis on research translation has resulted in the rapid emergence of implementation science as a scientific discipline, with the goal of integrating effective medical and public health interventions into health care systems, policies and practice [ 1 ]. Implementation research aims to do this via the generation of new knowledge, including the evaluation of the effectiveness of implementation strategies [ 7 ]. The term “implementation strategies” is used to describe the methods or techniques (e.g. training, performance feedback, communities of practice) used to enhance the adoption, implementation and/or sustainability of evidence-based interventions (Fig. 1 ) [ 8 , 9 ].

Conceptual role of implementation strategies in improving intervention implementation and patient and public health outcomes
While there has been a rapid increase in the number of implementation trials over the past decade, the quality of trials has been criticised, and the effects of the strategies for such trials on implementation, patient or public health outcomes have been modest [ 11 , 12 , 13 ]. To improve the likelihood of impact, factors that may impede intervention implementation should be considered during intervention development and across each phase of the research translation process [ 2 ]. Feasibility and pilot studies play an important role in improving the conduct and quality of a definitive randomised controlled trial (RCT) for both intervention and implementation trials [ 10 ]. For clinical or public health interventions, pilot and feasibility studies may serve to identify potential refinements to the intervention, address uncertainties around the feasibility of intervention trial methods, or test preliminary effects of the intervention [ 10 ]. In implementation research, feasibility and pilot studies perform the same functions as those for intervention trials, however with a focus on developing or refining implementation strategies, refining research methods for an implementation intervention trial, or undertake preliminary testing of implementation strategies [ 14 , 15 ]. Despite this, reviews of implementation studies appear to suggest that few full implementation randomised controlled trials have undertaken feasibility and pilot work in advance of a larger trial [ 16 ].
A range of publications provides guidance for the conduct of feasibility and pilot studies for conventional clinical or public health efficacy trials including Guidance for Exploratory Studies of complex public health interventions [ 17 ] and the Consolidated Standards of Reporting Trials (CONSORT 2010) for Pilot and Feasibility trials [ 18 ]. However, given the differences between implementation trials and conventional clinical or public health efficacy trials, the field of implementation science has identified the need for nuanced guidance [ 14 , 15 , 16 , 19 , 20 ]. Specifically, unlike traditional feasibility and pilot studies that may include the preliminary testing of interventions on individual clinical or public health outcomes, implementation feasibility and pilot studies that explore strategies to improve intervention implementation often require assessing changes across multiple levels including individuals (e.g. service providers or clinicians) and organisational systems [ 21 ]. Due to the complexity of influencing behaviour change, the role of feasibility and pilot studies of implementation may also extend to identifying potential causal mechanisms of change and facilitate an iterative process of refining intervention strategies and optimising their impact [ 16 , 17 ]. In addition, where conventional clinical or public health efficacy trials are typically conducted under controlled conditions and directed mostly by researchers, implementation trials are more pragmatic [ 15 ]. As is the case for well conducted effectiveness trials, implementation trials often require partnerships with end-users and at times, the prioritisation of end-user needs over methods (e.g. random assignment) that seek to maximise internal validity [ 15 , 22 ]. These factors pose additional challenges for implementation researchers and underscore the need for guidance on conducting feasibility and pilot implementation studies.
Given the importance of feasibility and pilot studies in improving implementation strategies and the quality of full-scale trials of those implementation strategies, our aim is to provide practice guidance for those undertaking formative feasibility or pilot studies in the field of implementation science. Specifically, we seek to provide guidance pertaining to the three possible purposes of undertaking pilot and feasibility studies, namely (i) to inform implementation strategy development, (ii) to assess potential implementation strategy effects and (iii) to assess the feasibility of study methods.
A series of three facilitated group discussions were conducted with a group comprising of the 6 members from Canada, the U.S. and Australia (authors of the manuscript) that were mutually interested in the use of feasibility and pilot trials in implementation science. Members included international experts in implementation and behavioural science, public health and trial methods, and had considerable experience in conducting feasibility, pilot and/ or implementation trials. The group was responsible for developing the guidance document, including identification and synthesis of pertinent literature, and approving the final guidance.
To inform guidance development, a literature review was undertaken in electronic bibliographic databases and google, to identify and compile existing recommendations and guidelines for feasibility and pilot studies broadly. Through this process, we identified 30 such guidelines and recommendations relevant to our aim [ 2 , 10 , 14 , 15 , 17 , 18 , 23 , 24 , 25 , 26 , 27 , 28 , 29 , 30 , 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 , 45 ]. In addition, seminal methods and implementation science texts recommended by the group were examined. These included the CONSORT 2010 Statement: extension to randomised pilot and feasibility trials [ 18 ], the Medical Research Council’s framework for development and evaluation of randomised controlled trials for complex interventions to improve health [ 2 ], the National Institute of Health Research (NIHR) definitions [ 39 ] and the Quality Enhancement Research Initiative (QUERI) Implementation Guide [ 4 ]. A summary of feasibility and pilot study guidelines and recommendations, and that of seminal methods and implementation science texts, was compiled by two authors. This document served as the primary discussion document in meetings of the group. Additional targeted searches of the literature were undertaken in circumstances where the identified literature did not provide sufficient guidance. The manuscript was developed iteratively over 9 months via electronic circulation and comment by the group. Any differences in views between reviewers was discussed and resolved via consensus during scheduled international video-conference calls. All members of the group supported and approved the content of the final document.
The broad guidance provided is intended to be used as supplementary resources to existing seminal feasibility and pilot study resources. We used the definitions of feasibility and pilot studies as proposed by Eldridge and colleagues [ 10 ]. These definitions propose that any type of study relating to the preparation for a main study may be classified as a “feasibility study”, and that the term “pilot” study represents a subset of feasibility studies that specifically look at a design feature proposed for the main trial, whether in part of in full, that is being conducted on a smaller scale [ 10 ]. In addition, when referring to pilot studies, unless explicitly stated otherwise, we will primarily focus on pilot trials using a randomised design. We focus on randomised trials as such designs are the most common trial design in implementation research, and randomised designs may provide the most robust estimates of the potential effect of implementation strategies [ 46 ]. Those undertaking pilot studies that employ non-randomised designs need to interpret the guidance provided in this context. We acknowledge, however, that using randomised designs can prove particularly challenging in the field of implementation science, where research is often undertaken in real-world contexts with pragmatic constraints.
We used the effectiveness-implementation hybrid trial design typology proposed by Curran and colleagues as the framework for conceptualising the application of feasibility testing of implementation interventions [ 47 ]. The typology makes an explicit distinction between the purpose and methods of implementation and conventional clinical (or public health efficacy) trials. Specifically, the first two of the three hybrid designs may be relevant for implementation feasibility or pilot studies. Hybrid Type 1 trials are those designed to test the effectiveness of an intervention on clinical or public health outcomes (primary aim) while conducting a feasibility or pilot study for future implementation via observing and gathering information regarding implementation in a real-world setting/situation (secondary aim) [ 47 ]. Hybrid Type 2 trials involve the simultaneous testing of both the clinical intervention and the testing or feasibility of a formed implementation intervention/strategy as co-primary aims. For this design, “testing” is inclusive of pilot studies with an outcome measure and related hypothesis [ 47 ]. Hybrid Type 3 trials are definitive implementation trials designed to test the effectiveness of an implementation strategy whilst also collecting secondary outcome data on clinical or public health outcomes on a population of interest [ 47 ]. As the implementation aim of the trial is a definitively powered trial, it was not considered relevant to the conduct of feasibility and pilot studies in the field and will not be discussed.
Embedding of feasibility and pilot studies within Type 1 and Type 2 effectiveness-implementation hybrid trials has been recommended as an efficient way to increase the availability of information and evidence to accelerate the field of implementation science and the development and testing of implementation strategies [ 4 ]. However, implementation feasibility and pilot studies are also undertaken as stand-alone exploratory studies and do not include effectiveness measures in terms of the patient or public health outcomes. As such, in addition to discussing feasibility and pilot trials embedded in hybrid trial designs, we will also refer to stand-alone implementation feasibility and pilot studies.
An overview of guidance (aims, design, measures, sample size and power, progression criteria and reporting) for feasibility and pilot implementation studies can be found in Table 1 .
Purpose (aims)
The primary objective of hybrid type 1 trial is to assess the effectiveness of a clinical or public health intervention (rather than an implementation strategy) on the patient or population health outcomes [ 47 ]. Implementation strategies employed in these trials are often designed to maximise the likelihood of an intervention effect [ 51 ], and may not be intended to represent the strategy that would (or could feasibly), be used to support implementation in more “real world” contexts. Specific aims of implementation feasibility or pilot studies undertaken as part of Hybrid Type 1 trials are therefore formative and descriptive as the implementation strategy has not been fully formed nor will be tested. Thus, the purpose of a Hybrid Type 1 feasibility study is generally to inform the development or refinement of the implementation strategy rather than to test potential effects or mechanisms [ 22 , 47 ]. An example of a Hybrid Type 1 trial by Cabassa and colleagues is provided in Additional file 1 [ 52 ].
In Hybrid Type 2 trial designs, there is a dual purpose to test: (i) the clinical or public health effectiveness of the intervention on clinical or public health outcomes (e.g. measure of disease or health behaviour) and (ii) test or measure the impact of the implementation strategy on implementation outcomes (e.g. adoption of health policy in a community setting) [ 53 ]. However, testing the implementation strategy on implementation outcomes may be a secondary aim in these trials and positioned as a pilot [ 22 ]. In Hybrid Type 2 trial designs, the implementation strategy is more developed than in Hybrid Type 1 trials, resembling that intended for future testing in a definitive implementation randomised controlled trial. The dual testing of the evidence-based intervention and implementation interventions or strategies in Hybrid Type 2 trial designs allows for direct assessment of potential effects of an implementation strategy and exploration of components of the strategy to further refine logic models. Additionally, such trials allow for assessments of the feasibility, utility, acceptability or quality of research methods for use in a planned definitive trial. An example of a Hybrid Type 2 trial design by Barnes and colleagues [ 54 ] is included in Additional file 2 .
Non-hybrid pilot implementation studies are undertaken in the absence of a broader effectiveness trial. Such studies typically occur when the effectiveness of a clinical or public health intervention is well established, but robust strategies to promote its broader uptake and integration into clinical or public health services remain untested [ 15 ]. In these situations, implementation pilot studies may test or explore specific trial methods for a future definitive randomised implementation trial. Similarly, a pilot implementation study may also be undertaken in a way that provides a more rigorous formative evaluation of hypothesised implementation strategy mechanisms [ 55 ], or potential impact of implementation strategies [ 56 ], using similar approaches to that employed in Hybrid Type 2 trials. Examples of potential aims for feasibility and pilot studies are outlined in Table 2 .
For implementation feasibility or pilot studies, as is the case for these types of studies in general, the selection of research design should be guided by the specific research question that the study is seeking to address [ 57 ]. Although almost any study design may be used, researchers should review the merits and potential threats to internal and external validity to help guide the selection of research design for feasibility/pilot testing [ 15 ].
As Hybrid Type 1 trials are primarily concerned with testing the effectiveness of an intervention (rather than implementation strategy), the research design will typically employ power calculations and randomisation procedures at the health outcome level to measure the effect on behaviour, symptoms, functional and/or other clinical or public health outcomes. Hybrid Type 1 feasibility studies may employ a variety of designs usually nested within the experimental group (those receiving the intervention and any form of an implementation support strategy) of the broader efficacy trial [ 47 ]. Consistent with the aims of Hybrid Type 1 feasibility and pilot studies, the research designs employed are likely to be non-comparative. Cross-sectional surveys, interviews or document review, qualitative research or mix methods approaches may be used to assess implementation contextual factors, such as barriers and enablers to implementation and/or the acceptability, perceived feasibility or utility of implementation strategies or research methods [ 47 ].
Pilot implementation studies as part of Hybrid Type 2 designs can make use of the comparative design of the broader effectiveness trial to examine the potential effects of the implementation strategy [ 47 ] and more robustly assess the implementation mechanisms, determinants and influence of broader contextual factors [ 53 ]. In this trial type, mixed method and qualitative methods may complement the findings of between group (implementation strategy arm versus comparison) quantitative comparisons, enable triangulation and provide more comprehensive evidence to inform implementation strategy development and assessment. Stand-alone implementation feasibility and pilot implementation studies are free from the constraints and opportunities of research embedded in broader effectiveness trials. As such, research can be designed in a way that best addresses the explicit implementation objectives of the study. Specifically, non-hybrid pilot studies can maximise the applicability of study findings for future definitive trials by employing methods to directly test trial methods such as recruitment or retention strategies [ 17 ], enabling estimates of implementation strategies effects [ 56 ] or capturing data to explicitly test logic models or strategy mechanisms.
The selection of outcome measures should be linked directly to the objectives of the feasibility or pilot study. Where appropriate, measures should be objective or have suitable psychometric properties, such as evidence of reliability and validity [ 58 , 59 ]. Public health evaluation frameworks often guide the choice of outcome measure in feasibility and pilot implementation work and include RE_AIM [ 60 ], PRECEDE_PROCEED [ 61 ], Proctor and colleagues framework on outcomes for implementation research [ 62 ] and more recently, the “Implementation Mapping” framework [ 63 ]. Recent work by McKay and colleagues suggests a minimum data set of implementation outcomes that includes measures of adoption, reach, dose, fidelity and sustainability [ 46 ]. We discuss selected measures below and provide a summary in Table 3 [ 46 ]. Such measures could be assessed using quantitative or qualitative or mixed methods [ 46 ].
Measures to assess potential implementation strategy effects
In addition to assessing the effects of an intervention on individual clinical or public health outcomes, Hybrid Type 2 trials (and some non-hybrid pilot studies) are interested in measures of the potential effects of an implementation strategy on desired organisational or clinician practice change such as adherence to a guideline, process, clinical standard or delivery of a program [ 62 ]. A range of potential outcomes that could be used to assess implementation strategy effects has been identified, including measures of adoption, reach, fidelity and sustainability [ 46 ]. These outcomes are described in Table 2 , including definitions and examples of how they may be applied to the implementation component of innovation being piloted. Standardised tools to assess these outcomes are often unavailable due to the unique nature of interventions being implemented and the variable (and changing) implementation context in which the research is undertaken [ 64 ]. Researchers may collect outcome data for these measures as part of environmental observations, self-completed checklists or administrative records, audio recording of client sessions or other methods suited to their study and context [ 62 ]. The limitations of such methods, however, need to be considered.
Measures to inform the design or development of the implementation strategy
Measures informing the design or development of the implementation strategy are potentially part of all types of feasibility and pilot implementation studies. An understanding of the determinants of implementation is critical to implementation strategy development. A range of theoretical determinant frameworks have been published which describe factors that may influence intervention implementation [ 65 ], and systematic reviews have been undertaken describing the psychometric properties of many of these measures [ 64 , 66 ]. McKay and colleagues have also identified a priority set of determinants for implementation trials that could be considered for use in implementation feasibility and pilot studies, including measures of context, acceptability, adaptability, feasibility, compatibility, cost, culture, dose, complexity and self-efficacy [ 46 ]. These determinants are described in Table 3 , including definitions and how such measures may be applied to an implementation feasibility or pilot study. Researchers should consider, however, the application of such measures to assess both the intervention that is being implemented (as in a conventional intervention feasibility and pilot study) and the strategy that is being employed to facilitate its implementation, given the importance of the interaction between these factors and implementation success [ 46 ]. Examples of the potential application of measures to both the intervention and its implementation strategies have been outlined elsewhere [ 46 ]. Although a range of quantitative tools could be used to measure such determinants [ 58 , 66 ], qualitative or mixed methods are generally recommended given the capacity of qualitative measures to provide depth to the interpretation of such evaluations [ 40 ].
Measures of potential implementation determinants may be included to build or enhance logic models (Hybrid Type 1 and 2 feasibility and pilot studies) and explore implementation strategy mechanisms (Hybrid Type 2 pilot studies and non-hybrid pilot studies) [ 67 ]. If exploring strategy mechanisms, a hypothesized logic model underpinning the implementation strategy should be articulated including strategy-mechanism linkages, which are required to guide the measurement of key determinants [ 55 , 63 ]. An important determinant which can complicate logic model specification and measurement is the process of adaptation—modifications to the intervention or its delivery (implementation), through the input of service providers or implementers [ 68 ]. Logic models should specify components of implementation strategies thought to be “core” to their effects and those which are thought to be “non-core” where adaptation may occur without adversely impacting on effects. Stirman and colleagues propose a method for assessing adaptations that could be considered for use in pilot and feasibility studies of implementation trials [ 69 ]. Figure 2 provides an example of some of the implementation logic model components that may be developed or refined as part of feasibility or pilot studies of implementation [ 15 , 63 ].

Example of components of an Implementation logic model
Measures to assess the feasibility of study methods
Measures of implementation feasibility and pilot study methods are similar to those of conventional studies for clinical or public health interventions. For example, standard measures of study participation and thresholds for study attrition (e.g. >20%) rates [ 73 ] can be employed in implementation studies [ 67 ]. Previous studies have also surveyed study data collectors to assess the success of blinding strategies [ 74 ]. Researchers may also consider assessing participation or adherence to implementation data collection procedures, the comprehension of survey items, data management strategies or other measures of feasibility of study methods [ 15 ].
Pilot study sample size and power
In effectiveness trials, power calculations and sample size decisions are primarily based on the detection of a clinically meaningful difference in measures of the effects of the intervention on the patient or public health outcomes such as behaviour, disease, symptomatology or functional outcomes [ 24 ]. In this context, the available study sample for implementation measures included in Hybrid Type 1 or 2 feasibility and pilot studies may be constrained by the sample and power calculations of the broader effectiveness trial in which they are embedded [ 47 ]. Nonetheless, a justification for the anticipated sample size for all implementation feasibility or pilot studies (hybrid or stand-alone) is recommended [ 18 ], to ensure that implementation measures and outcomes achieve sufficient estimates of precision to be useful. For Hybrid type 2 and relevant stand-alone implementation pilot studies, sample size calculations for implementation outcomes should seek to achieve adequate estimates of precision deemed sufficient to inform progression to a fully powered trial [ 18 ].
Progression criteria
Stating progression criteria when reporting feasibility and pilot studies is recommended as part of the CONSORT 2010 extension to randomised pilot and feasibility trials guidelines [ 18 ]. Generally, it is recommended that progression criteria should be set a priori and be specific to the feasibility measures, components and/or outcomes assessed in the study [ 18 ]. While little guidance is available, ideas around suitable progression criteria include assessment of uncertainties around feasibility, meeting recruitment targets, cost-effectiveness and refining causal hypotheses to be tested in future trials [ 17 ]. When developing progression criteria, the use of guidelines is suggested rather than strict thresholds [ 18 ], in order to allow for appropriate interpretation and exploration of potential solutions, for example, the use of a traffic light system with varying levels of acceptability [ 17 , 24 ]. For example, Thabane and colleagues recommend that, in general, the outcome of a pilot study can be one of the following: (i) stop—main study not feasible (red); (ii) continue, but modify protocol—feasible with modifications (yellow); (iii) continue without modifications, but monitor closely—feasible with close monitoring and (iv) continue without modifications (green) (44)p5.
As the goal of Hybrid Type 1 implementation component is usually formative, it may not be necessary to set additional progression criteria in terms of the implementation outcomes and measures examined. As Hybrid Type 2 trials test an intervention and can pilot an implementation strategy, criteria for these and non-hybrid pilot studies may set progression criteria based on evidence of potential effects but may also consider the feasibility of trial methods, service provider, organisational or patient (or community) acceptability, fit with organisational systems and cost-effectiveness [ 17 ]. In many instances, the progression of implementation pilot studies will often require the input and agreement of stakeholders [ 27 ]. As such, the establishment of progression criteria and the interpretation of pilot and feasibility study findings in the context of such criteria require stakeholder input [ 27 ].
Reporting suggestions
As formal reporting guidelines do not exist for hybrid trial designs, we would recommend that feasibility and pilot studies as part of hybrid designs draw upon best practice recommendations from relevant reporting standards such as the CONSORT extension for randomised pilot and feasibility trials, the Standards for Reporting Implementation Studies (STaRI) guidelines and the Template for Intervention Description and Replication (TIDieR) guide as well as any other design relevant reporting standards [ 48 , 50 , 75 ]. These, and further reporting guidelines, specific to the particular research design chosen, can be accessed as part of the EQUATOR (Enhancing the QUAility and Transparency Of health Research) network—a repository for reporting guidance [ 76 ]. In addition, researchers should specify the type of implementation feasibility or pilot study being undertaken using accepted definitions. If applicable, specification and justification behind the choice of hybrid trial design should also be stated. In line with existing recommendations for reporting of implementation trials generally, reporting on the referent of outcomes (e.g. specifying if the measure in relation to the specific intervention or the implementation strategy) [ 62 ], is also particularly pertinent when reporting hybrid trial designs.
Concerns are often raised regarding the quality of implementation trials and their capacity to contribute to the collective evidence base [ 3 ]. Although there have been many recent developments in the standardisation of guidance for implementation trials, information on the conduct of feasibility and pilot studies for implementation interventions remains limited, potentially contributing to a lack of exploratory work in this area and a limited evidence base to inform effective implementation intervention design and conduct [ 15 ]. To address this, we synthesised the existing literature and provide commentary and guidance for the conduct of implementation feasibility and pilot studies. To our knowledge, this work is the first to do so and is an important first step to the development of standardised guidelines for implementation-related feasibility and pilot studies.
Availability of data and materials
Not applicable.
Abbreviations
Randomised controlled trial
Consolidated Standards of Reporting Trials
Enhancing the QUAility and Transparency Of health Research
Standards for Reporting Implementation Studies
Strengthening the Reporting of Observational Studies in Epidemiology
Template for Intervention Description and Replication
National Institute of Health Research
Quality Enhancement Research Initiative
Bauer MS, Damschroder L, Hagedorn H, Smith J, Kilbourne AM. An introduction to implementation science for the non-specialist. BMC Psychol. 2015;3:32.
Article Google Scholar
Craig P, Dieppe P, Macintyre S, Michie S, Nazareth I, Petticrew M, et al. Developing and evaluating complex interventions: the new Medical Research Council guidance. BMJ. 2008;337:a1655.
Eccles MP, Armstrong D, Baker R, Cleary K, Davies H, Davies S, et al. An implementation research agenda. Implement Sci. 2009;4:18.
Department of Veterans Health Administration. Implementation Guide. Health Services Research & Development, Quality Enhancement Research Initiative. Updated 2013.
Peters DH, Nhan TT, Adam T. Implementation research: a practical guide; 2013.
Google Scholar
Neta G, Sanchez MA, Chambers DA, Phillips SM, Leyva B, Cynkin L, et al. Implementation science in cancer prevention and control: a decade of grant funding by the National Cancer Institute and future directions. Implement Sci. 2015;10:4.
Foy R, Sales A, Wensing M, Aarons GA, Flottorp S, Kent B, et al. Implementation science: a reappraisal of our journal mission and scope. Implement Sci. 2015;10:51.
Proctor EK, Powell BJ, McMillen JC. Implementation strategies: recommendations for specifying and reporting. Implement Sci. 2013;8:139.
Leeman J, Birken SA, Powell BJ, Rohweder C, Shea CM. Beyond "implementation strategies": classifying the full range of strategies used in implementation science and practice. Implement Sci. 2017;12(1):125.
Eldridge SM, Lancaster GA, Campbell MJ, Thabane L, Hopewell S, Coleman CL, et al. Defining feasibility and pilot studies in preparation for randomised controlled trials: development of a conceptual framework. PLoS One. 2016;11(3):e0150205.
Article CAS Google Scholar
Powell BJ, McMillen JC, Proctor EK, Carpenter CR, Griffey RT, Bunger AC, et al. A compilation of strategies for implementing clinical innovations in health and mental health. Med Care Res Rev. 2012;69(2):123–57.
Powell BJ, Waltz TJ, Chinman MJ, Damschroder LJ, Smith JL, Matthieu MM, et al. A refined compilation of implementation strategies: results from the expert recommendations for implementing change (ERIC) project. Implement Sci. 2015;10:21.
Lewis CC, Stanick C, Lyon A, Darnell D, Locke J, Puspitasari A, et al. Proceedings of the fourth biennial conference of the Society for Implementation Research Collaboration (SIRC) 2017: implementation mechanisms: what makes implementation work and why? Part 1. Implement Sci. 2018;13(Suppl 2):30.
Levati S, Campbell P, Frost R, Dougall N, Wells M, Donaldson C, et al. Optimisation of complex health interventions prior to a randomised controlled trial: a scoping review of strategies used. Pilot Feasibility Stud. 2016;2:17.
Bowen DJ, Kreuter M, Spring B, Cofta-Woerpel L, Linnan L, Weiner D, et al. How we design feasibility studies. Am J Prev Med. 2009;36(5):452–7.
Eccles M, Grimshaw J, Walker A, Johnston M, Pitts N. Changing the behavior of healthcare professionals: the use of theory in promoting the uptake of research findings. J Clin Epidemiol. 2005;58(2):107–12.
Hallingberg B, Turley R, Segrott J, Wight D, Craig P, Moore L, et al. Exploratory studies to decide whether and how to proceed with full-scale evaluations of public health interventions: a systematic review of guidance. Pilot Feasibility Stud. 2018;4:104.
Eldridge SM, Chan CL, Campbell MJ, Bond CM, Hopewell S, Thabane L, et al. CONSORT 2010 statement: extension to randomised pilot and feasibility trials. Pilot Feasibility Stud. 2016;2:64.
Proctor EK, Powell BJ, Baumann AA, Hamilton AM, Santens RL. Writing implementation research grant proposals: ten key ingredients. Implement Sci. 2012;7:96.
Stetler CB, Legro MW, Wallace CM, Bowman C, Guihan M, Hagedorn H, et al. The role of formative evaluation in implementation research and the QUERI experience. J Gen Intern Med. 2006;21(Suppl 2):S1–8.
Aarons GA, Hurlburt M, Horwitz SM. Advancing a conceptual model of evidence-based practice implementation in public service sectors. Admin Pol Ment Health. 2011;38(1):4–23.
Johnson AL, Ecker AH, Fletcher TL, Hundt N, Kauth MR, Martin LA, et al. Increasing the impact of randomized controlled trials: an example of a hybrid effectiveness-implementation design in psychotherapy research. Transl Behav Med. 2018.
Arain M, Campbell MJ, Cooper CL, Lancaster GA. What is a pilot or feasibility study? A review of current practice and editorial policy. BMC Med Res Methodol. 2010;10(1):67.
Avery KN, Williamson PR, Gamble C, O’Connell Francischetto E, Metcalfe C, Davidson P, et al. Informing efficient randomised controlled trials: exploration of challenges in developing progression criteria for internal pilot studies. BMJ Open. 2017;7(2):e013537.
Bell ML, Whitehead AL, Julious SA. Guidance for using pilot studies to inform the design of intervention trials with continuous outcomes. J Clin Epidemiol. 2018;10:153–7.
Billingham SAM, Whitehead AL, Julious SA. An audit of sample sizes for pilot and feasibility trials being undertaken in the United Kingdom registered in the United Kingdom clinical research Network database. BMC Med Res Methodol. 2013;13(1):104.
Bugge C, Williams B, Hagen S, Logan J, Glazener C, Pringle S, et al. A process for decision-making after pilot and feasibility trials (ADePT): development following a feasibility study of a complex intervention for pelvic organ prolapse. Trials. 2013;14:353.
Charlesworth G, Burnell K, Hoe J, Orrell M, Russell I. Acceptance checklist for clinical effectiveness pilot trials: a systematic approach. BMC Med Res Methodol. 2013;13(1):78.
Eldridge SM, Costelloe CE, Kahan BC, Lancaster GA, Kerry SM. How big should the pilot study for my cluster randomised trial be? Stat Methods Med Res. 2016;25(3):1039–56.
Fletcher A, Jamal F, Moore G, Evans RE, Murphy S, Bonell C. Realist complex intervention science: applying realist principles across all phases of the Medical Research Council framework for developing and evaluating complex interventions. Evaluation (Lond). 2016;22(3):286–303.
Hampson LV, Williamson PR, Wilby MJ, Jaki T. A framework for prospectively defining progression rules for internal pilot studies monitoring recruitment. Stat Methods Med Res. 2018;27(12):3612–27.
Kraemer HC, Mintz J, Noda A, Tinklenberg J, Yesavage JA. Caution regarding the use of pilot studies to guide power calculations for study proposals. Arch Gen Psychiatry. 2006;63(5):484–9.
Smith LJ, Harrison MB. Framework for planning and conducting pilot studies. Ostomy Wound Manage. 2009;55(12):34–48.
Lancaster GA, Dodd S, Williamson PR. Design and analysis of pilot studies: recommendations for good practice. J Eval Clin Pract. 2004;10(2):307–12.
Leon AC, Davis LL, Kraemer HC. The role and interpretation of pilot studies in clinical research. J Psychiatr Res. 2011;45(5):626–9.
Medical Research Council. A framework for development and evaluation of RCTs for complex interventions to improve health. London: Medical Research Council; 2000.
Möhler R, Bartoszek G, Meyer G. Quality of reporting of complex healthcare interventions and applicability of the CReDECI list - a survey of publications indexed in PubMed. BMC Med Res Methodol. 2013;13(1):125.
Möhler R, Köpke S, Meyer G. Criteria for reporting the development and evaluation of complex interventions in healthcare: revised guideline (CReDECI 2). Trials. 2015;16(1):204.
National Institute for Health Research. Definitions of feasibility vs pilot stuides [Available from: https://www.nihr.ac.uk/documents/guidance-on-applying-for-feasibility-studies/20474 ].
O'Cathain A, Hoddinott P, Lewin S, Thomas KJ, Young B, Adamson J, et al. Maximising the impact of qualitative research in feasibility studies for randomised controlled trials: guidance for researchers. Pilot Feasibility Stud. 2015;1:32.
Shanyinde M, Pickering RM, Weatherall M. Questions asked and answered in pilot and feasibility randomized controlled trials. BMC Med Res Methodol. 2011;11(1):117.
Teare MD, Dimairo M, Shephard N, Hayman A, Whitehead A, Walters SJ. Sample size requirements to estimate key design parameters from external pilot randomised controlled trials: a simulation study. Trials. 2014;15(1):264.
Thabane L, Lancaster G. Improving the efficiency of trials using innovative pilot designs: the next phase in the conduct and reporting of pilot and feasibility studies. Pilot Feasibility Stud. 2017;4(1):14.
Thabane L, Ma J, Chu R, Cheng J, Ismaila A, Rios LP, et al. A tutorial on pilot studies: the what, why and how. BMC Med Res Methodol. 2010;10:1.
Westlund E. E.a. S. The nonuse, misuse, and proper use of pilot studies in experimental evaluation research. Am J Eval. 2016;38(2):246–61.
McKay H, Naylor PJ, Lau E, Gray SM, Wolfenden L, Milat A, et al. Implementation and scale-up of physical activity and behavioural nutrition interventions: an evaluation roadmap. Int J Behav Nutr Phys Act. 2019;16(1):102.
Curran GM, Bauer M, Mittman B, Pyne JM, Stetler C. Effectiveness-implementation hybrid designs: combining elements of clinical effectiveness and implementation research to enhance public health impact. Med Care. 2012;50(3):217–26.
Equator Network. Standards for reporting implementation studies (StaRI) statement 2017 [Available from: http://www.equator-network.org/reporting-guidelines/stari-statement/ ].
Vandenbroucke JP, von Elm E, Altman DG, Gøtzsche PC, Mulrow CD, Pocock SJ, et al. Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): explanation and elaboration. PLoS Med. 2007;4(10):e297–e.
Hoffmann TC, Glasziou PP, Boutron I, Milne R, Perera R, Moher D, et al. Better reporting of interventions: template for intervention description and replication (TIDieR) checklist and guide. BMJ. 2014;348:g1687.
Schliep ME, Alonzo CN, Morris MA. Beyond RCTs: innovations in research design and methods to advance implementation science. Evid Based Commun Assess Inter. 2017;11(3-4):82–98.
Cabassa LJ, Stefancic A, O'Hara K, El-Bassel N, Lewis-Fernández R, Luchsinger JA, et al. Peer-led healthy lifestyle program in supportive housing: study protocol for a randomized controlled trial. Trials. 2015;16:388.
Landes SJ, McBain SA, Curran GM. Reprint of: An introduction to effectiveness-implementation hybrid designs. J Psychiatr Res. 2020;283:112630.
Barnes C, Grady A, Nathan N, Wolfenden L, Pond N, McFayden T, Ward DS, Vaughn AE, Yoong SL. A pilot randomised controlled trial of a web-based implementation intervention to increase child intake of fruit and vegetables within childcare centres. Pilot and Feasibility Studies. 2020. https://doi.org/10.1186/s40814-020-00707-w .
Lewis CC, Klasnja P, Powell BJ, Lyon AR, Tuzzio L, Jones S, et al. From classification to causality: advancing understanding of mechanisms of change in implementation science. Front Public Health. 2018;6:136.
Department of Veterans Health Affairs. Implementation Guide. Health Services Research & Development, Quality Enhancement Research Initiative. 2013.
Moore GF, Audrey S, Barker M, Bond L, Bonell C, Hardeman W, et al. Process evaluation of complex interventions: Medical Research Council guidance. BMJ. 2015;350:h1258.
Weiner BJ, Lewis CC, Stanick C, Powell BJ, Dorsey CN, Clary AS, et al. Psychometric assessment of three newly developed implementation outcome measures. Implement Sci. 2017;12(1):108.
Lewis CC, Mettert KD, Dorsey CN, Martinez RG, Weiner BJ, Nolen E, et al. An updated protocol for a systematic review of implementation-related measures. Syst Rev. 2018;7(1):66.
Glasgow RE, Klesges LM, Dzewaltowski DA, Estabrooks PA, Vogt TM. Evaluating the impact of health promotion programs: using the RE-AIM framework to form summary measures for decision making involving complex issues. Health Educ Res. 2006;21(5):688–94.
Green L, Kreuter M. Health promotion planning: an educational and ecological approach. Mountain View: Mayfield Publishing; 1999.
Proctor E, Silmere H, Raghavan R, Hovmand P, Aarons G, Bunger A, et al. Outcomes for implementation research: conceptual distinctions, measurement challenges, and research agenda. Admin Pol Ment Health. 2011;38(2):65–76.
Fernandez ME, Ten Hoor GA, van Lieshout S, Rodriguez SA, Beidas RS, Parcel G, et al. Implementation mapping: using intervention mapping to develop implementation strategies. Front Public Health. 2019;7:158.
Lewis CC, Weiner BJ, Stanick C, Fischer SM. Advancing implementation science through measure development and evaluation: a study protocol. Implement Sci. 2015;10:102.
Damschroder LJ, Aron DC, Keith RE, Kirsh SR, Alexander JA, Lowery JC. Fostering implementation of health services research findings into practice: a consolidated framework for advancing implementation science. Implement Sci. 2009;4:50.
Clinton-McHarg T, Yoong SL, Tzelepis F, Regan T, Fielding A, Skelton E, et al. Psychometric properties of implementation measures for public health and community settings and mapping of constructs against the consolidated framework for implementation research: a systematic review. Implement Sci. 2016;11(1):148.
Moore CG, Carter RE, Nietert PJ, Stewart PW. Recommendations for planning pilot studies in clinical and translational research. Clin Transl Sci. 2011;4(5):332–7.
Pérez D, Van der Stuyft P, Zabala MC, Castro M, Lefèvre P. A modified theoretical framework to assess implementation fidelity of adaptive public health interventions. Implement Sci. 2016;11(1):91.
Stirman SW, Miller CJ, Toder K, Calloway A. Development of a framework and coding system for modifications and adaptations of evidence-based interventions. Implement Sci. 2013;8:65.
Carroll C, Patterson M, Wood S, Booth A, Rick J, Balain S. A conceptual framework for implementation fidelity. Implement Sci. 2007;2:40.
Durlak JA, DuPre EP. Implementation matters: a review of research on the influence of implementation on program outcomes and the factors affecting implementation. Am J Community Psychol. 2008;41(3-4):327–50.
Saunders RP, Evans MH, Joshi P. Developing a process-evaluation plan for assessing health promotion program implementation: a how-to guide. Health Promot Pract. 2005;6(2):134–47.
Higgins JP, Altman DG, Gøtzsche PC, Jüni P, Moher D, Oxman AD, et al. The Cochrane Collaboration's tool for assessing risk of bias in randomised trials. BMJ. 2011;343:d5928.
Wyse RJ, Wolfenden L, Campbell E, Brennan L, Campbell KJ, Fletcher A, et al. A cluster randomised trial of a telephone-based intervention for parents to increase fruit and vegetable consumption in their 3- to 5-year-old children: study protocol. BMC Public Health. 2010;10:216.
Consort Transparent Reporting of Trials. Pilot and Feasibility Trials 2016 [Available from: http://www.consort-statement.org/extensions/overview/pilotandfeasibility ].
Equator Network. Ehancing the QUAlity and Transparency Of health Research. [Avaliable from: https://www.equator-network.org/ ].
Download references
Acknowledgements
Associate Professor Luke Wolfenden receives salary support from a NHMRC Career Development Fellowship (grant ID: APP1128348) and Heart Foundation Future Leader Fellowship (grant ID: 101175). Dr Sze Lin Yoong is a postdoctoral research fellow funded by the National Heart Foundation. A/Prof Maureen C. Ashe is supported by the Canada Research Chairs program.
Author information
Authors and affiliations.
School of Medicine and Public Health, University of Newcastle, University Drive, Callaghan, NSW 2308, Australia
Nicole Pearson, Sze Lin Yoong & Luke Wolfenden
Hunter New England Population Health, Locked Bag 10, Wallsend, NSW 2287, Australia
School of Exercise Science, Physical and Health Education, Faculty of Education, University of Victoria, PO Box 3015 STN CSC, Victoria, BC, V8W 3P1, Canada
Patti-Jean Naylor
Center for Health Promotion and Prevention Research, University of Texas Health Science Center at Houston School of Public Health, Houston, TX, 77204, USA
Maria Fernandez
Department of Family Practice, University of British Columbia (UBC) and Centre for Hip Health and Mobility, University Boulevard, Vancouver, BC, V6T 1Z3, Canada
Maureen C. Ashe
You can also search for this author in PubMed Google Scholar
Contributions
NP and LW led the development of the manuscript. NP, LW, NP, MCA, PN, MF and SY contributed to the drafting and final approval of the manuscript.
Corresponding author
Correspondence to Nicole Pearson .
Ethics declarations
Ethics approval and consent to participate, consent for publication, competing interests.
The authors have no financial or non-financial interests to declare .
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1..
Example of a Hybrid Type 1 trial. Summary of publication by Cabassa et al.
Additional file 2.
Example of a Hybrid Type 2 trial. Summary of publication by Barnes et al.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Pearson, N., Naylor, PJ., Ashe, M.C. et al. Guidance for conducting feasibility and pilot studies for implementation trials. Pilot Feasibility Stud 6 , 167 (2020). https://doi.org/10.1186/s40814-020-00634-w
Download citation
Received : 08 January 2020
Accepted : 18 June 2020
Published : 31 October 2020
DOI : https://doi.org/10.1186/s40814-020-00634-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Feasibility
- Hybrid trial designs
- Implementation science
Pilot and Feasibility Studies
ISSN: 2055-5784
- Submission enquiries: Access here and click Contact Us
- General enquiries: [email protected]

Why Is a Pilot Study Important in Research?
Are you working on a new research project ? We know that you are excited to start, but before you dive in, make sure your study is feasible. You don’t want to end up having to process too many samples at once or realize you forgot to add an essential question to your questionnaire.
What is a Pilot Study?
You can determine the feasibility of your research design, with a pilot study before you start. This is a preliminary, small-scale “rehearsal” in which you test the methods you plan to use for your research project. You will use the results to guide the methodology of your large-scale investigation. Pilot studies should be performed for both qualitative and quantitative studies. Here, we discuss the importance of the pilot study and how it will save you time, frustration and resources.
“ You never test the depth of a river with both feet ” – African proverb
Components of a Pilot Study
Whether your research is a clinical trial of a medical treatment or a survey in the form of a questionnaire, you want your study to be informative and add value to your research field. Things to consider in your pilot study include:
- Sample size and selection. Your data needs to be representative of the target study population. You should use statistical methods to estimate the feasibility of your sample size.
- Determine the criteria for a successful pilot study based on the objectives of your study. How will your pilot study address these criteria?
- When recruiting subjects or collecting samples ensure that the process is practical and manageable.
- Always test the measurement instrument . This could be a questionnaire, equipment, or methods used. Is it realistic and workable? How can it be improved?
- Data entry and analysis . Run the trial data through your proposed statistical analysis to see whether your proposed analysis is appropriate for your data set.
- Create a flow chart of the process.
How to Conduct a Pilot Study
Conducting a pilot study is an essential step in many research projects. Here’s a general guide on how to conduct a pilot study:
Step 1: Define Objectives
Inspect what specific aspects of your main study do you want to test or evaluate in your pilot study.
Step 2: Evaluate Sample Size
Decide on an appropriate sample size for your pilot study. This can be smaller than your main study but should still be large enough to provide meaningful feedback.
Step 3: Select Participants
Choose participants who are similar to those you’ll include in the main study. Ensure they match the demographics and characteristics of your target population.
Step 4: Prepare Materials
Develop or gather all the materials needed for the study, such as surveys, questionnaires, protocols, etc.
Step 5: Explain the Purpose of the Study
Briefly explain the purpose and implementation method of the pilot study to participants. Pay attention to the study duration to help you refine your timeline for the main study.
Step 6: Gather Feedback
Gather feedback from participants through surveys, interviews, or discussions. Ask about their understanding of the questions, clarity of instructions, time taken, etc.
Step 7: Analyze Results
Analyze the collected data and identify any trends or patterns. Take note of any unexpected issues, confusion, or problems that arise during the pilot.
Step 8: Report Findings
Write a brief report detailing the process, results, and any changes made.
Based on the results observed in the pilot study, make necessary adjustments to your study design, materials, procedures, etc. Furthermore, ensure you are following ethical guidelines for research, even in a pilot study.
Ready to test your understanding on conducting a pilot study? Take our short quiz today!
Fill the Details to Check Your Score

Importance of Pilot Study in Research
Pilot studies should be routinely incorporated into research design s because they:
- Help define the research question
- Test the proposed study design and process. This could alert you to issues which may negatively affect your project.
- Educate yourself on different techniques related to your study.
- Test the safety of the medical treatment in preclinical trials on a small number of participants. This is an essential step in clinical trials.
- Determine the feasibility of your study, so you don’t waste resources and time.
- Provide preliminary data that you can use to improve your chances for funding and convince stakeholders that you have the necessary skills and expertise to successfully carry out the research.
Are Pilot Studies Always Necessary?
We recommend pilot studies for all research. Scientific research does not always go as planned; therefore, you should optimize the process to minimize unforeseen events. Why risk disastrous and expensive mistakes that could have been discovered and corrected in a pilot study?
An Essential Component for Good Research Design
Pilot work not only gives you a chance to determine whether your project is feasible but also an opportunity to publish its results. You have an ethical and scientific obligation to get your information out to assist other researchers in making the most of their resources.
A successful pilot study does not ensure the success of a research project. However, it does help you assess your approach and practice the necessary techniques required for your project. It will give you an indication of whether your project will work. Would you start a research project without a pilot study? Let us know in the comments section below.

But it depends on the nature of the research, I suppose.
Awesome document
Good document
I totally agree with this article that pilot study helps the researcher be sure how feasible his research idea is. And is well worth the time, as it saves future time wastage.
Great article, it is always wise to carry out that test before putting out the Main stuff. It saves you time and future embarrasment.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Reporting Research
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for data interpretation
In research, choosing the right approach to understand data is crucial for deriving meaningful insights.…

Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right approach
The process of choosing the right research design can put ourselves at the crossroads of…

- Career Corner
Unlocking the Power of Networking in Academic Conferences
Embarking on your first academic conference experience? Fear not, we got you covered! Academic conferences…

Research Recommendations – Guiding policy-makers for evidence-based decision making
Research recommendations play a crucial role in guiding scholars and researchers toward fruitful avenues of…

- AI in Academia
Disclosing the Use of Generative AI: Best practices for authors in manuscript preparation
The rapid proliferation of generative and other AI-based tools in research writing has ignited an…
Intersectionality in Academia: Dealing with diverse perspectives
Meritocracy and Diversity in Science: Increasing inclusivity in STEM education
Avoiding the AI Trap: Pitfalls of relying on ChatGPT for PhD applications

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What should universities' stance be on AI tools in research and academic writing?
- What is pilot testing?
Last updated
12 February 2023
Reviewed by
Tanya Williams
When you have a new project in mind, conducting a pilot test can help you get a better feel for how it will ultimately perform. However, a strong understanding of what pilot testing is, how it works, and what you may need to do with it is essential to the overall performance of your test and your product.
Make research less tedious
Dovetail streamlines research to help you uncover and share actionable insights
- Why pilot testing is important
In many cases, a pilot test can go a long way toward providing more information and deeper insights into your future study.
Learn more about potential costs
You will likely have a specific budget related to your project. Therefore, you will want to get the best possible results from your study within that budget, but you may not be exactly sure how the budget constraints will ultimately impact your project.
Conducting a pilot study can help you determine what the cost of a larger study will look like, which can ensure that you manage your sample size and testing plans accordingly.
Provide key information about possible issues
A pilot test can help provide deeper insights into any issues you might face when running your larger study. With a pilot test, you can learn more about the effectiveness of the methods you've chosen, the feasibility of gathering the information you need, and the practicality of your study. Furthermore, you may notice any possible problems with your study early, which means you can adjust your methods when you begin that larger-scale testing.
Determine feasibility
In some cases, you may find through pilot testing that the study you want to perform simply isn't realistic, based on the availability of key data and/or the way your brand functions. For example, you might have a hard time getting real-world answers from your customers, or you might discover that customers aren't using your products the way you had hoped.
By determining feasibility through the pilot test, you can avoid wasting money on a larger-scale study that might not provide you with the information you need.
Shape your research
Sometimes, your pilot study may quickly reveal that the information you thought to be true, actually isn't. You may discover that customers are looking for different features or options than you initially expected, or that your customers aren't interested in a specific product.
On the other hand, your pilot study may uncover that customers have a much deeper use for some feature or product than you thought, making efforts to remove it counterproductive. With a pilot study, you can shape your future research efforts more effectively.
- Uses for pilot studies
Pilot studies can be used in a variety of ways. Some of these include:
Trials of new products
Testing customer focus groups
Conducting product testing
Seeking more information about your target audience
Market research
- Misuses of pilot studies
While pilot studies have a number of critical uses, they can, in some cases, be misused. Take a look at these common challenges that can occur during pilot studies, interfering with accurate data collection .
Misreporting of data : can make it difficult for researchers to see the information they originally sought to obtain through pilot testing
Improper testing methods : pilot studies may, in some cases, use inaccurate or inappropriate testing methods, causing researchers to arrive at errant conclusions
Inaccurate predictions : if used to inform future testing methods, they may create bias in the final results of the study
Properly conducting pilot studies is essential to using that data and information correctly in the future. The data is only as good as the methodology used to procure it.
- Objectives of pilot testing
Pilot testing has several objectives, including:
Identify the potential cost of a larger study
Determine the feasibility of a study
Get a closer look at risks, time involved, and ultimate performance in a larger study
- How to do pilot testing
Conducting a pilot test involves several key steps, such as:
Determine the objective of the study
Choose key data points to analyze based on the study's goals
Prepare for the pilot test, including making sure that all researchers or testers are well informed
Deploy the pilot test, including all research
Evaluate the results
Use the results of the pilot test to make any changes to the larger test
- Steps after evaluation of pilot testing
Once you have evaluated your pilot test, there are several steps you may want to take. These can include:
Identifying any potential risks associated with the study and taking steps to mitigate them
Analyzing the results of your pilot and the feasibility of continuing
Developing methods for collecting and analyzing data for your larger study, including making any changes indicated by the product pilot test
- The benefits of pilot testing
Pilot testing offers a number of important benefits:
Learn more about your study methods and get a feel for what your actual test will look like
Avoid costly errors that could interfere with your results or prevent you from finishing your study
Make sure your study is realistic and feasible based on current data and capability
Get early insights into the possible results of a larger-scale test
Often, the results of a pilot test can help inform future testing methodology or shape the course of the future study.
- Best practices for pilot testing
Understanding good practices for pilot testing can help you build a test that reflects the current needs and status of your organization. It’s important to consider the following:
Make sure all personnel are fully trained and understand the data they need to collect and methods for reporting and collecting that data. Incorrect data collection and/or analysis can interfere with your study and make it more difficult to get the information you need.
Identify clear key metrics for later analysis. Make sure you know what you are planning to analyze and what you want to learn from the pilot study.
Base results on evidence, rather than simply collecting evidence to support a hypothesis . Using unbiased data collection methods can make a big difference in the outcome of your study.
Use pilot testing results to make changes to your future study that can help cut costs and improve outcomes.
Remain open to different outcomes in the final test. While pilot testing can provide some insights, it may not provide the same information as a larger-scale test, especially when you conduct a pilot test with a limited segment of your target audience.
- Pilot testing vs. beta testing
During pilot testing, researchers are able to gather data prior to releasing or deploying a product. A pilot test is designed to offer insights into the product and/or customers.
A beta test, on the other hand, actively deploys a version of the product into the customer’s environment and allows them to use it and provide feedback. Beta testing is generally conducted when a product is nearing completion, while a pilot test may be conducted early in the process.
Why is it called a pilot test?
A pilot test is an initial test or a miniature version of a larger-scale study or project. The term "pilot" means to test a plan, project, or other strategy before implementing it more fully across an organization. A pilot test is generally conducted before beta testing in the case of a product or software release.
What is pilot testing of a product?
A pilot test invites a limited group of users to test out a new product or solution and provide feedback. During a pilot test, the product will be released to a very limited group of reviewers, often hand-picked by the testing organization.
What is the difference between a pilot test and a pretest?
Generally, a pretest involves only a small selection of the elements involved in the larger-scale study. A pretest might help identify immediate concerns or provide deeper insight into a product's functionality or desirability. A pilot test, on the other hand, is a miniature version of the final test, conducted with the same attributes as the final research study.
Is pilot testing the same as alpha testing?
Alpha testing is a testing process usually applied to software. It is designed specifically to look at the bugs in a product before it is launched in a public form, including beta test form. Pilot testing, on the other hand, is a full test of the entire product and its features, and may involve end users.
While alpha testing is generally performed by employees of the organization and may involve testing strategies designed to identify challenges and problems, pilot testing usually involves use of the product by end users. Those users will then report on their findings and provide more insight into the product's overall functionality.
Get started today
Go from raw data to valuable insights with a flexible research platform
Editor’s picks
Last updated: 21 December 2023
Last updated: 16 December 2023
Last updated: 6 October 2023
Last updated: 5 March 2024
Last updated: 25 November 2023
Last updated: 15 February 2024
Last updated: 11 March 2024
Last updated: 12 December 2023
Last updated: 6 March 2024
Last updated: 10 April 2023
Last updated: 20 December 2023
Latest articles
Related topics, log in or sign up.
Get started for free
Piloting and Feasibility Studies in IS Research
- First Online: 16 September 2023
Cite this chapter

- Mohammed Ali 2
174 Accesses
This chapter aims to cover process of conducting a pilot study to assess the feasibility of an IS research project. This entails conducting preliminary fieldwork on a target population to test the research questions and/or hypotheses on a small scale to determine its potential feasibility on a larger scale. Therefore, the chapter emphasises the need to explore procedures of conducting an effective pilot study in contemporary IS research projects. In addition to the chapter contents, definitions, facts, tables, figures, activities, and case studies are provided to reinforce researcher and practitioner learning of the piloting procedures used in contemporary IS research.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Anderson, R. (2008). New MRC guidance on evaluating complex interventions. Bmj, 337 .
Google Scholar
Arain, M., Campbell, M. J., Cooper, C. L., & Lancaster, G. A. (2010). What is a pilot or feasibility study? A review of current practice and editorial policy. BMC Medical Research Methodology, 10 (1), 67.
Article Google Scholar
Arnold, D. M., Burns, K. E., Adhikari, N. K., Kho, M. E., Meade, M. O., & Cook, D. J. (2009). The design and interpretation of pilot trials in clinical research in critical care. Critical Care Medicine, 37 (1), S69–S74.
Eldridge, S. M., Lancaster, G. A., Campbell, M. J., Thabane, L., Hopewell, S., Coleman, C. L., & Bond, C. M. (2016). Defining feasibility and pilot studies in preparation for randomised controlled trials: Development of a conceptual framework. PloS One, 11 (3), e0150205.
Fisher, P. (2012). Ethics in qualitative research: ‘Vulnerability’, citizenship and human rights. Ethics and Social Welfare, 6 (1), 2–17.
Malmqvist, J., Hellberg, K., Möllås, G., Rose, R., & Shevlin, M. (2019). Conducting the pilot study: a neglected part of the research process? methodological findings supporting the importance of piloting in qualitative research studies. International Journal of Qualitative Methods, 18 .
Thabane, L., Ma, J., Chu, R., Cheng, J., Ismaila, A., Rios, L. P., … & Goldsmith, C. H. (2010). A tutorial on pilot studies: The what, why and how. BMC Medical Research Methodology, 10 (1), 1–10.
Download references
Author information
Authors and affiliations.
Salford Business School, University of Salford, Manchester, UK
Mohammed Ali
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Mohammed Ali .
Rights and permissions
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Ali, M. (2023). Piloting and Feasibility Studies in IS Research. In: Information Systems Research. Palgrave Macmillan, Cham. https://doi.org/10.1007/978-3-031-25470-3_8
Download citation
DOI : https://doi.org/10.1007/978-3-031-25470-3_8
Published : 16 September 2023
Publisher Name : Palgrave Macmillan, Cham
Print ISBN : 978-3-031-25469-7
Online ISBN : 978-3-031-25470-3
eBook Packages : Computer Science Computer Science (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- IND +91 8754467066
- UK +44 - 753 714 4372
- [email protected]

Pilot Study
Pilot study
At the concluding phase of the explanatory study method, a sample investigation was carried out. The survey questionnaire should be assessed by way of the sample research prior to being executed amongst the populace (Saunders et al., 2003). The chief intent of the sample study is to guarantee that participants are not subjected to difficulties during the investigation. The questionnaire prior to being employed for gathering information could be enhanced utilizing the findings got from the sample or pilot study. Sample research further offers the authenticity for the questionnaire to be employed (Saunders et al., 2003).
The sample study of the questionnaire was undertaken. So as to conclude the sample study for a questionnaire, at least ten respondents are needed (Fink, 2003). The respondents were interrogated on the features stated below:
- Clarity of the queries (Fink, 2003)
- Relevance of the queries (Fink, 2003)
- Overall design of the entire questionnaire (Bell, 2005)
- Time required to finish the questionnaire (Bell, 2005)
The questionnaire was modified by the investigator by way of the comments received at the conclusion of the study method by the respondents, but the queries drafted were not changed. Alterations were made pertaining to the length of the questionnaire like changing the font size and line spacing.
MAIN SERVICES
Hire a statistician, statswork popup.
- Privacy Overview
- Strictly Necessary Cookies
- 3rd Party Cookies
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
This website uses Google Analytics to collect anonymous information such as the number of visitors to the site, and the most popular pages.
Keeping this cookie enabled helps us to improve our website.
Please enable Strictly Necessary Cookies first so that we can save your preferences!
Numbers, Facts and Trends Shaping Your World
Read our research on:
Full Topic List
Regions & Countries
- Publications
- Our Methods
- Short Reads
- Tools & Resources
Read Our Research On:
Writing Survey Questions
Perhaps the most important part of the survey process is the creation of questions that accurately measure the opinions, experiences and behaviors of the public. Accurate random sampling will be wasted if the information gathered is built on a shaky foundation of ambiguous or biased questions. Creating good measures involves both writing good questions and organizing them to form the questionnaire.
Questionnaire design is a multistage process that requires attention to many details at once. Designing the questionnaire is complicated because surveys can ask about topics in varying degrees of detail, questions can be asked in different ways, and questions asked earlier in a survey may influence how people respond to later questions. Researchers are also often interested in measuring change over time and therefore must be attentive to how opinions or behaviors have been measured in prior surveys.
Surveyors may conduct pilot tests or focus groups in the early stages of questionnaire development in order to better understand how people think about an issue or comprehend a question. Pretesting a survey is an essential step in the questionnaire design process to evaluate how people respond to the overall questionnaire and specific questions, especially when questions are being introduced for the first time.
For many years, surveyors approached questionnaire design as an art, but substantial research over the past forty years has demonstrated that there is a lot of science involved in crafting a good survey questionnaire. Here, we discuss the pitfalls and best practices of designing questionnaires.
Question development
There are several steps involved in developing a survey questionnaire. The first is identifying what topics will be covered in the survey. For Pew Research Center surveys, this involves thinking about what is happening in our nation and the world and what will be relevant to the public, policymakers and the media. We also track opinion on a variety of issues over time so we often ensure that we update these trends on a regular basis to better understand whether people’s opinions are changing.
At Pew Research Center, questionnaire development is a collaborative and iterative process where staff meet to discuss drafts of the questionnaire several times over the course of its development. We frequently test new survey questions ahead of time through qualitative research methods such as focus groups , cognitive interviews, pretesting (often using an online, opt-in sample ), or a combination of these approaches. Researchers use insights from this testing to refine questions before they are asked in a production survey, such as on the ATP.
Measuring change over time
Many surveyors want to track changes over time in people’s attitudes, opinions and behaviors. To measure change, questions are asked at two or more points in time. A cross-sectional design surveys different people in the same population at multiple points in time. A panel, such as the ATP, surveys the same people over time. However, it is common for the set of people in survey panels to change over time as new panelists are added and some prior panelists drop out. Many of the questions in Pew Research Center surveys have been asked in prior polls. Asking the same questions at different points in time allows us to report on changes in the overall views of the general public (or a subset of the public, such as registered voters, men or Black Americans), or what we call “trending the data”.
When measuring change over time, it is important to use the same question wording and to be sensitive to where the question is asked in the questionnaire to maintain a similar context as when the question was asked previously (see question wording and question order for further information). All of our survey reports include a topline questionnaire that provides the exact question wording and sequencing, along with results from the current survey and previous surveys in which we asked the question.
The Center’s transition from conducting U.S. surveys by live telephone interviewing to an online panel (around 2014 to 2020) complicated some opinion trends, but not others. Opinion trends that ask about sensitive topics (e.g., personal finances or attending religious services ) or that elicited volunteered answers (e.g., “neither” or “don’t know”) over the phone tended to show larger differences than other trends when shifting from phone polls to the online ATP. The Center adopted several strategies for coping with changes to data trends that may be related to this change in methodology. If there is evidence suggesting that a change in a trend stems from switching from phone to online measurement, Center reports flag that possibility for readers to try to head off confusion or erroneous conclusions.
Open- and closed-ended questions
One of the most significant decisions that can affect how people answer questions is whether the question is posed as an open-ended question, where respondents provide a response in their own words, or a closed-ended question, where they are asked to choose from a list of answer choices.
For example, in a poll conducted after the 2008 presidential election, people responded very differently to two versions of the question: “What one issue mattered most to you in deciding how you voted for president?” One was closed-ended and the other open-ended. In the closed-ended version, respondents were provided five options and could volunteer an option not on the list.
When explicitly offered the economy as a response, more than half of respondents (58%) chose this answer; only 35% of those who responded to the open-ended version volunteered the economy. Moreover, among those asked the closed-ended version, fewer than one-in-ten (8%) provided a response other than the five they were read. By contrast, fully 43% of those asked the open-ended version provided a response not listed in the closed-ended version of the question. All of the other issues were chosen at least slightly more often when explicitly offered in the closed-ended version than in the open-ended version. (Also see “High Marks for the Campaign, a High Bar for Obama” for more information.)
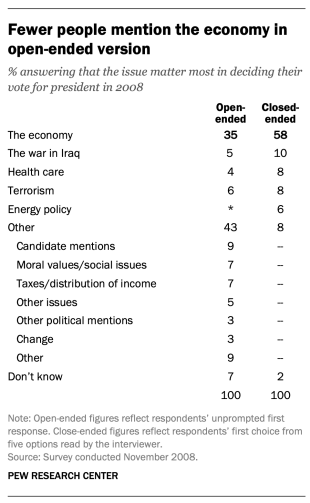
Researchers will sometimes conduct a pilot study using open-ended questions to discover which answers are most common. They will then develop closed-ended questions based off that pilot study that include the most common responses as answer choices. In this way, the questions may better reflect what the public is thinking, how they view a particular issue, or bring certain issues to light that the researchers may not have been aware of.
When asking closed-ended questions, the choice of options provided, how each option is described, the number of response options offered, and the order in which options are read can all influence how people respond. One example of the impact of how categories are defined can be found in a Pew Research Center poll conducted in January 2002. When half of the sample was asked whether it was “more important for President Bush to focus on domestic policy or foreign policy,” 52% chose domestic policy while only 34% said foreign policy. When the category “foreign policy” was narrowed to a specific aspect – “the war on terrorism” – far more people chose it; only 33% chose domestic policy while 52% chose the war on terrorism.
In most circumstances, the number of answer choices should be kept to a relatively small number – just four or perhaps five at most – especially in telephone surveys. Psychological research indicates that people have a hard time keeping more than this number of choices in mind at one time. When the question is asking about an objective fact and/or demographics, such as the religious affiliation of the respondent, more categories can be used. In fact, they are encouraged to ensure inclusivity. For example, Pew Research Center’s standard religion questions include more than 12 different categories, beginning with the most common affiliations (Protestant and Catholic). Most respondents have no trouble with this question because they can expect to see their religious group within that list in a self-administered survey.
In addition to the number and choice of response options offered, the order of answer categories can influence how people respond to closed-ended questions. Research suggests that in telephone surveys respondents more frequently choose items heard later in a list (a “recency effect”), and in self-administered surveys, they tend to choose items at the top of the list (a “primacy” effect).
Because of concerns about the effects of category order on responses to closed-ended questions, many sets of response options in Pew Research Center’s surveys are programmed to be randomized to ensure that the options are not asked in the same order for each respondent. Rotating or randomizing means that questions or items in a list are not asked in the same order to each respondent. Answers to questions are sometimes affected by questions that precede them. By presenting questions in a different order to each respondent, we ensure that each question gets asked in the same context as every other question the same number of times (e.g., first, last or any position in between). This does not eliminate the potential impact of previous questions on the current question, but it does ensure that this bias is spread randomly across all of the questions or items in the list. For instance, in the example discussed above about what issue mattered most in people’s vote, the order of the five issues in the closed-ended version of the question was randomized so that no one issue appeared early or late in the list for all respondents. Randomization of response items does not eliminate order effects, but it does ensure that this type of bias is spread randomly.
Questions with ordinal response categories – those with an underlying order (e.g., excellent, good, only fair, poor OR very favorable, mostly favorable, mostly unfavorable, very unfavorable) – are generally not randomized because the order of the categories conveys important information to help respondents answer the question. Generally, these types of scales should be presented in order so respondents can easily place their responses along the continuum, but the order can be reversed for some respondents. For example, in one of Pew Research Center’s questions about abortion, half of the sample is asked whether abortion should be “legal in all cases, legal in most cases, illegal in most cases, illegal in all cases,” while the other half of the sample is asked the same question with the response categories read in reverse order, starting with “illegal in all cases.” Again, reversing the order does not eliminate the recency effect but distributes it randomly across the population.
Question wording
The choice of words and phrases in a question is critical in expressing the meaning and intent of the question to the respondent and ensuring that all respondents interpret the question the same way. Even small wording differences can substantially affect the answers people provide.
[View more Methods 101 Videos ]
An example of a wording difference that had a significant impact on responses comes from a January 2003 Pew Research Center survey. When people were asked whether they would “favor or oppose taking military action in Iraq to end Saddam Hussein’s rule,” 68% said they favored military action while 25% said they opposed military action. However, when asked whether they would “favor or oppose taking military action in Iraq to end Saddam Hussein’s rule even if it meant that U.S. forces might suffer thousands of casualties, ” responses were dramatically different; only 43% said they favored military action, while 48% said they opposed it. The introduction of U.S. casualties altered the context of the question and influenced whether people favored or opposed military action in Iraq.
There has been a substantial amount of research to gauge the impact of different ways of asking questions and how to minimize differences in the way respondents interpret what is being asked. The issues related to question wording are more numerous than can be treated adequately in this short space, but below are a few of the important things to consider:
First, it is important to ask questions that are clear and specific and that each respondent will be able to answer. If a question is open-ended, it should be evident to respondents that they can answer in their own words and what type of response they should provide (an issue or problem, a month, number of days, etc.). Closed-ended questions should include all reasonable responses (i.e., the list of options is exhaustive) and the response categories should not overlap (i.e., response options should be mutually exclusive). Further, it is important to discern when it is best to use forced-choice close-ended questions (often denoted with a radio button in online surveys) versus “select-all-that-apply” lists (or check-all boxes). A 2019 Center study found that forced-choice questions tend to yield more accurate responses, especially for sensitive questions. Based on that research, the Center generally avoids using select-all-that-apply questions.
It is also important to ask only one question at a time. Questions that ask respondents to evaluate more than one concept (known as double-barreled questions) – such as “How much confidence do you have in President Obama to handle domestic and foreign policy?” – are difficult for respondents to answer and often lead to responses that are difficult to interpret. In this example, it would be more effective to ask two separate questions, one about domestic policy and another about foreign policy.
In general, questions that use simple and concrete language are more easily understood by respondents. It is especially important to consider the education level of the survey population when thinking about how easy it will be for respondents to interpret and answer a question. Double negatives (e.g., do you favor or oppose not allowing gays and lesbians to legally marry) or unfamiliar abbreviations or jargon (e.g., ANWR instead of Arctic National Wildlife Refuge) can result in respondent confusion and should be avoided.
Similarly, it is important to consider whether certain words may be viewed as biased or potentially offensive to some respondents, as well as the emotional reaction that some words may provoke. For example, in a 2005 Pew Research Center survey, 51% of respondents said they favored “making it legal for doctors to give terminally ill patients the means to end their lives,” but only 44% said they favored “making it legal for doctors to assist terminally ill patients in committing suicide.” Although both versions of the question are asking about the same thing, the reaction of respondents was different. In another example, respondents have reacted differently to questions using the word “welfare” as opposed to the more generic “assistance to the poor.” Several experiments have shown that there is much greater public support for expanding “assistance to the poor” than for expanding “welfare.”
We often write two versions of a question and ask half of the survey sample one version of the question and the other half the second version. Thus, we say we have two forms of the questionnaire. Respondents are assigned randomly to receive either form, so we can assume that the two groups of respondents are essentially identical. On questions where two versions are used, significant differences in the answers between the two forms tell us that the difference is a result of the way we worded the two versions.

One of the most common formats used in survey questions is the “agree-disagree” format. In this type of question, respondents are asked whether they agree or disagree with a particular statement. Research has shown that, compared with the better educated and better informed, less educated and less informed respondents have a greater tendency to agree with such statements. This is sometimes called an “acquiescence bias” (since some kinds of respondents are more likely to acquiesce to the assertion than are others). This behavior is even more pronounced when there’s an interviewer present, rather than when the survey is self-administered. A better practice is to offer respondents a choice between alternative statements. A Pew Research Center experiment with one of its routinely asked values questions illustrates the difference that question format can make. Not only does the forced choice format yield a very different result overall from the agree-disagree format, but the pattern of answers between respondents with more or less formal education also tends to be very different.
One other challenge in developing questionnaires is what is called “social desirability bias.” People have a natural tendency to want to be accepted and liked, and this may lead people to provide inaccurate answers to questions that deal with sensitive subjects. Research has shown that respondents understate alcohol and drug use, tax evasion and racial bias. They also may overstate church attendance, charitable contributions and the likelihood that they will vote in an election. Researchers attempt to account for this potential bias in crafting questions about these topics. For instance, when Pew Research Center surveys ask about past voting behavior, it is important to note that circumstances may have prevented the respondent from voting: “In the 2012 presidential election between Barack Obama and Mitt Romney, did things come up that kept you from voting, or did you happen to vote?” The choice of response options can also make it easier for people to be honest. For example, a question about church attendance might include three of six response options that indicate infrequent attendance. Research has also shown that social desirability bias can be greater when an interviewer is present (e.g., telephone and face-to-face surveys) than when respondents complete the survey themselves (e.g., paper and web surveys).
Lastly, because slight modifications in question wording can affect responses, identical question wording should be used when the intention is to compare results to those from earlier surveys. Similarly, because question wording and responses can vary based on the mode used to survey respondents, researchers should carefully evaluate the likely effects on trend measurements if a different survey mode will be used to assess change in opinion over time.
Question order
Once the survey questions are developed, particular attention should be paid to how they are ordered in the questionnaire. Surveyors must be attentive to how questions early in a questionnaire may have unintended effects on how respondents answer subsequent questions. Researchers have demonstrated that the order in which questions are asked can influence how people respond; earlier questions can unintentionally provide context for the questions that follow (these effects are called “order effects”).
One kind of order effect can be seen in responses to open-ended questions. Pew Research Center surveys generally ask open-ended questions about national problems, opinions about leaders and similar topics near the beginning of the questionnaire. If closed-ended questions that relate to the topic are placed before the open-ended question, respondents are much more likely to mention concepts or considerations raised in those earlier questions when responding to the open-ended question.
For closed-ended opinion questions, there are two main types of order effects: contrast effects ( where the order results in greater differences in responses), and assimilation effects (where responses are more similar as a result of their order).
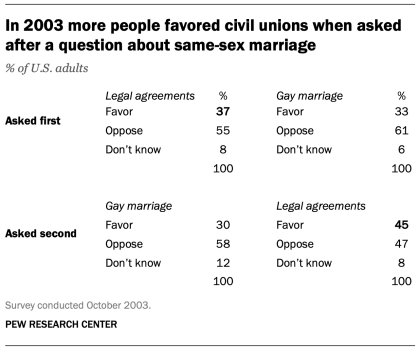
An example of a contrast effect can be seen in a Pew Research Center poll conducted in October 2003, a dozen years before same-sex marriage was legalized in the U.S. That poll found that people were more likely to favor allowing gays and lesbians to enter into legal agreements that give them the same rights as married couples when this question was asked after one about whether they favored or opposed allowing gays and lesbians to marry (45% favored legal agreements when asked after the marriage question, but 37% favored legal agreements without the immediate preceding context of a question about same-sex marriage). Responses to the question about same-sex marriage, meanwhile, were not significantly affected by its placement before or after the legal agreements question.
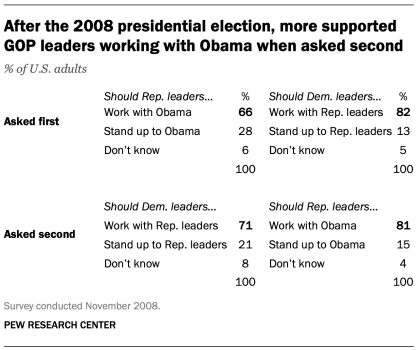
Another experiment embedded in a December 2008 Pew Research Center poll also resulted in a contrast effect. When people were asked “All in all, are you satisfied or dissatisfied with the way things are going in this country today?” immediately after having been asked “Do you approve or disapprove of the way George W. Bush is handling his job as president?”; 88% said they were dissatisfied, compared with only 78% without the context of the prior question.
Responses to presidential approval remained relatively unchanged whether national satisfaction was asked before or after it. A similar finding occurred in December 2004 when both satisfaction and presidential approval were much higher (57% were dissatisfied when Bush approval was asked first vs. 51% when general satisfaction was asked first).
Several studies also have shown that asking a more specific question before a more general question (e.g., asking about happiness with one’s marriage before asking about one’s overall happiness) can result in a contrast effect. Although some exceptions have been found, people tend to avoid redundancy by excluding the more specific question from the general rating.
Assimilation effects occur when responses to two questions are more consistent or closer together because of their placement in the questionnaire. We found an example of an assimilation effect in a Pew Research Center poll conducted in November 2008 when we asked whether Republican leaders should work with Obama or stand up to him on important issues and whether Democratic leaders should work with Republican leaders or stand up to them on important issues. People were more likely to say that Republican leaders should work with Obama when the question was preceded by the one asking what Democratic leaders should do in working with Republican leaders (81% vs. 66%). However, when people were first asked about Republican leaders working with Obama, fewer said that Democratic leaders should work with Republican leaders (71% vs. 82%).
The order questions are asked is of particular importance when tracking trends over time. As a result, care should be taken to ensure that the context is similar each time a question is asked. Modifying the context of the question could call into question any observed changes over time (see measuring change over time for more information).
A questionnaire, like a conversation, should be grouped by topic and unfold in a logical order. It is often helpful to begin the survey with simple questions that respondents will find interesting and engaging. Throughout the survey, an effort should be made to keep the survey interesting and not overburden respondents with several difficult questions right after one another. Demographic questions such as income, education or age should not be asked near the beginning of a survey unless they are needed to determine eligibility for the survey or for routing respondents through particular sections of the questionnaire. Even then, it is best to precede such items with more interesting and engaging questions. One virtue of survey panels like the ATP is that demographic questions usually only need to be asked once a year, not in each survey.
U.S. Surveys
Other research methods, sign up for our weekly newsletter.
Fresh data delivered Saturday mornings
1615 L St. NW, Suite 800 Washington, DC 20036 USA (+1) 202-419-4300 | Main (+1) 202-857-8562 | Fax (+1) 202-419-4372 | Media Inquiries
Research Topics
- Age & Generations
- Coronavirus (COVID-19)
- Economy & Work
- Family & Relationships
- Gender & LGBTQ
- Immigration & Migration
- International Affairs
- Internet & Technology
- Methodological Research
- News Habits & Media
- Non-U.S. Governments
- Other Topics
- Politics & Policy
- Race & Ethnicity
- Email Newsletters
ABOUT PEW RESEARCH CENTER Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
Copyright 2024 Pew Research Center
Terms & Conditions
Privacy Policy
Cookie Settings
Reprints, Permissions & Use Policy
- Open access
- Published: 19 April 2024
Asparagine reduces the risk of schizophrenia: a bidirectional two-sample mendelian randomization study of aspartate, asparagine and schizophrenia
- Huang-Hui Liu 1 , 2 na1 ,
- Yao Gao 1 , 2 na1 ,
- Dan Xu 1 , 2 ,
- Xin-Zhe Du 1 , 2 ,
- Si-Meng Wei 1 , 2 ,
- Jian-Zhen Hu 1 , 2 ,
- Yong Xu 1 , 2 &
- Liu Sha 1 , 2
BMC Psychiatry volume 24 , Article number: 299 ( 2024 ) Cite this article
126 Accesses
Metrics details
Despite ongoing research, the underlying causes of schizophrenia remain unclear. Aspartate and asparagine, essential amino acids, have been linked to schizophrenia in recent studies, but their causal relationship is still unclear. This study used a bidirectional two-sample Mendelian randomization (MR) method to explore the causal relationship between aspartate and asparagine with schizophrenia.
This study employed summary data from genome-wide association studies (GWAS) conducted on European populations to examine the correlation between aspartate and asparagine with schizophrenia. In order to investigate the causal effects of aspartate and asparagine on schizophrenia, this study conducted a two-sample bidirectional MR analysis using genetic factors as instrumental variables.
No causal relationship was found between aspartate and schizophrenia, with an odds ratio (OR) of 1.221 (95%CI: 0.483–3.088, P -value = 0.674). Reverse MR analysis also indicated that no causal effects were found between schizophrenia and aspartate, with an OR of 0.999 (95%CI: 0.987–1.010, P -value = 0.841). There is a negative causal relationship between asparagine and schizophrenia, with an OR of 0.485 (95%CI: 0.262-0.900, P -value = 0.020). Reverse MR analysis indicates that there is no causal effect between schizophrenia and asparagine, with an OR of 1.005(95%CI: 0.999–1.011, P -value = 0.132).
This study suggests that there may be a potential risk reduction for schizophrenia with increased levels of asparagine, while also indicating the absence of a causal link between elevated or diminished levels of asparagine in individuals diagnosed with schizophrenia. There is no potential causal relationship between aspartate and schizophrenia, whether prospective or reverse MR. However, it is important to note that these associations necessitate additional research for further validation.
Peer Review reports
Introduction
Schizophrenia is a serious psychiatric illness that affects 0.5 -1% of the global population [ 1 ]. The burden of mental illness was estimated to account for 7% of all diseases worldwide in 2016, and nearly 20% of all years lived with disability [ 2 ]. The characteristics of schizophrenia are positive symptoms, negative symptoms, and cognitive symptoms, which are often severe functional impairments and significant social maladaptations for patients suffering from schizophrenia [ 3 ]. It is still unclear what causes schizophrenia and what the pathogenesis is. There are a number of hypotheses based on neurochemical mechanisms, including dopaminergic and glutamatergic systems [ 4 ]. Although schizophrenia research has made significant advances in the past, further insight into its mechanisms and causes is still needed.
Association genetics research and genome-wide association studies have successfully identified more than 24 candidate genes that serve as molecular biomarkers for the susceptibility to treatment- refractory schizophrenia (TRS). It is worth noting that some proteins in these genes are related to glutamate transfer, especially the N-methyl-D-aspartate receptor (NMDAR) [ 5 ]. It is thought that NMDARs are important for neural plasticity, which is the ability of the brain itself to adapt to new environments. With age, NMDAR function usually declines, which may lead to decreased plasticity, leading to learning and memory problems. Consequently, the manifestation of cognitive deficits observed in diverse pathologies, including Alzheimer’s disease, amyotrophic lateral sclerosis, Huntington’s disease, Parkinson’s disease, schizophrenia, and major depression, can be attributed to the dysfunction of NMDAR [ 4 ]. There are two enantiomers of aspartate (Asp): L and D [ 6 ]. In the brain, D-aspartate (D-Asp) stimulates glutamate receptors and dopaminergic neurons through its direct NMDAR agonist action [ 7 ]. According to the glutamate theory of Sch, glutamate NMDAR dysfunction is a primary contributor to the development of this psychiatric disorder and TRS [ 8 ]. It has been shown in two autopsy studies that D-Asp of prefrontal cortex neurons in patients with schizophrenia are significantly reduced, which is related to an increased expression of D-Asp oxidase [ 9 ] or an increased activity of D-Asp oxidase [ 10 ]. Several studies in animal models and humans have shown that D-amino acids, particularly D-Ser and D-Asp [ 11 ], are able to modulate several NMDAR-dependent processes, including synaptic plasticity, brain development, cognition and brain ageing [ 12 ]. In addition, D-Asp is synthesized in hippocampal and prefrontal cortex neurons, which play an important role in the development of schizophrenia [ 13 ]. It has been reported that the precursor substance of asparagine (Asn), aspartate, activates the N-methyl-D-aspartate receptor [ 14 ]. Asparagine is essential for the survival of all cells [ 15 ], and it was decreased in schizophrenia patients [ 16 ]. Asparagine can cause metabolic disorders of alanine, aspartate, and glutamic acid, leading to dysfunction of the glutamine-glutamate cycle and further affecting it Gamma-Aminobutyric Acid(GABA) level [ 17 ].It is widely understood that the imbalance of GABA levels and NMDAR plays a crucial role in the pathogenesis of schizophrenia, causing neurotoxic effects, synaptic dysfunction, and cognitive impairments [ 18 ].Schizophrenic patients exhibited significantly higher levels of serum aspartate, glutamate, isoleucine, histidine and tyrosine and significantly lower concentrations of serum asparagine, tryptophan and serine [ 19 ]. Other studies have also shown that schizophrenics have higher levels of asparagine, phenylalanine, and cystine, and lower ratios of tyrosine, tryptophan, and tryptophan to competing amino acids, compared to healthy individuals [ 20 ]. Aspartate and asparagine’s association with schizophrenia is not fully understood, and their causal relationship remains unclear.
The MR method is a method that uses Mendelian independence principle to infer causality, which uses genetic variation to study the impact of exposure on outcomes. By using this approach, confounding factors in general research are overcome, and causal reasoning is provided on a reasonable temporal basis [ 21 ]. The instrumental variables for genetic variation that are chosen must adhere to three primary hypotheses: the correlation hypothesis, which posits a robust correlation between single nucleotide polymorphisms (SNPs) and exposure factors; the independence hypothesis, which asserts that SNPs are not affected by various confounding factors; the exclusivity hypothesis, which maintains that SNPs solely influence outcomes through on exposure factors. In a recent study, Mendelian randomization was used to reveal a causal connection between thyroid function and schizophrenia [ 22 ]. According to another Mendelian randomization study, physical activity is causally related to schizophrenia [ 23 ]. Therefore, this study used Mendelian randomization method to explore the causal effects of aspartate on schizophrenia and asparagine on schizophrenia.
To elucidate the causal effects of aspartate and asparagine on schizophrenia. This study used bidirectional MR analysis. In the prospective analysis of MR, the exposure factors under consideration were aspartate and asparagine, while the outcome of interest was the risk of schizophrenia. On the contrary, in the reverse MR analysis, schizophrenia was utilized as the exposure factor, with aspartate and asparagine being chosen as the outcomes.
Materials and methods
Obtaining data sources, select genetic tools closely related to aspartate or asparagine.
In this research, publicly accessible GWAS summary statistical datasets from the MR basic platform were utilized. These datasets consisted of 7721 individuals of European ancestry [ 24 ] for the exposure phenotype instrumental variable of aspartate, and 7761 individuals of European ancestry [ 24 ] for the exposure phenotype instrumental variable of asparagine.
Select genetic tools closely related to schizophrenia
Data from the MR basic platform was used in this study for GWAS summary statistics, which included 77,096 individuals of European ancestry [ 5 ], as instrumental variables related to schizophrenia exposure phenotype.
Obtaining result data
The publicly accessible GWAS summary statistical dataset for schizophrenia was utilized on the MR basic platform, with a sample size of 77096. Additionally, the summary level data for aspartate and asparagine were obtained from the publicly available GWAS summary dataset on the MR basic platform, with sample sizes of 7721 and 7761, respectively, serving as outcome variables.
Instrumental variable filtering
Eliminating linkage disequilibrium.
The selection criteria for identifying exposure related SNPs from the aggregated data of GWAS include: (1) Reaching a significance level that meets the threshold for whole genome research, expressed as P -value < 5 * 10 − 6 [ 25 ]; (2) Ensure the independence of the selected SNPs and eliminate linkage disequilibrium SNPs ( r 2 < 0.001, window size of 10000KB) [ 26 ]; (3) There are corresponding data related to the research results in the GWAS summary data.
Eliminating weak instruments
To evaluate whether the instrumental variables selected for this MR study have weak values, we calculated the F-statistic. If the F-value is greater than 10, it indicates that there are no weak instruments in this study, indicating the reliability of the study. Using the formula F =[(N-K-1)/K] × [R 2 /(1-R 2 )], where N denotes the sample size pertaining to the exposure factor, K signifies the count of instrumental variables, and R 2 denotes the proportion of variations in the exposure factor that can be elucidated by the instrumental variables.
The final instrumental variable obtained
As a result of removing linkage disequilibrium and weak instrumental variables, finally, 3 SNPs related to aspartate and 24 SNPs related to asparagine were selected for MR analysis.
Bidirectional MR analysis
Research design.
Figure 1 presents a comprehensive depiction of the overarching design employed in the MR analysis undertaken in this study. We ascertained SNPs exhibiting robust correlation with the target exposure through analysis of publicly available published data, subsequently investigating the existence of a causal association between these SNPs and the corresponding outcomes. This study conducted two bidirectional MR analyses, one prospective and reverse MR on the causal relationship between aspartate and schizophrenia, and the other prospective and reverse MR on the causal relationship between asparagine and schizophrenia.

A MR analysis of aspartate and schizophrenia (located in the upper left corner). B MR analysis of schizophrenia and aspartate (located in the upper right corner). C MR analysis of asparagine and schizophrenia (located in the lower left corner). D MR analysis of schizophrenia and asparagine (located in the lower right corner)
Statistical analysis
Weighted median, weighted mode, MR Egger, and inverse variance weighting (IVW) were used to conduct a MR study. The primary research findings were derived from the results obtained through IVW, the results of sensitivity analysis using other methods to estimate causal effects are considered. Statistical significance was determined if the P -value was less than 0.05. To enhance the interpretation of the findings, this study converted the beta values obtained in to OR, accompanied by the calculation of a 95% confidence interval (CI).
Test for directional horizontal pleiotropy
This study used MR Egger intercept to test horizontal pleiotropy. If the P -value is greater than 0.05, it indicates that there is no horizontal pleiotropy in this study, meaning that instrumental variables can only regulate outcome variables through exposure factors.
Results of bidirectional MR analysis of aspartate and schizophrenia
Analysis results of aspartate and schizophrenia.
In prospective MR analysis, this study set aspartate as the exposure factor and schizophrenia as the outcome. We used 3 SNPs significantly associated with aspartate screened across the entire genome. The instrumental variables exhibited F-values exceeding 10, signifying the absence of weak instruments and thereby affirming the robustness of our findings. Through MR analysis (Fig. 2 A), we assessed the individual influence of each SNP locus on schizophrenia. The results of the IVW method indicate that no causal effect was found between aspartate and schizophrenia, with an OR of 1.221 (95%CI: 0.483–3.088, P -value = 0.674).
In addition, the analyses conducted using the weighted mode and weighted median methods yielded similar results, indicating the absence of a causal association between aspartate and schizophrenia. Furthermore, the MR Egger analysis demonstrated no statistically significant disparity in effectiveness between aspartate and schizophrenia, as evidenced by a P -value greater than 0.05 (Table 1 ; Fig. 2 B).
In order to test the reliability of the research results, this study used MR Egger intercept analysis to examine horizontal pleiotropy, and the result was P -value = 0.579 > 0.05, indicating the absence of level pleiotropy. Furthermore, a leave-one-out test was conducted to demonstrate that no single SNP had a substantial impact on the stability of the results, indicating that this study has considerable stability (Fig. 2 C). Accordingly, the MR analysis results demonstrate the conclusion that aspartate and schizophrenia do not exhibit a causal relationship.
Analysis results of schizophrenia and aspartate
Different from prospective MR studies, in reverse MR studies, schizophrenia was set as an exposure factor and aspartate was set as the outcome. Through MR analysis (Fig. 2 D), we assessed the individual influence of each SNP locus on aspartate .The results of the IVW method indicate that there is no causal effect between schizophrenia and aspartate, with an OR of 0.999(95%CI: 0.987–1.010, P -value = 0.841). Similarly, the weighted mode, weighted median methods also failed to demonstrate a causal link between schizophrenia and aspartate. Additionally, the MR Egger analysis did not reveal any statistically significant difference in effectiveness between schizophrenia and aspartate ( P -value > 0.05) (Table 1 and Fig . 2 E).
The MR Egger intercept was used to test horizontal pleiotropy, and the result was P -value = 0.226 > 0.05, proving that this study is not affected by horizontal pleiotropy. Furthermore, a leave-one-out test revealed that no individual SNP significantly influenced the robustness of the findings (Fig. 2 F).

Depicts the causal association between aspartate and schizophrenia through diverse statistical analyses, as well as the causal association between schizophrenia and aspartate through diverse statistical analyses. A The forest plot of aspartate related SNPs and schizophrenia analysis results, with the red line showing the MR Egger test and IVW method. B Scatter plot of the analysis results of aspartate and schizophrenia, with the slope indicating the strength of the causal relationship. C Leave-one-out test of research results on aspartate and schizophrenia. D The forest plot of schizophrenia related SNPs and aspartate analysis results, with the red line showing the MR Egger test and IVW method. E Scatter plot of the analysis results of schizophrenia and aspartate, with the slope indicating the strength of the causal relationship. F Leave-one-out test of research results on schizophrenia and aspartate
Results of bidirectional MR analysis of asparagine and schizophrenia
Analysis results of asparagine and schizophrenia.
In prospective MR studies, we used asparagine as an exposure factor and schizophrenia as a result to investigate the potential causal relationship between them. Through a rigorous screening process, we identified 24 genome-wide significant SNPs associated with asparagine. In addition, the instrumental variable F values all exceeded 10, indicating that this study was not affected by weak instruments, thus proving the stability of the results. This study conducted MR analysis to evaluate the impact of all SNP loci on schizophrenia. (Fig. 3 A). According to the results of IVW, a causal relationship was found between asparagine and schizophrenia, and the relationship is negatively correlated, with an OR of 0.485 (95%CI: 0.262-0.900, P -value = 0.020).
The weighted median results also showed a causal relationship between asparagine and schizophrenia, and it was negatively correlated. In the weighted mode method, asparagine and schizophrenia did not have a causal relationship, while in the MR Egger method, there was no statistically significant difference in efficacy between them ( P -value > 0.05) (Table 1 ; Fig. 3 B).
In order to examine the horizontal pleiotropy, the MR Egger intercept was applied, and P -value = 0.768 > 0.05 result proves that this study is not affected by horizontal pleiotropy Furthermore, a leave-one-out test was conducted to demonstrate that no individual SNP had a substantial impact on the stability of the results, indicating that this study has good stability. (Fig. 3 C). Therefore, MR analysis shows that asparagine is inversely proportional to schizophrenia.
Analysis results of schizophrenia and asparagine
In reverse MR analysis, schizophrenia is considered an exposure factor, and asparagine is considered the result, studying the causal effects of schizophrenia and asparagine. Through MR analysis (Fig. 3 D), we assessed the individual influence of each SNP locus on s asparagine. The IVW method results indicated no potential causal relationship between schizophrenia and asparagine, with an OR of 1.005(95%CI: 0.999–1.011, P -value = 0.132). The research results of weighted mode method and weighted median method did not find a causal effects of schizophrenia and asparagine. Additionally, the MR Egger analysis did not reveal any statistically significant difference in effectiveness between schizophrenia and asparagine ( P -value > 0.05) (Table 1 ; Fig. 3 E).
In order to examine the horizontal pleiotropy, the MR Egger intercept was applied, and the result was P -value = 0.474 > 0.05, proving that this study is not affected by horizontal pleiotropy. Furthermore, a leave-one-out test was conducted to demonstrate that no individual SNP had a substantial impact on the stability of the results, indicating that this study has good stability (Fig. 3 F).

Depicts the causal association between asparagine and schizophrenia through diverse statistical analyses, as well as the causal association between schizophrenia and asparagine through diverse statistical analyses. A The forest plot of asparagine related SNPs and schizophrenia analysis results, with the red line showing the MR Egger test and IVW method. B Scatter plot of the analysis results of asparagine and schizophrenia, with the slope indicating the strength of the causal relationship. C Leave-one-out test of research results on asparagine and schizophrenia. D The forest plot of schizophrenia related SNPs and asparagine analysis results, with the red line showing the MR Egger test and IVW method. E Scatter plot of the analysis results of schizophrenia and asparagine, with the slope indicating the strength of the causal relationship. F Leave-one-out test of research results on schizophrenia and asparagine
In this study, the MR analysis results after sensitivity analysis suggested a causal relationship between asparagine and schizophrenia, which was negatively correlated. However, the reverse MR analysis did not reveal any potential relationship between schizophrenia and asparagine, no potential causal relationship between aspartate and schizophrenia was found in both prospective and reverse MR analyses (Fig. 4 ).

Summary of results from bidirectional two-sample MR study
The levels of asparagine in schizophrenia patients decrease, according to studies [ 16 ]. Based on the findings of the Madis Parksepp research team, a continuous five-year administration of antipsychotic drugs (AP) has been observed to induce significant metabolic changes in individuals diagnosed with schizophrenia. Significantly, the concentrations of asparagine, glutamine (Gln), methionine, ornithine, and taurine have experienced a substantial rise, whereas aspartate, glutamate (Glu), and alpha-aminoadipic acid(α-AAA) levels have demonstrated a notable decline. Olanzapine (OLZ) treatment resulted in significantly lower levels of Asn compared to control mice [ 27 ]. Asn and Asp play significant roles in various biological processes within the human body, such as participating in glycoprotein synthesis and contributing to brain functionality. It is worth noting that the ammonia produced in brain tissue needs to have a rapid excretion pathway in the brain. Asn plays a crucial role in regulating cellular function within neural tissues through metabolic control. This amino acid is synthesized by the combination of Asp and ammonia, facilitated by the enzyme asparagine synthase. Additionally, the brain effectively manages ammonia elimination by producing glutamine Gln and Asn. This may be an explanation for the significant increase in Asn and Gln levels (as well as a decrease in Asp and Glu levels) during 5 years of illness and after receiving AP treatment [ 28 ]. The study by Marie Luise Rao’s team compared unmedicated schizophrenic patients, healthy individuals and patients receiving antipsychotic treatment. Unmedicated schizophrenics had higher levels of asparagine, citrulline, phenylalanine, and cysteine, while the ratios of tyrosine, tryptophan, and tryptophan to competing amino acids were significantly lower than in healthy individuals [ 29 ].
The findings of our study demonstrate an inverse association between asparagine levels and the susceptibility to schizophrenia, suggesting that asparagine may serve as a protective factor against the development of this psychiatric disorder. However, we did not find a causal relationship between schizophrenia and asparagine. Consequently, additional investigation and scholarly discourse are warranted to gain a comprehensive understanding of this complex association.
Two different autopsy studies measured D-ASP levels in two different brain samples from patients with schizophrenia and a control group [ 14 ]. The first study, which utilized a limited sample size (7–10 subjects per diagnosis), demonstrated a reduction in D-ASP levels within the prefrontal cortex (PFC) postmortem among individuals diagnosed with schizophrenia, amounting to approximately 101%. This decrease was found to be correlated with a notable elevation in D-aspartate oxidase (DDO) mRNA levels within the same cerebral region [ 30 ]. In addition, the second study was conducted on a large sample size (20 subjects/diagnosis/brain regions). The findings of this study indicated a noteworthy decrease of approximately 30% in D-ASP selectivity within the dorsal lateral PFC (DLPFC) of individuals diagnosed with schizophrenia, when compared to corresponding brain regions of individuals without schizophrenia. However, no significant reduction in D-ASP was observed in the hippocampus of patients with schizophrenia. The decrease in D-Asp content was associated with a significant increase (about 25%) in DDO enzyme activity in the DLPFC of schizophrenia patients. This observation highlights the existence of a dysfunctional metabolic process in DDO activity levels in the brains of schizophrenia patients [ 31 ].
Numerous preclinical investigations have demonstrated the influence of D-Asp on various phenotypes reliant on NMDAR, which are linked to schizophrenia. After administering D-Asp to D-Asp oxidase gene knockout mice, the abnormal neuronal pre-pulse inhibition induced by psychoactive drugs such as MK-801 and amphetamine was significantly reduced by the sustained increase in D-Asp [ 32 ]. According to a review, free amino acids, specifically D-Asp and D-Ser (D-serine), have been identified as highly effective and safe nutrients for promoting mental well-being. These amino acids not only serve as integral components of the central nervous system’s structural proteins, but also play a vital role in maintaining optimal functioning of the central nervous system. This is due to their essential role in regulating neurotransmitter levels, including dopamine, norepinephrine, serotonin, and others. For many patients with schizophrenia, a most persistent and effective improvement therapy may be supplementing amino acids, which can improve the expected therapeutic effect of AP and alleviate positive and negative symptoms of schizophrenia [ 33 ].
Numerous studies have demonstrated a plausible correlation between aspartate and schizophrenia; however, our prospective and reverse MR investigations have failed to establish a causal link between aspartate and schizophrenia. This discrepancy may be attributed to the indirect influence of aspartate on the central nervous system through the stimulation of NMDAR, necessitating further investigation to elucidate the direct relationship between aspartate and schizophrenia.
This study used a bidirectional two-sample MR analysis method to explore the causal relationship between aspartate and asparagine with schizophrenia, as well as its inverse relationship [ 34 ]. The utilization of MR analysis presents numerous benefits in the determination of causality [ 35 ]. Notably, the random allocation of alleles to gametes within this method permits the assumption of no correlation between instrumental variables and confounding factors. Consequently, this approach effectively alleviates bias stemming from confounding factors during the inference of causality. Furthermore, the study’s utilization of a substantial sample size in the GWAS summary data engenders a heightened level of confidence in the obtained results [ 36 ]. Consequently, this investigation not only advances the existing body of research on the relationship between aspartate and asparagine with schizophrenia, but also contributed to clinical treatment decisions for patients with schizophrenia.
Nevertheless, this study possesses certain limitations, as it solely relies on populations of European ancestry for both exposure and results. Consequently, it remains uncertain whether these findings can be replicated among non-European races, necessitating further investigation. In addition, in this study, whether the effects of aspartate and asparagine on schizophrenia vary by gender or age cannot be evaluated, and stratified MR analysis should be performed. Additional experimental research is imperative for a comprehensive understanding of the underlying biological mechanisms connecting aspartate and asparagine with schizophrenia.
In summary, our MR analysis found a negative correlation between asparagine and schizophrenia, indicating that asparagine reduces the risk of schizophrenia. However, there is no potential causal relationship between schizophrenia and asparagine. This study provides new ideas for the early detection of schizophrenia in the clinical setting and offers new insights into the etiology and pathogenesis of schizophrenia. Nonetheless, additional research is required to elucidate the potential mechanisms that underlie the association between aspartate and asparagine with schizophrenia.
Availability of data and materials
The datasets generated and analysed during the current study are available in the GWAS repository. https://gwas.mrcieu.ac.uk/datasets/met-a-388/ , https://gwas.mrcieu.ac.uk/datasets/met-a-638/ , https://gwas.mrcieu.ac.uk/datasets/ieu-b-42/ .
Charlson FJ, Ferrari AJ, Santomauro DF, Diminic S, Stockings E, Scott JG, McGrath JJ, Whiteford HA. Global epidemiology and burden of schizophrenia: findings from the global burden of disease study 2016. Schizophr Bull. 2018;44(6):1195–203.
Article PubMed PubMed Central Google Scholar
Rehm J, Shield KD. Global burden of disease and the impact of mental and addictive disorders. Curr Psychiatry Rep. 2019;21(2):10.
Article PubMed Google Scholar
Vita A, Minelli A, Barlati S, Deste G, Giacopuzzi E, Valsecchi P, Turrina C, Gennarelli M. Treatment-resistant Schizophrenia: genetic and neuroimaging correlates. Front Pharmacol. 2019;10:402.
Article CAS PubMed PubMed Central Google Scholar
Adell A. Brain NMDA receptors in schizophrenia and depression. Biomolecules. 2020;10(6):947.
Biological insights from 108 schizophrenia-associated genetic loci. Nature. 2014;511(7510):421–7.
Abdulbagi M, Wang L, Siddig O, Di B, Li B. D-Amino acids and D-amino acid-containing peptides: potential disease biomarkers and therapeutic targets? Biomolecules. 2021;11(11):1716.
Krashia P, Ledonne A, Nobili A, Cordella A, Errico F, Usiello A, D’Amelio M, Mercuri NB, Guatteo E, Carunchio I. Persistent elevation of D-Aspartate enhances NMDA receptor-mediated responses in mouse substantia Nigra pars compacta dopamine neurons. Neuropharmacology. 2016;103:69–78.
Article CAS PubMed Google Scholar
Kantrowitz JT, Epstein ML, Lee M, Lehrfeld N, Nolan KA, Shope C, Petkova E, Silipo G, Javitt DC. Improvement in mismatch negativity generation during d-serine treatment in schizophrenia: correlation with symptoms. Schizophr Res. 2018;191:70–9.
Elkis H, Buckley PF. Treatment-resistant Schizophrenia. Psychiatr Clin North Am. 2016;39(2):239–65.
Dunlop DS, Neidle A, McHale D, Dunlop DM, Lajtha A. The presence of free D-aspartic acid in rodents and man. Biochem Biophys Res Commun. 1986;141(1):27–32.
de Bartolomeis A, Vellucci L, Austin MC, De Simone G, Barone A. Rational and translational implications of D-Amino acids for treatment-resistant Schizophrenia: from neurobiology to the clinics. Biomolecules. 2022;12(7):909.
Taniguchi K, Sawamura H, Ikeda Y, Tsuji A, Kitagishi Y, Matsuda S. D-amino acids as a biomarker in schizophrenia. Diseases. 2022;10(1):9.
Singh SP, Singh V. Meta-analysis of the efficacy of adjunctive NMDA receptor modulators in chronic schizophrenia. CNS Drugs. 2011;25(10):859–85.
Errico F, Napolitano F, Squillace M, Vitucci D, Blasi G, de Bartolomeis A, Bertolino A, D’Aniello A, Usiello A. Decreased levels of D-aspartate and NMDA in the prefrontal cortex and striatum of patients with schizophrenia. J Psychiatr Res. 2013;47(10):1432–7.
Rousseau J, Gagné V, Labuda M, Beaubois C, Sinnett D, Laverdière C, Moghrabi A, Sallan SE, Silverman LB, Neuberg D, et al. ATF5 polymorphisms influence ATF function and response to treatment in children with childhood acute lymphoblastic leukemia. Blood. 2011;118(22):5883–90.
Liu L, Zhao J, Chen Y, Feng R. Metabolomics strategy assisted by transcriptomics analysis to identify biomarkers associated with schizophrenia. Anal Chim Acta. 2020;1140:18–29.
Cao B, Wang D, Brietzke E, McIntyre RS, Pan Z, Cha D, Rosenblat JD, Zuckerman H, Liu Y, Xie Q, et al. Characterizing amino-acid biosignatures amongst individuals with schizophrenia: a case-control study. Amino Acids. 2018;50(8):1013–23.
Olthof BMJ, Gartside SE, Rees A. Puncta of neuronal nitric oxide synthase (nNOS) mediate NMDA receptor signaling in the Auditory Midbrain. J Neuroscience: Official J Soc Neurosci. 2019;39(5):876–87.
Article CAS Google Scholar
Tortorella A, Monteleone P, Fabrazzo M, Viggiano A, De Luca L, Maj M. Plasma concentrations of amino acids in chronic schizophrenics treated with clozapine. Neuropsychobiology. 2001;44(4):167–71.
Rao ML, Strebel B, Gross G, Huber G. Serum amino acid profiles and dopamine in schizophrenic patients and healthy subjects: window to the brain? Amino Acids. 1992;2(1–2):111–8.
Davey Smith G, Ebrahim S. What can mendelian randomisation tell us about modifiable behavioural and environmental exposures? BMJ (Clinical Res ed). 2005;330(7499):1076–9.
Article Google Scholar
Freuer D, Meisinger C. Causal link between thyroid function and schizophrenia: a two-sample mendelian randomization study. Eur J Epidemiol. 2023;38(10):1081–8.
Papiol S, Schmitt A, Maurus I, Rossner MJ, Schulze TG, Falkai P. Association between Physical Activity and Schizophrenia: results of a 2-Sample mendelian randomization analysis. JAMA Psychiat. 2021;78(4):441–4.
Shin SY, Fauman EB, Petersen AK, Krumsiek J, Santos R, Huang J, Arnold M, Erte I, Forgetta V, Yang TP, et al. An atlas of genetic influences on human blood metabolites. Nat Genet. 2014;46(6):543–50.
Zhao JV, Kwok MK, Schooling CM. Effect of glutamate and aspartate on ischemic heart disease, blood pressure, and diabetes: a mendelian randomization study. Am J Clin Nutr. 2019;109(4):1197–206.
Zhou K, Zhu L, Chen N, Huang G, Feng G, Wu Q, Wei X, Gou X. Causal associations between schizophrenia and cancers risk: a mendelian randomization study. Front Oncol. 2023;13:1258015.
Zapata RC, Rosenthal SB, Fisch K, Dao K, Jain M, Osborn O. Metabolomic profiles associated with a mouse model of antipsychotic-induced food intake and weight gain. Sci Rep. 2020;10(1):18581.
Parksepp M, Leppik L, Koch K, Uppin K, Kangro R, Haring L, Vasar E, Zilmer M. Metabolomics approach revealed robust changes in amino acid and biogenic amine signatures in patients with schizophrenia in the early course of the disease. Sci Rep. 2020;10(1):13983.
Rao ML, Gross G, Strebel B, Bräunig P, Huber G, Klosterkötter J. Serum amino acids, central monoamines, and hormones in drug-naive, drug-free, and neuroleptic-treated schizophrenic patients and healthy subjects. Psychiatry Res. 1990;34(3):243–57.
Errico F, D’Argenio V, Sforazzini F, Iasevoli F, Squillace M, Guerri G, Napolitano F, Angrisano T, Di Maio A, Keller S, et al. A role for D-aspartate oxidase in schizophrenia and in schizophrenia-related symptoms induced by phencyclidine in mice. Transl Psychiatry. 2015;5(2):e512.
Nuzzo T, Sacchi S, Errico F, Keller S, Palumbo O, Florio E, Punzo D, Napolitano F, Copetti M, Carella M, et al. Decreased free d-aspartate levels are linked to enhanced d-aspartate oxidase activity in the dorsolateral prefrontal cortex of schizophrenia patients. NPJ Schizophr. 2017;3:16.
Errico F, Rossi S, Napolitano F, Catuogno V, Topo E, Fisone G, D’Aniello A, Centonze D, Usiello A. D-aspartate prevents corticostriatal long-term depression and attenuates schizophrenia-like symptoms induced by amphetamine and MK-801. J Neurosci. 2008;28(41):10404–14.
Nasyrova RF, Khasanova AK, Altynbekov KS, Asadullin AR, Markina EA, Gayduk AJ, Shipulin GA, Petrova MM, Shnayder NA. The role of D-Serine and D-aspartate in the pathogenesis and therapy of treatment-resistant schizophrenia. Nutrients. 2022;14(23):5142.
Hao D, Liu C. Deepening insights into food and medicine continuum within the context of pharmacophylogeny. Chin Herb Med. 2023;15(1):1–2.
PubMed Google Scholar
Zhang Y. Awareness and ability of paradigm shift are needed for research on dominant diseases of TCM. Chin Herb Med. 2023;15(4):475.
CAS PubMed PubMed Central Google Scholar
Chen J. Essential role of medicine and food homology in health and wellness. Chin Herb Med. 2023;15(3):347–8.
PubMed PubMed Central Google Scholar
Download references
This work was supported by the National Natural Science Foundation of China (82271546, 82301725, 81971601); National Key Research and Development Program of China (2023YFC2506201); Key Project of Science and Technology Innovation 2030 of China (2021ZD0201800, 2021ZD0201805); China Postdoctoral Science Foundation (2023M732155); Fundamental Research Program of Shanxi Province (202203021211018, 202203021212028, 202203021212038). Research Project Supported by Shanxi Scholarship Council of China (2022 − 190); Scientific Research Plan of Shanxi Health Commission (2020081, 2020SYS03,2021RC24); Shanxi Provincial Administration of Traditional Chinese Medicine (2023ZYYC2034), Scientific and Technological Innovation Programs of Higher Education Institutions in Shanxi (2022L132); Shanxi Medical University School-level Doctoral Initiation Fund Project (XD2102); Youth Project of First Hospital of Shanxi Medical University (YQ2203); Doctor Fund Project of Shanxi Medical University in Shanxi Province (SD2216); Shanxi Science and Technology Innovation Talent Team (202304051001049); 136 Medical Rejuvenation Project of Shanxi Province, China; STI2030-Major Projects-2021ZD0200700. Key laboratory of Health Commission of Shanxi Province (2020SYS03);
Author information
Huang-Hui Liu and Yao Gao contributed equally to this work.
Authors and Affiliations
Department of Psychiatry, First Hospital/First Clinical Medical College of Shanxi Medical University, NO.85 Jiefang Nan Road, Taiyuan, China
Huang-Hui Liu, Yao Gao, Dan Xu, Xin-Zhe Du, Si-Meng Wei, Jian-Zhen Hu, Yong Xu & Liu Sha
Shanxi Key Laboratory of Artificial Intelligence Assisted Diagnosis and Treatment for Mental Disorder, First Hospital of Shanxi Medical University, Taiyuan, China
You can also search for this author in PubMed Google Scholar
Contributions
Huang-Hui Liu and Yao Gao provided the concept and designed the study. Huang-Hui Liu and Yao Gao conducted the analyses and wrote the manuscript. Dan Xu, Huang-Hui Liu and Yao Gao participated in data collection. Xin-Zhe Du, Si-Meng Wei and Jian-Zhen Hu participated in the analysis of the data. Liu Sha, Yong Xu and Yao Gao revised and proof-read the manuscript. All authors contributed to the article and approved the submitted version.
Corresponding authors
Correspondence to Yong Xu or Liu Sha .
Ethics declarations
Ethics approval and consent to participate.
Not applicable’ for that section.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Liu, HH., Gao, Y., Xu, D. et al. Asparagine reduces the risk of schizophrenia: a bidirectional two-sample mendelian randomization study of aspartate, asparagine and schizophrenia. BMC Psychiatry 24 , 299 (2024). https://doi.org/10.1186/s12888-024-05765-5
Download citation
Received : 20 February 2024
Accepted : 15 April 2024
Published : 19 April 2024
DOI : https://doi.org/10.1186/s12888-024-05765-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Schizophrenia
- Mendelian randomization
BMC Psychiatry
ISSN: 1471-244X
- Submission enquiries: [email protected]
- General enquiries: [email protected]

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Sample size determination with a pilot study
Ben o’neill.
Research School of Population Health, Australian National University, Canberra, Australia
Associated Data
All relevant data are within the manuscript.
We analyse standard confidence intervals for the mean of a finite population, with a view to sample size determination. We first consider a standard method for sample size determination based on the assumption of knowledge of the population variance parameter. We then consider the more realistic case where the population variance is treated as an unknown, and we derive a new method of sample size determination that accounts for the uncertainty in this parameter. We develop a sample size calculation method based on a preliminary sample of data which allows us to increase the accuracy of our inference by some specified amount with a specified level of confidence. We compare this method to the standard method.
1. Introduction
Statistical studies require data, and one is often presented with situations in which the amount of data is (at least partially) under the control of the experimenter. This gives rise to a trade-off problem for the experimenter—more data allows more accurate inference of parameters of interest, but it comes at a cost. The experimenter requires some means of balancing these considerations and this requires an understanding of the likely accuracy of the survey based on a given amount of data. This, briefly, is the problem of sample-size determination.
Adequate determination of sample sizes is particularly important in view of the consequence of failure. The collection of data has a resource cost (money, time, etc.) and there may also be other harms to consider from experimentation to obtain the relevant data (e.g., in medical studies there may be patient harm or sub-optimal treatment as part of experimentation). A sample which is too small can mean that the inferences from the statistical study are not of any practical value, and this is obviously something to be avoided. However, a sample which is too large means that the inferences from the statistical study are more precise than they need to be for practical purposes, and this often entails an unnecessary loss of resources or creation of harms.
In this paper we will consider the problem of sample size determination for a simple problem involving inference about the unknown mean of a finite population of values. We consider the case where there has been a pilot survey from the population, or some past survey from the population which can act as a pilot. Inference about the mean will be obtained using a classical confidence interval and accuracy is measured by the length of the interval. The goal will be to determine the minimum number of additional sample values which are needed to obtain some level of confidence about the length of the confidence interval which is the object of our inference.
Since the length of the confidence interval is affected by the variance of the population values this requires some consideration. [ 1 ] gives some practical advice on sample size determination, and notes that, in practice, the unknown variance parameter is estimated in these cases either from historical data, from the beliefs of experts, or from a pilot study (see pp. 189–190 for discussion). In the case of historical data or a pilot study there will be a set of actual data from the population. In the case of expert beliefs, it is possible to consider the information as a pseudo data-set, with specified sample size and moments representing the strength and nature of the expert beliefs. Each of these cases can therefore be considered in essentially the same way, by considering an existing data set from the population and using this to determine how many additional sample values are needed.
2. Sampling from a finite population
Confidence intervals for inference pertaining to the mean of a population are an established staple of introductory classical statistics. These inferential tools are frequently presented in introductory statistics textbooks in order to give students an appreciation of the nature of classical inference along with the law of large numbers and the central limit theorem (e.g., [ 2 – 4 ]). Derivation of confidence intervals for the mean and variance of a finite population can be found in [ 5 ] along with some useful moment results pertaining to this problem. One important part of this subject is to give an appreciation for the information contained in data from random sampling and the effect of sample size on accuracy. This can be considered through an examination of the required sample size for inferences at a certain level of accuracy, as determined by the length of appropriate confidence intervals.
Sampling problems are usually undertaken using the technique of simple random sampling without replacement. Mathematically, this method is most usefully expressed as the selection of values from an exchangeable population of values, usually considered to be embedded within an exchangeable superpopulation of random variables. Even for problems involving sampling from a finite population it is useful to regard the finite population as embedded in an infinite sequence of this kind (see [ 6 ]). This method allows us to consider any finite population as embedded in a wider sequence with simple properties, and it allows us to give an operational approach to the interpretation of model parameters (see e.g., [ 7 ], pp. 234–240).
In line with this approach, we consider an exchangeable superpopulation X = ( X 1 , X 2 , X 3 ,…) composed of real random variables. Since the sequence is exchangeable, this ensures that the elements of this sequence are independent and identically distributed (IID) conditional on the underlying empirical distribution of the sequence (see [ 8 ] for discussion). Since each element in the sequence is identically distributed we set μ = E ( X i ) and σ 2 = V ( X i ) as the common mean and variance, which are functions of the superpopulation values. (We will also use the kurtosis parameter κ which is defined by κ σ 4 = E ( ( X i − μ ) 4 ) .) The parameters can be expressed operationally as limits of functions from the sequence, having recourse to the laws of large numbers to justify this operational definition.
Within this superpopulation we will consider a finite population X N = ( X 1 , X 2 ,…, X N ) and a smaller sample X n = ( X 1 , X 2 ,…, X n ) taken from this population. (Since the sample is taken as the first n values of an exchangeable superpopulation it is implicitly a simple random sample without replacement from the finite population.) This sample contains n observed data values and the population vector contains an additional N − n unobserved values (the total population size is N ). The sample mean and variance and the population mean and variance are defined respectively by:
(The reader should note that we incorporate Bessel’s correction into the population variance, which is contrary to the approach taken in some texts. This differs from some other treatments of sampling which use N as the denominator in the population variance. The reason we incorporate Bessel’s correction is that it makes sense to consider the finite population variance as an estimator of the superpopulation variance in this context. This correction ensures that the sample variance and population variance both have the same expected value σ 2 and therefore function as unbiased estimators of this quantity.)
The sample moments X ¯ n and S n 2 can be used to make inferences about the mean and variance of the superpopulation or population using standard results in statistical theory. We will consider the case where we wish to use our sample data to make an inference about the unknown mean of the finite population. In particular, we will form a confidence interval for the mean X ¯ N of the finite population. This interval is derived in [ 5 ] based on the central limit theorem. The 1− α level confidence interval for the population mean is given by:
The degrees-of-freedom function DF n depends on the kurtosis parameter κ (note that this is the raw kurtosis, not the excess kurtosis) which is unknown in practice. This unknown parameter can be replaced with an appropriate estimator to obtain the appropriate degrees-of-freedom and thereby obtain the confidence interval (see [ 5 ], Appendix II). This is the standard confidence interval form for inference about the finite population mean, except that textbooks on this topic operate under the assumption of a mesokurtic distribution where κ = 3 and so DF n = n −1 (often without disclosing that assumption).
Since the kurtosis parameter is unknown in practice, one might therefore wonder: why complain about the assumption that the population variance is known, when removal of this assumption then treats the population kurtosis as known? The value of the latter approach is that the kurtosis parameter only enters into the confidence interval through the degrees-of-freedom function so that it has a minor effect on the interval. We therefore gain something by treating the population variance as unknown, even though this gives us an interval framed in terms of the unknown kurtosis parameter.
The above confidence interval is also similar to the familiar confidence interval for inference about the parameter μ , except that we have an additional correction term which scales the length of the interval down to take account of the fact that we have knowledge of a non-zero proportion of the population values. As N →∞ the population becomes a superpopulation and the proportion of sampled values approaches zero, so that the correction term approaches unity. In this case we obtain the more familiar confidence interval for μ given by:
We can regard the standard confidence interval for μ as a special case of the more general interval that allows for a finite population. We will therefore proceed on the basis of the more general case, with inference about μ being a special case.
Accuracy of our inference is determined by the length of the confidence interval, which is proportional to the sample standard deviation. The length of this interval is:
A shorter confidence interval corresponds to a more accurate inference and a wider interval corresponds to a less accurate inference. Since the sample standard deviation is unknown the length of the interval is unknown prior to seeing the data. Given that this length gives us a measure of accuracy, our goal will be to determine the minimum sample size that is sufficient to give some reasonable confidence that this length will be within an acceptable upper bound.
3. Sample size determination with known-variance
One unfortunate aspect of many theoretical treatments of sample size determination is the tendency to focus on the unrealistic case of a population with unknown mean but known variance. This leads to a standard form of confidence interval with accompanying theory which fails to take account of the uncertainty in the variance of the population. Methods for determining the required sample size for a particular level of accuracy (i.e., a confidence interval of a certain length) are treated in this way in standard texts on sampling theory such as [ 9 ] and [ 10 ]. These texts derive the required sample size based on a known population variance, which has the effect of understating the required size once we account for uncertainty in the variance. This is the way in which the subject is presented to early undergraduates, and the consequence is to give a highly unrealistic treatment of the problem. We consider this method in the present section.
In determining the sample size required for a particular level of accuracy, we are faced with the difficulty that the sample size is not fully determinative of the length of the interval. One simple method of dealing with this difficulty is to assume away the complication by treating the population variance as if it were a known quantity in the analysis. If the parameter σ is assumed to be known then the pivot statistic used to form the confidence interval is normally distributed instead of having a T-distribution. In this case we obtain the interval formulae:
This form of confidence interval is based on the unrealistic situation in which μ is unknown and σ is known. It is often presented in introductory statistical courses. Following [ 9 ] and [ 10 ] the standard sample size calculation for confidence intervals for a population mean assumes knowledge of the parameter σ . This uses the confidence interval above, based on the normal pivot statistic, which has length given by:
Setting L n σ = 2 H (giving half-length H ) and solving for n gives us:
This is the sample size required to achieve a confidence interval with length 2 H for inference about the finite population mean. (This formula will generally yield a non-integer value. To find the required sample size we round up to the next integer.) As N →∞ we have n → n 0 so that n 0 represents the required sample size for inference about the superpopulation mean.
This method assumes that the variance parameter is known, but in practice this parameter is often taken from a pilot sample or historical data, and the sample variance from the pilot sample is substituted as the parameter σ . Hence, what is really occurring is that the analyst treats an estimate of the variance parameter as if it were perfectly accurate. To accommodate this case, we will suppose we have an existing sample of n objects and we want to sample more data points to reduce the length of our confidence interval, relative to the length of the confidence interval obtained from the preliminary sample. The sample variance in the original sample is taken to be a perfect estimator of the variance parameter, so that it is treated as known. To do this we will choose some number 0≤ k ≤ N − n of additional data points. We will consider the ratio of the length values for the confidence intervals formed from the full data set and the preliminary data set. This length ratio is given by:
This is a decreasing function of k which means that as we obtain more data the size of the confidence interval decreases. This follows from the fact that we are using a fixed variance value. By specifying the ratio 0< R <1 we can easily determine the required number k of additional data points that are needed to reduce the present length of the confidence interval from the preliminary data.
We consider an example used in [ 10 ] (pp. 16, 37) using data taken from and aerial survey of a caribou population. Suppose we have a preliminary sample of n = 15 data points from a population of N = 286. The full sample is given by:
From this sample we obtain the statistics x ¯ n = 25.933 and s n = 30.316. If we assume that σ = s n = 30.316 then the 90% confidence interval for the finite population mean X ¯ N from our preliminary sample is:
We want to know the number of data points required to estimate the population mean with sufficient accuracy to be within ±2000 of the true population total. This means that the required interval half-length for the population mean is H = 2000/ N = 2000/286 = 6.993 so that the required length ratio is:
The first integer value satisfying this upper bound is k = 29 where we have R ( k ) = 0.5517. This means that we need an additional k = 29 data points for our total sample bringing us to n + k = 44 data points out of N = 286. Fig 1 above shows how the ratio of the lengths decreases as k increases. When k = 0 the length ratio is unity, and when k = 271 all the remaining objects in the population have been sampled so that the length ratio is zero. Between these extremes the length of the interval reduces commensurate with the information given by the additional data. The sample size derived in the present case can be seen on the figure.

4. An improved sample size determination method
We will again consider the case where we have a preliminary sample of n data points from a population of N data points. We will again choose some number 0≤ k ≤ N − n of additional data points in an attempt to obtain an inference with some required level of accuracy, which we determine through the length of our confidence interval. However, we will now take account of the uncertainty the variance by dealing with the confidence intervals using the sample standard deviation.
To determine the appropriate value of k for our inference we will again consider the lengths of the intervals. The ratio of the lengths of the total sample of n + k values to the existing sample of n values is now given by:
Unlike in the standard method, this length ratio is now a random variable, and this means that we will want to determine its distribution. To determine the distribution of the length ratio we consider the distribution of the ratio of nested sample variances in the above ratio form. We use the following asymptotic distributional result (see Appendix ):
(The notation F ( DF C , DF n ) here refers to Snedecor’s F distribution with numerator degrees-of-freedom DF C and denominator degrees-of-freedom DF n .) This distributional is exact for normal values, or holds as an asymptotic distribution by appeal to the central limit theorem as n →∞ and k →∞. It holds as an adequate approximation when n and k are large. This gives us an implied distributional form for the length ratio bound, which we can use to determine the required sample size for a given level of accuracy.
In the standard method which assumes a known variance parameter our ratio bound was fully determined by the relevant population and sample sizes so that we could specify the required length ratio directly. Since our length ratio is now a random variable we must refine what it means to specify the required accuracy. In addition to specifying a required length ratio we will now also specify some confidence level 1− δ such that the required length ratio bound holds at the specified confidence level. (Do not confuse the two confidence levels: the confidence interval of interest has confidence level 1− α and the sample size determination uses confidence level 1− δ .)
Using the relevant critical point of the F distribution, we have the following approximation result which holds when n and k are large (or when the data are close to normal):
where we define the length-ratio bound function R δ by:
Hence, with confidence level 1− δ we know that using k additional data points will reduce the length of the confidence interval by the multiplicative factor R δ ( k ) or less. It is then easy to choose k to satisfy some required reduction in length, at some specified confidence level.
The function R δ is also implicitly dependent on the kurtosis parameter κ through the degrees-of-freedom quantities DF C , DF n and DF n + k . In practice we will either estimate this from the data in the pilot survey or assume the value of this parameter to be known. (In the special case where we are willing to assume a mesokurtic distribution we have κ = 3 so that the degrees-of-freedom quantities become DF C = k , DF n = n −1 and DF n + k = n + k −1.)
Continuing Example 1, we will now apply our new sample size determination method to the previous example. Recall that we want to reduce the length of the confidence interval from the preliminary data set by the factor R = 0.5580 by taking additional data points. If we want this reduction to occur with 99% confidence then we set δ = 0.01 and examine the length-ratio boundary function at this confidence level. (In this case we will simplify our problem by assuming a mesokurtic distribution, so that κ = 3.) The first integer value satisfying the required upper bound is k = 72 where we have R δ ( k ) = 0.5554 (shown in the plot below). This means that we need an additional k = 72 data points for our total sample bringing us to n + k = 87 data points out of N = 286. This is substantially higher than what we estimated in Example 1 when we used the standard method which assumed a known variance parameter. The reason for this is that we are now taking into account the fact that the sample variance will change as we obtain new data and this additional uncertainty with affect the interval length. Fig 2 below shows the length ratio as a function of the number of additional data points, taking into account the uncertainty in the population variance. The additional uncertainty means that we now require more data points than in Example 1.

The full plot shows how the ratio of the lengths changes as k increases. Unlike in the case of the standard method this is no longer a decreasing function in this case (it is quasi-concave). When k = 0 the length ratio is unity, but as k increases the bound initially increases before starting to decrease again. The reason for this is that a small number of additional data points increases the uncertainty in the sample variance ratio, and can plausibly lead to an increase in the length of the confidence interval of interest, since the additional data points may actually increase the sample standard deviation more than they reduce the weight applied to this sample standard deviation in the interval. (Since we use a 90% confidence interval, we look at the extreme that occurs when the quantile of the variance ratio in the top 10% of its distribution.) As more additional data points are taken, this effect is overcome by the reduction in length due to a larger sample size and the function starts to decrease. When k = 271 all the objects in the population have been sampled in the full sample so that the length ratio is zero.
(In some cases we may not want to use the preliminary data in our new confidence interval.) In this case the length ratio of the preliminary interval and the final interval is given by:
(The quantity S n : k 2 in this equation is the standard deviation of the additional sample of k data points, without inclusion of the preliminary sample of n data points.) We use the following asymptotic distributional result (see Appendix ):
This leads to the length-ratio boundary function:
This would be used as an alternative when we do not want to include the preliminary data in our new confidence interval and we are selecting our new data using simple random sampling from the entire population.)
5. Comparison of methods
The present method improves on the standard method that assumes the variance parameter to be known. The improvement follows directly by incorporating the uncertainty in the variance estimate. Except for very low confidence levels this leads to larger required sample sizes than are determined under the standard method, with the higher sample size required in order to account for the additional uncertainty in the absence of this assumption.
It is worth noting that both of these methods rely on distributional approximations based on the central limit theorem, so that both methods are susceptible to problems in dealing with small samples or heavy-tailed distributions. This can be regarded as an inherent limitation on both methods, which is unlikely to be alleviated unless there is information on the form of distribution of the superpopulation. Nevertheless, the present method is no worse in this regard than the standard sample size determination method, and can be regarded as an improvement insofar as it removes one unrealistic assumption in that analysis.
It is easy to compare the length ratio functions of the two methods by looking at the function A δ . This function determines the difference in the length ratio bound under the two methods. It is easy to show that this is a decreasing function of δ so that higher levels of confidence (lower values of δ ) for the required sample size lead to a higher length ratio bound under the method set out in this paper. To see the difference in the length bounds for various different confidence levels, and in comparison to the standard method, we show the length ratio bound using the values of n and N in Example 1 in Fig 3 below. We can see that the length ratio bound function reduces as we reduce our confidence level. We note that our figure here shows values of k = N − n that begin low, notwithstanding that we use asymptotic distributions.

In Fig 3 we can see that the standard method gives us an effective confidence that is somewhere between the 50% and 70% levels. We can be more precise that this by plotting the effective confidence level of the method, defined by setting A δ ( k ) = 1 and solving for δ . (This effective confidence level does not depend on N .) (This also requires specification of the kurtosis parameter, which can either be estimated from the pilot sample or specified by assumption.) The effective confidence level for a mesokurtic distribution is shown in Fig 4 below for all values of k ≥1 using the number of preliminary data points in Example 1.

Fig 4 shows that the effective confidence level is about 55% with exact level depending on k . This means that the standard method would not give a high level of confidence of actually achieving the desired reduction in the length of the confidence interval—in fact, this would occur slightly more often than half the time. The remainder of the time the new data points in the sample would increase the sample standard deviation so that the new confidence interval is wider than would have been expected under the standard method. This illustrates a major drawback in the standard method—by taking the variance parameter to be known it effectively ignores the sample variance estimator, and thereby ignores the possibility that the sample variance may increase once the new data is taken.
We can see that the effective confidence of the standard method approaches a limiting value as k →∞. Since lim k → ∞ F δ , D F C , D F n = D F n / χ 1 − δ , D F n 2 and lim k → ∞ t α / 2 , D F n + k = z α / 2 we have:
Hence, taking A δ (∞) = 1 we have the equation:
Solving for δ we obtain the limiting value of the effective confidence level. Using the values from Example 1 (assuming a mesokurtic distribution) we have a limiting confidence level of 54.78%. This is the limiting value for the plot in Fig 4 .
Since the standard method is based on the assumption that σ is known, it is also instructive to see what happens when the value of n is large, so that we have a very good inference about the parameter σ (i.e., it is almost known). Setting the value τ ≡2/( κ −1) it can be shown that lim n → ∞ F δ , D F C , D F n = χ δ , τ k 2 / τ k so that:
This means that as n →∞ the length ratio bound calculated under the present method (at any confidence level) converges towards the length ratio for the standard method. This accords with our intuitive understanding of the estimation process, since n →∞ means that we are gaining perfect knowledge of the parameter σ , which is the assumption underlying the standard sample size determination method.
As a caveat to the above analysis, we note that our figures consider values of k = N − n that begin at zero and go upward spanning low values. Our figures also use n = 15, which is not a particularly high value. Since we use asymptotic distributions derived from the central limit theorem for the variance ratios in our analysis, the particular results shown in the figures are likely to be accurate only when the underlying distribution of the data is close to a normal distribution. Nevertheless, even with this shortcoming (which really cannot be avoided), our analysis is still likely to be an improvement over the standard sample-size analysis derived from the Z test, since it now accounts for uncertainty in the sample variance.
6. Conclusion
The present paper improves on the standard method for sample size determination using a preliminary sample in a standard single sample confidence interval problem. This improved method uses the distribution of the nested sample variance ratio to establish the length ratio bound that can be obtained with a given level of confidence. This allows the user to determine the number of additional data points required to obtain a given length bound for the confidence interval with a pre-specified level of confidence.
It would be possible to extend the present technique to obtain length ratio bound functions in other standard confidence interval problems involving mean comparison for multiple populations or stratified sampling from a single population. This could be done using the Welch-Satterwaite approximation that is used in the construction of these intervals. This would give a greater level of confidence of adequate sample size than techniques which rely on an assumption of known variance.
Appendix: Approximating distributions
Here we show some approximate distributional results adapted from [ 5 ] that are used in the main body of the paper. These results are based on use of the central limit theorem, so they hold exactly when the data is normal, or approximately when n and k are large.
For large n and k we have:
Proof of Result 1
The first distributional approximation uses Result 14 of [ 5 ] (p. 285), which shows that:
Taking N = n + k the formula for DF n : N reduces to the one in the theorem, and we have:
The second distributional approximation is based on Result 15 of [ 5 ] (p. 286), which shows that:
We note that the inverse of an F-distributed random variable is also an F-distributed random variable with its degrees-of-freedom parameters reversed, so F ( DF C , DF n )~1/ F ( DF C , DF n ). Taking N = n + k the formula for DF C reduces to the one in the theorem, and we have:
This establishes the distributional results that were to be shown.
Funding Statement
The author(s) received no specific funding for this work.
Data Availability
IMAGES
VIDEO
COMMENTS
Advantages. Limitations. Examples. A pilot study, also known as a feasibility study, is a small-scale preliminary study conducted before the main research to check the feasibility or improve the research design. Pilot studies can be very important before conducting a full-scale research project, helping design the research methods and protocol.
When pilot studies are found in research publications, ... They stated that "the use of a pilot study to test the method and interview guide further adds credibility and dependability to the study" (p. 417). ... (2018). A novel qualitative method to improve access, elicitation, and sample diversification for enhanced transferability applied ...
Pilot studies are a necessary first step to assess the feasibility of methods and procedures to be used in a larger study. Some consider pilot studies to be a subset of feasibility studies (), while others regard feasibility studies as a subset of pilot studies.As a result, the terms have been used interchangeably ().Pilot studies have been used to estimate effect sizes to determine the sample ...
The Concise Oxford Thesaurus [] defines a pilot project or study as an experimental, exploratory, test, preliminary, trial or try out investigation.Epidemiology and statistics dictionaries provide similar definitions of a pilot study as a small scale" ...test of the methods and procedures to be used on a larger scaleif the pilot study demonstrates that the methods and procedures can work" [];
Researchers use information gathered in pilot studies to refine or modify the research methodology for a study and to develop large-scale studies: ... Therefore if not used cautiously, results of pilot studies can potentially mislead sample size or power calculations -- particularly if the pilot study was done to see if there is likely to be a ...
Introduction. Prior to a definitive intervention trial, a pilot study may be undertaken. Pilot trials are often small versions of the main trial, undertaken to test trial methods and procedures. 1, 2 The overall aim of pilot studies is to demonstrate that a future trial can be undertaken. To address this aim, there are a number of objectives for a pilot study including assessing recruitment ...
Sources of Funding for Pilot Studies K24 (Mid-Career award in Patient-Oriented research) Up to $50,000 a year can be used to provide pilot funding K07 (Academic Leadership Award) A portion of the award may be used for pilot funding NIH Clinical and Translational Science Awards (CTSA) have local small grant or pilot study mechanisms
Pilot testing, or the act of conducting a pilot study, is a crucial phase in the process, especially in qualitative and social science research. It serves as a preparatory step, a preliminary test, allowing researchers to evaluate, refine, and if necessary, redesign aspects of their study before full implementation, as well as determine the ...
In 2004, a review of pilot studies published in seven major medical journals during 2000-01 recommended that the statistical analysis of such studies should be either mainly descriptive or focus on sample size estimation, while results from hypothesis testing must be interpreted with caution. We revisited these journals to see whether the subsequent recommendations have changed the practice of ...
However, similar to the effect size, the SD can be imprecisely estimated due to the pilot's small sample size. Using a pilot study's SD to design a future sample size has been shown to often result in an underpowered study. Citation 23, Citation 24 Thus, sensitivity analyses should be undertaken.
Implementation trials aim to test the effects of implementation strategies on the adoption, integration or uptake of an evidence-based intervention within organisations or settings. Feasibility and pilot studies can assist with building and testing effective implementation strategies by helping to address uncertainties around design and methods, assessing potential implementation strategy ...
Conducting a pilot study is an essential step in many research projects. Here's a general guide on how to conduct a pilot study: Step 1: Define Objectives. Inspect what specific aspects of your main study do you want to test or evaluate in your pilot study. Step 2: Evaluate Sample Size. Decide on an appropriate sample size for your pilot study.
Pilot testing is a preliminary test or study conducted before a larger-scale study. A pilot study can present key information that can help guide the direction of the larger study or research project, including providing insights into the ultimate cost of the study, its overall feasibility, and any challenges that the actual study may face once it gets off the ground.
CHAPTER 5 PILOT STUDY. 1. INTRODUCTION. The pilot study of the current research was the first step of the practical application of the Gestalt play therapy emotional intelligence programme for primary school children. It is also the last step of the first grouping of steps of an intervention research study (De Vos, 2002:409-418) namely ...
A pilot study is the first. step of the entire research p rotocol and is often a smaller-sized. study assisting in planning and m odification of the main study. [1,2]. More specifically, in large ...
A pilot study is the first step of the entire research protocol and is often a smaller-sized study assisting in planning and modification of the main study [, ]. More specifically, in large-scale clinical studies, the pilot or small-scale study often precedes the main trial to analyze its validity. Before a pilot study begins, researchers must ...
Key Takeaways. 1. A pilot study is a small-scale preliminary study conducted to evaluate feasibility of the key steps in a future study. 2. Any research method can be applied to a pilot study, but some of the most frequently used are randomised control trails and surveys. 3.
Pilot study. At the concluding phase of the explanatory study method, a sample investigation was carried out. The survey questionnaire should be assessed by way of the sample research prior to being executed amongst the populace (Saunders et al., 2003). The chief intent of the sample study is to guarantee that participants are not subjected to ...
pilot studies in qualitative inquiry are particularly identified. To highlight the benefits of pilot work, it describes the. specific practical and methodological issues emerging in the. pilot ...
research methodology for a study and to develop large-scale studies ... examples. 4. Relationships between Pilot Studies, Proof-of-Concept Studies, and Adaptive Designs A proof-of-concept (PoC) study is defined as a clinical trial carried out to determine if a treatment (drug) is
The purpose of conducting a pilot study is to examine the feasibility of an approach that is intended to be used in a larger scale study. The roles and limitations of pilot studies are described here using a clinical trial as an example. A pilot study can be used to evaluate the feasibility of recruitment, randomization, retention, assessment ...
Writing Survey Questions. Perhaps the most important part of the survey process is the creation of questions that accurately measure the opinions, experiences and behaviors of the public. Accurate random sampling will be wasted if the information gathered is built on a shaky foundation of ambiguous or biased questions.
The reconstruction of the porous media model is crucial for researching the mesoscopic seepage characteristics of porous concrete. Based on a self-compiled MATLAB program, a porous concrete model was modeled by controlling four parameters (distribution probability, growth probability, probability density, and porosity) with clear physical meanings using a quartet structure generation set (QSGS ...
The aims and methods of a pilot study must be aligned with the goals of the subsequent study. For example, ... Alignment of the rationale with the scientific aims of the research is critical. Choosing a sample size for pilot studies requires judgment and aims‐specific considerations of the issues of practical feasibility, the details of the ...
Despite ongoing research, the underlying causes of schizophrenia remain unclear. Aspartate and asparagine, essential amino acids, have been linked to schizophrenia in recent studies, but their causal relationship is still unclear. This study used a bidirectional two-sample Mendelian randomization (MR) method to explore the causal relationship between aspartate and asparagine with schizophrenia.
Setting L n σ = 2 H (giving half-length H) and solving for n gives us: n = 1 1 / n 0 + 1 / N n 0 = z α / 2 2 ∙ σ 2 H 2. This is the sample size required to achieve a confidence interval with length 2 H for inference about the finite population mean. (This formula will generally yield a non-integer value. To find the required sample size we ...