- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Try Thematic
Welcome to the community


Qualitative Data Analysis: Step-by-Step Guide (Manual vs. Automatic)
When we conduct qualitative methods of research, need to explain changes in metrics or understand people's opinions, we always turn to qualitative data. Qualitative data is typically generated through:
- Interview transcripts
- Surveys with open-ended questions
- Contact center transcripts
- Texts and documents
- Audio and video recordings
- Observational notes
Compared to quantitative data, which captures structured information, qualitative data is unstructured and has more depth. It can answer our questions, can help formulate hypotheses and build understanding.
It's important to understand the differences between quantitative data & qualitative data . But unfortunately, analyzing qualitative data is difficult. While tools like Excel, Tableau and PowerBI crunch and visualize quantitative data with ease, there are a limited number of mainstream tools for analyzing qualitative data . The majority of qualitative data analysis still happens manually.
That said, there are two new trends that are changing this. First, there are advances in natural language processing (NLP) which is focused on understanding human language. Second, there is an explosion of user-friendly software designed for both researchers and businesses. Both help automate the qualitative data analysis process.
In this post we want to teach you how to conduct a successful qualitative data analysis. There are two primary qualitative data analysis methods; manual & automatic. We will teach you how to conduct the analysis manually, and also, automatically using software solutions powered by NLP. We’ll guide you through the steps to conduct a manual analysis, and look at what is involved and the role technology can play in automating this process.
More businesses are switching to fully-automated analysis of qualitative customer data because it is cheaper, faster, and just as accurate. Primarily, businesses purchase subscriptions to feedback analytics platforms so that they can understand customer pain points and sentiment.

We’ll take you through 5 steps to conduct a successful qualitative data analysis. Within each step we will highlight the key difference between the manual, and automated approach of qualitative researchers. Here's an overview of the steps:
The 5 steps to doing qualitative data analysis
- Gathering and collecting your qualitative data
- Organizing and connecting into your qualitative data
- Coding your qualitative data
- Analyzing the qualitative data for insights
- Reporting on the insights derived from your analysis
What is Qualitative Data Analysis?
Qualitative data analysis is a process of gathering, structuring and interpreting qualitative data to understand what it represents.
Qualitative data is non-numerical and unstructured. Qualitative data generally refers to text, such as open-ended responses to survey questions or user interviews, but also includes audio, photos and video.
Businesses often perform qualitative data analysis on customer feedback. And within this context, qualitative data generally refers to verbatim text data collected from sources such as reviews, complaints, chat messages, support centre interactions, customer interviews, case notes or social media comments.
How is qualitative data analysis different from quantitative data analysis?
Understanding the differences between quantitative & qualitative data is important. When it comes to analyzing data, Qualitative Data Analysis serves a very different role to Quantitative Data Analysis. But what sets them apart?
Qualitative Data Analysis dives into the stories hidden in non-numerical data such as interviews, open-ended survey answers, or notes from observations. It uncovers the ‘whys’ and ‘hows’ giving a deep understanding of people’s experiences and emotions.
Quantitative Data Analysis on the other hand deals with numerical data, using statistics to measure differences, identify preferred options, and pinpoint root causes of issues. It steps back to address questions like "how many" or "what percentage" to offer broad insights we can apply to larger groups.
In short, Qualitative Data Analysis is like a microscope, helping us understand specific detail. Quantitative Data Analysis is like the telescope, giving us a broader perspective. Both are important, working together to decode data for different objectives.
Qualitative Data Analysis methods
Once all the data has been captured, there are a variety of analysis techniques available and the choice is determined by your specific research objectives and the kind of data you’ve gathered. Common qualitative data analysis methods include:
Content Analysis
This is a popular approach to qualitative data analysis. Other qualitative analysis techniques may fit within the broad scope of content analysis. Thematic analysis is a part of the content analysis. Content analysis is used to identify the patterns that emerge from text, by grouping content into words, concepts, and themes. Content analysis is useful to quantify the relationship between all of the grouped content. The Columbia School of Public Health has a detailed breakdown of content analysis .
Narrative Analysis
Narrative analysis focuses on the stories people tell and the language they use to make sense of them. It is particularly useful in qualitative research methods where customer stories are used to get a deep understanding of customers’ perspectives on a specific issue. A narrative analysis might enable us to summarize the outcomes of a focused case study.
Discourse Analysis
Discourse analysis is used to get a thorough understanding of the political, cultural and power dynamics that exist in specific situations. The focus of discourse analysis here is on the way people express themselves in different social contexts. Discourse analysis is commonly used by brand strategists who hope to understand why a group of people feel the way they do about a brand or product.
Thematic Analysis
Thematic analysis is used to deduce the meaning behind the words people use. This is accomplished by discovering repeating themes in text. These meaningful themes reveal key insights into data and can be quantified, particularly when paired with sentiment analysis . Often, the outcome of thematic analysis is a code frame that captures themes in terms of codes, also called categories. So the process of thematic analysis is also referred to as “coding”. A common use-case for thematic analysis in companies is analysis of customer feedback.
Grounded Theory
Grounded theory is a useful approach when little is known about a subject. Grounded theory starts by formulating a theory around a single data case. This means that the theory is “grounded”. Grounded theory analysis is based on actual data, and not entirely speculative. Then additional cases can be examined to see if they are relevant and can add to the original grounded theory.

Challenges of Qualitative Data Analysis
While Qualitative Data Analysis offers rich insights, it comes with its challenges. Each unique QDA method has its unique hurdles. Let’s take a look at the challenges researchers and analysts might face, depending on the chosen method.
- Time and Effort (Narrative Analysis): Narrative analysis, which focuses on personal stories, demands patience. Sifting through lengthy narratives to find meaningful insights can be time-consuming, requires dedicated effort.
- Being Objective (Grounded Theory): Grounded theory, building theories from data, faces the challenges of personal biases. Staying objective while interpreting data is crucial, ensuring conclusions are rooted in the data itself.
- Complexity (Thematic Analysis): Thematic analysis involves identifying themes within data, a process that can be intricate. Categorizing and understanding themes can be complex, especially when each piece of data varies in context and structure. Thematic Analysis software can simplify this process.
- Generalizing Findings (Narrative Analysis): Narrative analysis, dealing with individual stories, makes drawing broad challenging. Extending findings from a single narrative to a broader context requires careful consideration.
- Managing Data (Thematic Analysis): Thematic analysis involves organizing and managing vast amounts of unstructured data, like interview transcripts. Managing this can be a hefty task, requiring effective data management strategies.
- Skill Level (Grounded Theory): Grounded theory demands specific skills to build theories from the ground up. Finding or training analysts with these skills poses a challenge, requiring investment in building expertise.
Benefits of qualitative data analysis
Qualitative Data Analysis (QDA) is like a versatile toolkit, offering a tailored approach to understanding your data. The benefits it offers are as diverse as the methods. Let’s explore why choosing the right method matters.
- Tailored Methods for Specific Needs: QDA isn't one-size-fits-all. Depending on your research objectives and the type of data at hand, different methods offer unique benefits. If you want emotive customer stories, narrative analysis paints a strong picture. When you want to explain a score, thematic analysis reveals insightful patterns
- Flexibility with Thematic Analysis: thematic analysis is like a chameleon in the toolkit of QDA. It adapts well to different types of data and research objectives, making it a top choice for any qualitative analysis.
- Deeper Understanding, Better Products: QDA helps you dive into people's thoughts and feelings. This deep understanding helps you build products and services that truly matches what people want, ensuring satisfied customers
- Finding the Unexpected: Qualitative data often reveals surprises that we miss in quantitative data. QDA offers us new ideas and perspectives, for insights we might otherwise miss.
- Building Effective Strategies: Insights from QDA are like strategic guides. They help businesses in crafting plans that match people’s desires.
- Creating Genuine Connections: Understanding people’s experiences lets businesses connect on a real level. This genuine connection helps build trust and loyalty, priceless for any business.
How to do Qualitative Data Analysis: 5 steps
Now we are going to show how you can do your own qualitative data analysis. We will guide you through this process step by step. As mentioned earlier, you will learn how to do qualitative data analysis manually , and also automatically using modern qualitative data and thematic analysis software.
To get best value from the analysis process and research process, it’s important to be super clear about the nature and scope of the question that’s being researched. This will help you select the research collection channels that are most likely to help you answer your question.
Depending on if you are a business looking to understand customer sentiment, or an academic surveying a school, your approach to qualitative data analysis will be unique.
Once you’re clear, there’s a sequence to follow. And, though there are differences in the manual and automatic approaches, the process steps are mostly the same.
The use case for our step-by-step guide is a company looking to collect data (customer feedback data), and analyze the customer feedback - in order to improve customer experience. By analyzing the customer feedback the company derives insights about their business and their customers. You can follow these same steps regardless of the nature of your research. Let’s get started.
Step 1: Gather your qualitative data and conduct research (Conduct qualitative research)
The first step of qualitative research is to do data collection. Put simply, data collection is gathering all of your data for analysis. A common situation is when qualitative data is spread across various sources.
Classic methods of gathering qualitative data
Most companies use traditional methods for gathering qualitative data: conducting interviews with research participants, running surveys, and running focus groups. This data is typically stored in documents, CRMs, databases and knowledge bases. It’s important to examine which data is available and needs to be included in your research project, based on its scope.
Using your existing qualitative feedback
As it becomes easier for customers to engage across a range of different channels, companies are gathering increasingly large amounts of both solicited and unsolicited qualitative feedback.
Most organizations have now invested in Voice of Customer programs , support ticketing systems, chatbot and support conversations, emails and even customer Slack chats.
These new channels provide companies with new ways of getting feedback, and also allow the collection of unstructured feedback data at scale.
The great thing about this data is that it contains a wealth of valubale insights and that it’s already there! When you have a new question about user behavior or your customers, you don’t need to create a new research study or set up a focus group. You can find most answers in the data you already have.
Typically, this data is stored in third-party solutions or a central database, but there are ways to export it or connect to a feedback analysis solution through integrations or an API.
Utilize untapped qualitative data channels
There are many online qualitative data sources you may not have considered. For example, you can find useful qualitative data in social media channels like Twitter or Facebook. Online forums, review sites, and online communities such as Discourse or Reddit also contain valuable data about your customers, or research questions.
If you are considering performing a qualitative benchmark analysis against competitors - the internet is your best friend, and review analysis is a great place to start. Gathering feedback in competitor reviews on sites like Trustpilot, G2, Capterra, Better Business Bureau or on app stores is a great way to perform a competitor benchmark analysis.
Customer feedback analysis software often has integrations into social media and review sites, or you could use a solution like DataMiner to scrape the reviews.

Step 2: Connect & organize all your qualitative data
Now you all have this qualitative data but there’s a problem, the data is unstructured. Before feedback can be analyzed and assigned any value, it needs to be organized in a single place. Why is this important? Consistency!
If all data is easily accessible in one place and analyzed in a consistent manner, you will have an easier time summarizing and making decisions based on this data.
The manual approach to organizing your data
The classic method of structuring qualitative data is to plot all the raw data you’ve gathered into a spreadsheet.
Typically, research and support teams would share large Excel sheets and different business units would make sense of the qualitative feedback data on their own. Each team collects and organizes the data in a way that best suits them, which means the feedback tends to be kept in separate silos.
An alternative and a more robust solution is to store feedback in a central database, like Snowflake or Amazon Redshift .
Keep in mind that when you organize your data in this way, you are often preparing it to be imported into another software. If you go the route of a database, you would need to use an API to push the feedback into a third-party software.
Computer-assisted qualitative data analysis software (CAQDAS)
Traditionally within the manual analysis approach (but not always), qualitative data is imported into CAQDAS software for coding.
In the early 2000s, CAQDAS software was popularised by developers such as ATLAS.ti, NVivo and MAXQDA and eagerly adopted by researchers to assist with the organizing and coding of data.
The benefits of using computer-assisted qualitative data analysis software:
- Assists in the organizing of your data
- Opens you up to exploring different interpretations of your data analysis
- Allows you to share your dataset easier and allows group collaboration (allows for secondary analysis)
However you still need to code the data, uncover the themes and do the analysis yourself. Therefore it is still a manual approach.

Organizing your qualitative data in a feedback repository
Another solution to organizing your qualitative data is to upload it into a feedback repository where it can be unified with your other data , and easily searchable and taggable. There are a number of software solutions that act as a central repository for your qualitative research data. Here are a couple solutions that you could investigate:
- Dovetail: Dovetail is a research repository with a focus on video and audio transcriptions. You can tag your transcriptions within the platform for theme analysis. You can also upload your other qualitative data such as research reports, survey responses, support conversations, and customer interviews. Dovetail acts as a single, searchable repository. And makes it easier to collaborate with other people around your qualitative research.
- EnjoyHQ: EnjoyHQ is another research repository with similar functionality to Dovetail. It boasts a more sophisticated search engine, but it has a higher starting subscription cost.
Organizing your qualitative data in a feedback analytics platform
If you have a lot of qualitative customer or employee feedback, from the likes of customer surveys or employee surveys, you will benefit from a feedback analytics platform. A feedback analytics platform is a software that automates the process of both sentiment analysis and thematic analysis . Companies use the integrations offered by these platforms to directly tap into their qualitative data sources (review sites, social media, survey responses, etc.). The data collected is then organized and analyzed consistently within the platform.
If you have data prepared in a spreadsheet, it can also be imported into feedback analytics platforms.
Once all this rich data has been organized within the feedback analytics platform, it is ready to be coded and themed, within the same platform. Thematic is a feedback analytics platform that offers one of the largest libraries of integrations with qualitative data sources.

Step 3: Coding your qualitative data
Your feedback data is now organized in one place. Either within your spreadsheet, CAQDAS, feedback repository or within your feedback analytics platform. The next step is to code your feedback data so we can extract meaningful insights in the next step.
Coding is the process of labelling and organizing your data in such a way that you can then identify themes in the data, and the relationships between these themes.
To simplify the coding process, you will take small samples of your customer feedback data, come up with a set of codes, or categories capturing themes, and label each piece of feedback, systematically, for patterns and meaning. Then you will take a larger sample of data, revising and refining the codes for greater accuracy and consistency as you go.
If you choose to use a feedback analytics platform, much of this process will be automated and accomplished for you.
The terms to describe different categories of meaning (‘theme’, ‘code’, ‘tag’, ‘category’ etc) can be confusing as they are often used interchangeably. For clarity, this article will use the term ‘code’.
To code means to identify key words or phrases and assign them to a category of meaning. “I really hate the customer service of this computer software company” would be coded as “poor customer service”.
How to manually code your qualitative data
- Decide whether you will use deductive or inductive coding. Deductive coding is when you create a list of predefined codes, and then assign them to the qualitative data. Inductive coding is the opposite of this, you create codes based on the data itself. Codes arise directly from the data and you label them as you go. You need to weigh up the pros and cons of each coding method and select the most appropriate.
- Read through the feedback data to get a broad sense of what it reveals. Now it’s time to start assigning your first set of codes to statements and sections of text.
- Keep repeating step 2, adding new codes and revising the code description as often as necessary. Once it has all been coded, go through everything again, to be sure there are no inconsistencies and that nothing has been overlooked.
- Create a code frame to group your codes. The coding frame is the organizational structure of all your codes. And there are two commonly used types of coding frames, flat, or hierarchical. A hierarchical code frame will make it easier for you to derive insights from your analysis.
- Based on the number of times a particular code occurs, you can now see the common themes in your feedback data. This is insightful! If ‘bad customer service’ is a common code, it’s time to take action.
We have a detailed guide dedicated to manually coding your qualitative data .

Using software to speed up manual coding of qualitative data
An Excel spreadsheet is still a popular method for coding. But various software solutions can help speed up this process. Here are some examples.
- CAQDAS / NVivo - CAQDAS software has built-in functionality that allows you to code text within their software. You may find the interface the software offers easier for managing codes than a spreadsheet.
- Dovetail/EnjoyHQ - You can tag transcripts and other textual data within these solutions. As they are also repositories you may find it simpler to keep the coding in one platform.
- IBM SPSS - SPSS is a statistical analysis software that may make coding easier than in a spreadsheet.
- Ascribe - Ascribe’s ‘Coder’ is a coding management system. Its user interface will make it easier for you to manage your codes.
Automating the qualitative coding process using thematic analysis software
In solutions which speed up the manual coding process, you still have to come up with valid codes and often apply codes manually to pieces of feedback. But there are also solutions that automate both the discovery and the application of codes.
Advances in machine learning have now made it possible to read, code and structure qualitative data automatically. This type of automated coding is offered by thematic analysis software .
Automation makes it far simpler and faster to code the feedback and group it into themes. By incorporating natural language processing (NLP) into the software, the AI looks across sentences and phrases to identify common themes meaningful statements. Some automated solutions detect repeating patterns and assign codes to them, others make you train the AI by providing examples. You could say that the AI learns the meaning of the feedback on its own.
Thematic automates the coding of qualitative feedback regardless of source. There’s no need to set up themes or categories in advance. Simply upload your data and wait a few minutes. You can also manually edit the codes to further refine their accuracy. Experiments conducted indicate that Thematic’s automated coding is just as accurate as manual coding .
Paired with sentiment analysis and advanced text analytics - these automated solutions become powerful for deriving quality business or research insights.
You could also build your own , if you have the resources!
The key benefits of using an automated coding solution
Automated analysis can often be set up fast and there’s the potential to uncover things that would never have been revealed if you had given the software a prescribed list of themes to look for.
Because the model applies a consistent rule to the data, it captures phrases or statements that a human eye might have missed.
Complete and consistent analysis of customer feedback enables more meaningful findings. Leading us into step 4.
Step 4: Analyze your data: Find meaningful insights
Now we are going to analyze our data to find insights. This is where we start to answer our research questions. Keep in mind that step 4 and step 5 (tell the story) have some overlap . This is because creating visualizations is both part of analysis process and reporting.
The task of uncovering insights is to scour through the codes that emerge from the data and draw meaningful correlations from them. It is also about making sure each insight is distinct and has enough data to support it.
Part of the analysis is to establish how much each code relates to different demographics and customer profiles, and identify whether there’s any relationship between these data points.
Manually create sub-codes to improve the quality of insights
If your code frame only has one level, you may find that your codes are too broad to be able to extract meaningful insights. This is where it is valuable to create sub-codes to your primary codes. This process is sometimes referred to as meta coding.
Note: If you take an inductive coding approach, you can create sub-codes as you are reading through your feedback data and coding it.
While time-consuming, this exercise will improve the quality of your analysis. Here is an example of what sub-codes could look like.

You need to carefully read your qualitative data to create quality sub-codes. But as you can see, the depth of analysis is greatly improved. By calculating the frequency of these sub-codes you can get insight into which customer service problems you can immediately address.
Correlate the frequency of codes to customer segments
Many businesses use customer segmentation . And you may have your own respondent segments that you can apply to your qualitative analysis. Segmentation is the practise of dividing customers or research respondents into subgroups.
Segments can be based on:
- Demographic
- And any other data type that you care to segment by
It is particularly useful to see the occurrence of codes within your segments. If one of your customer segments is considered unimportant to your business, but they are the cause of nearly all customer service complaints, it may be in your best interest to focus attention elsewhere. This is a useful insight!
Manually visualizing coded qualitative data
There are formulas you can use to visualize key insights in your data. The formulas we will suggest are imperative if you are measuring a score alongside your feedback.
If you are collecting a metric alongside your qualitative data this is a key visualization. Impact answers the question: “What’s the impact of a code on my overall score?”. Using Net Promoter Score (NPS) as an example, first you need to:
- Calculate overall NPS
- Calculate NPS in the subset of responses that do not contain that theme
- Subtract B from A
Then you can use this simple formula to calculate code impact on NPS .

You can then visualize this data using a bar chart.
You can download our CX toolkit - it includes a template to recreate this.
Trends over time
This analysis can help you answer questions like: “Which codes are linked to decreases or increases in my score over time?”
We need to compare two sequences of numbers: NPS over time and code frequency over time . Using Excel, calculate the correlation between the two sequences, which can be either positive (the more codes the higher the NPS, see picture below), or negative (the more codes the lower the NPS).
Now you need to plot code frequency against the absolute value of code correlation with NPS. Here is the formula:

The visualization could look like this:

These are two examples, but there are more. For a third manual formula, and to learn why word clouds are not an insightful form of analysis, read our visualizations article .
Using a text analytics solution to automate analysis
Automated text analytics solutions enable codes and sub-codes to be pulled out of the data automatically. This makes it far faster and easier to identify what’s driving negative or positive results. And to pick up emerging trends and find all manner of rich insights in the data.
Another benefit of AI-driven text analytics software is its built-in capability for sentiment analysis, which provides the emotive context behind your feedback and other qualitative textual data therein.
Thematic provides text analytics that goes further by allowing users to apply their expertise on business context to edit or augment the AI-generated outputs.
Since the move away from manual research is generally about reducing the human element, adding human input to the technology might sound counter-intuitive. However, this is mostly to make sure important business nuances in the feedback aren’t missed during coding. The result is a higher accuracy of analysis. This is sometimes referred to as augmented intelligence .

Step 5: Report on your data: Tell the story
The last step of analyzing your qualitative data is to report on it, to tell the story. At this point, the codes are fully developed and the focus is on communicating the narrative to the audience.
A coherent outline of the qualitative research, the findings and the insights is vital for stakeholders to discuss and debate before they can devise a meaningful course of action.
Creating graphs and reporting in Powerpoint
Typically, qualitative researchers take the tried and tested approach of distilling their report into a series of charts, tables and other visuals which are woven into a narrative for presentation in Powerpoint.
Using visualization software for reporting
With data transformation and APIs, the analyzed data can be shared with data visualisation software, such as Power BI or Tableau , Google Studio or Looker. Power BI and Tableau are among the most preferred options.
Visualizing your insights inside a feedback analytics platform
Feedback analytics platforms, like Thematic, incorporate visualisation tools that intuitively turn key data and insights into graphs. This removes the time consuming work of constructing charts to visually identify patterns and creates more time to focus on building a compelling narrative that highlights the insights, in bite-size chunks, for executive teams to review.
Using a feedback analytics platform with visualization tools means you don’t have to use a separate product for visualizations. You can export graphs into Powerpoints straight from the platforms.

Conclusion - Manual or Automated?
There are those who remain deeply invested in the manual approach - because it’s familiar, because they’re reluctant to spend money and time learning new software, or because they’ve been burned by the overpromises of AI.
For projects that involve small datasets, manual analysis makes sense. For example, if the objective is simply to quantify a simple question like “Do customers prefer X concepts to Y?”. If the findings are being extracted from a small set of focus groups and interviews, sometimes it’s easier to just read them
However, as new generations come into the workplace, it’s technology-driven solutions that feel more comfortable and practical. And the merits are undeniable. Especially if the objective is to go deeper and understand the ‘why’ behind customers’ preference for X or Y. And even more especially if time and money are considerations.
The ability to collect a free flow of qualitative feedback data at the same time as the metric means AI can cost-effectively scan, crunch, score and analyze a ton of feedback from one system in one go. And time-intensive processes like focus groups, or coding, that used to take weeks, can now be completed in a matter of hours or days.
But aside from the ever-present business case to speed things up and keep costs down, there are also powerful research imperatives for automated analysis of qualitative data: namely, accuracy and consistency.
Finding insights hidden in feedback requires consistency, especially in coding. Not to mention catching all the ‘unknown unknowns’ that can skew research findings and steering clear of cognitive bias.
Some say without manual data analysis researchers won’t get an accurate “feel” for the insights. However, the larger data sets are, the harder it is to sort through the feedback and organize feedback that has been pulled from different places. And, the more difficult it is to stay on course, the greater the risk of drawing incorrect, or incomplete, conclusions grows.
Though the process steps for qualitative data analysis have remained pretty much unchanged since psychologist Paul Felix Lazarsfeld paved the path a hundred years ago, the impact digital technology has had on types of qualitative feedback data and the approach to the analysis are profound.
If you want to try an automated feedback analysis solution on your own qualitative data, you can get started with Thematic .

Community & Marketing
Tyler manages our community of CX, insights & analytics professionals. Tyler's goal is to help unite insights professionals around common challenges.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
When two major storms wreaked havoc on Auckland and Watercare’s infrastructurem the utility went through a CX crisis. With a massive influx of calls to their support center, Thematic helped them get inisghts from this data to forge a new approach to restore services and satisfaction levels.
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Qualtrics is one of the most well-known and powerful Customer Feedback Management platforms. But even so, it has limitations. We recently hosted a live panel where data analysts from two well-known brands shared their experiences with Qualtrics, and how they extended this platform’s capabilities. Below, we’ll share the
- PRO Courses Guides New Tech Help Pro Expert Videos About wikiHow Pro Upgrade Sign In
- EDIT Edit this Article
- EXPLORE Tech Help Pro About Us Random Article Quizzes Request a New Article Community Dashboard This Or That Game Popular Categories Arts and Entertainment Artwork Books Movies Computers and Electronics Computers Phone Skills Technology Hacks Health Men's Health Mental Health Women's Health Relationships Dating Love Relationship Issues Hobbies and Crafts Crafts Drawing Games Education & Communication Communication Skills Personal Development Studying Personal Care and Style Fashion Hair Care Personal Hygiene Youth Personal Care School Stuff Dating All Categories Arts and Entertainment Finance and Business Home and Garden Relationship Quizzes Cars & Other Vehicles Food and Entertaining Personal Care and Style Sports and Fitness Computers and Electronics Health Pets and Animals Travel Education & Communication Hobbies and Crafts Philosophy and Religion Work World Family Life Holidays and Traditions Relationships Youth
- Browse Articles
- Learn Something New
- Quizzes Hot
- This Or That Game
- Train Your Brain
- Explore More
- Support wikiHow
- About wikiHow
- Log in / Sign up
- Education and Communications
How to Analyse a Case Study
Last Updated: April 13, 2024 Fact Checked
This article was co-authored by Sarah Evans . Sarah Evans is a Public Relations & Social Media Expert based in Las Vegas, Nevada. With over 14 years of industry experience, Sarah is the Founder & CEO of Sevans PR. Her team offers strategic communications services to help clients across industries including tech, finance, medical, real estate, law, and startups. The agency is renowned for its development of the "reputation+" methodology, a data-driven and AI-powered approach designed to elevate brand credibility, trust, awareness, and authority in a competitive marketplace. Sarah’s thought leadership has led to regular appearances on The Doctors TV show, CBS Las Vegas Now, and as an Adobe influencer. She is a respected contributor at Entrepreneur magazine, Hackernoon, Grit Daily, and KLAS Las Vegas. Sarah has been featured in PR Daily and PR Newswire and is a member of the Forbes Agency Council. She received her B.A. in Communications and Public Relations from Millikin University. This article has been fact-checked, ensuring the accuracy of any cited facts and confirming the authority of its sources. This article has been viewed 411,743 times.
Case studies are used in many professional education programs, primarily in business school, to present real-world situations to students and to assess their ability to parse out the important aspects of a given dilemma. In general, a case study should include, in order: background on the business environment, description of the given business, identification of a key problem or issue, steps taken to address the issue, your assessment of that response, and suggestions for better business strategy. The steps below will guide you through the process of analyzing a business case study in this way.

- Describe the nature of the organization under consideration and its competitors. Provide general information about the market and customer base. Indicate any significant changes in the business environment or any new endeavors upon which the business is embarking.

- Analyze its management structure, employee base, and financial history. Describe annual revenues and profit. Provide figures on employment. Include details about private ownership, public ownership, and investment holdings. Provide a brief overview of the business's leaders and command chain.

- In all likelihood, there will be several different factors at play. Decide which is the main concern of the case study by examining what most of the data talks about, the main problems facing the business, and the conclusions at the end of the study. Examples might include expansion into a new market, response to a competitor's marketing campaign, or a changing customer base. [3] X Research source

- Draw on the information you gathered and trace a chronological progression of steps taken (or not taken). Cite data included in the case study, such as increased marketing spending, purchasing of new property, changed revenue streams, etc.

- Indicate whether or not each aspect of the response met its goal and whether the response overall was well-crafted. Use numerical benchmarks, like a desired customer share, to show whether goals were met; analyze broader issues, like employee management policies, to talk about the response as a whole. [4] X Research source

- Suggest alternative or improved measures that could have been taken by the business, using specific examples and backing up your suggestions with data and calculations.

Community Q&A
- Always read a case study several times. At first, you should read just for the basic details. On each subsequent reading, look for details about a specific topic: competitors, business strategy, management structure, financial loss. Highlight phrases and sections relating to these topics and take notes. Thanks Helpful 0 Not Helpful 0
- In the preliminary stages of analyzing a case study, no detail is insignificant. The biggest numbers can often be misleading, and the point of an analysis is often to dig deeper and find otherwise unnoticed variables that drive a situation. Thanks Helpful 0 Not Helpful 0
- If you are analyzing a case study for a consulting company interview, be sure to direct your comments towards the matters handled by the company. For example, if the company deals with marketing strategy, focus on the business's successes and failures in marketing; if you are interviewing for a financial consulting job, analyze how well the business keeps their books and their investment strategy. Thanks Helpful 0 Not Helpful 0

- Do not use impassioned or emphatic language in your analysis. Business case studies are a tool for gauging your business acumen, not your personal beliefs. When assigning blame or identifying flaws in strategy, use a detached, disinterested tone. Thanks Helpful 16 Not Helpful 4
Things You'll Need
You might also like.

Expert Interview

Thanks for reading our article! If you’d like to learn more about business writing, check out our in-depth interview with Sarah Evans .
- ↑ https://www.gvsu.edu/cms4/asset/CC3BFEEB-C364-E1A1-A5390F221AC0FD2D/business_case_analysis_gg_final.pdf
- ↑ https://bizfluent.com/12741914/how-to-analyze-a-business-case-study
- ↑ http://www.business-fundas.com/2009/how-to-analyze-business-case-studies/
- ↑ https://writingcenter.uagc.edu/writing-case-study-analysis
- http://college.cengage.com/business/resources/casestudies/students/analyzing.htm
About This Article

- Send fan mail to authors
Reader Success Stories
Lisa Upshur
Jun 15, 2019
Did this article help you?

Tejiri Aren
Jul 21, 2016
Jul 15, 2017
Jenn M.T. Tseka
Jul 3, 2016
Devanand Sbuurayan
Dec 6, 2020

Featured Articles

Trending Articles

Watch Articles

- Terms of Use
- Privacy Policy
- Do Not Sell or Share My Info
- Not Selling Info
Don’t miss out! Sign up for
wikiHow’s newsletter
A Guide To The Methods, Benefits & Problems of The Interpretation of Data

Table of Contents
1) What Is Data Interpretation?
2) How To Interpret Data?
3) Why Data Interpretation Is Important?
4) Data Interpretation Skills
5) Data Analysis & Interpretation Problems
6) Data Interpretation Techniques & Methods
7) The Use of Dashboards For Data Interpretation
8) Business Data Interpretation Examples
Data analysis and interpretation have now taken center stage with the advent of the digital age… and the sheer amount of data can be frightening. In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 trillion gigabytes! Based on that amount of data alone, it is clear the calling card of any successful enterprise in today’s global world will be the ability to analyze complex data, produce actionable insights, and adapt to new market needs… all at the speed of thought.
Business dashboards are the digital age tools for big data. Capable of displaying key performance indicators (KPIs) for both quantitative and qualitative data analyses, they are ideal for making the fast-paced and data-driven market decisions that push today’s industry leaders to sustainable success. Through the art of streamlined visual communication, data dashboards permit businesses to engage in real-time and informed decision-making and are key instruments in data interpretation. First of all, let’s find a definition to understand what lies behind this practice.
What Is Data Interpretation?
Data interpretation refers to the process of using diverse analytical methods to review data and arrive at relevant conclusions. The interpretation of data helps researchers to categorize, manipulate, and summarize the information in order to answer critical questions.
The importance of data interpretation is evident, and this is why it needs to be done properly. Data is very likely to arrive from multiple sources and has a tendency to enter the analysis process with haphazard ordering. Data analysis tends to be extremely subjective. That is to say, the nature and goal of interpretation will vary from business to business, likely correlating to the type of data being analyzed. While there are several types of processes that are implemented based on the nature of individual data, the two broadest and most common categories are “quantitative and qualitative analysis.”
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding measurement scales. Before any serious data analysis can begin, the measurement scale must be decided for the data as this will have a long-term impact on data interpretation ROI. The varying scales include:
- Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively. Variables are exclusive and exhaustive.
- Ordinal Scale: exclusive categories that are exclusive and exhaustive but with a logical order. Quality ratings and agreement ratings are examples of ordinal scales (i.e., good, very good, fair, etc., OR agree, strongly agree, disagree, etc.).
- Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories. There is always an arbitrary zero point.
- Ratio: contains features of all three.
For a more in-depth review of scales of measurement, read our article on data analysis questions . Once measurement scales have been selected, it is time to select which of the two broad interpretation processes will best suit your data needs. Let’s take a closer look at those specific methods and possible data interpretation problems.
How To Interpret Data? Top Methods & Techniques

When interpreting data, an analyst must try to discern the differences between correlation, causation, and coincidences, as well as many other biases – but he also has to consider all the factors involved that may have led to a result. There are various data interpretation types and methods one can use to achieve this.
The interpretation of data is designed to help people make sense of numerical data that has been collected, analyzed, and presented. Having a baseline method for interpreting data will provide your analyst teams with a structure and consistent foundation. Indeed, if several departments have different approaches to interpreting the same data while sharing the same goals, some mismatched objectives can result. Disparate methods will lead to duplicated efforts, inconsistent solutions, wasted energy, and inevitably – time and money. In this part, we will look at the two main methods of interpretation of data: qualitative and quantitative analysis.
Qualitative Data Interpretation
Qualitative data analysis can be summed up in one word – categorical. With this type of analysis, data is not described through numerical values or patterns but through the use of descriptive context (i.e., text). Typically, narrative data is gathered by employing a wide variety of person-to-person techniques. These techniques include:
- Observations: detailing behavioral patterns that occur within an observation group. These patterns could be the amount of time spent in an activity, the type of activity, and the method of communication employed.
- Focus groups: Group people and ask them relevant questions to generate a collaborative discussion about a research topic.
- Secondary Research: much like how patterns of behavior can be observed, various types of documentation resources can be coded and divided based on the type of material they contain.
- Interviews: one of the best collection methods for narrative data. Inquiry responses can be grouped by theme, topic, or category. The interview approach allows for highly focused data segmentation.
A key difference between qualitative and quantitative analysis is clearly noticeable in the interpretation stage. The first one is widely open to interpretation and must be “coded” so as to facilitate the grouping and labeling of data into identifiable themes. As person-to-person data collection techniques can often result in disputes pertaining to proper analysis, qualitative data analysis is often summarized through three basic principles: notice things, collect things, and think about things.
After qualitative data has been collected through transcripts, questionnaires, audio and video recordings, or the researcher’s notes, it is time to interpret it. For that purpose, there are some common methods used by researchers and analysts.
- Content analysis : As its name suggests, this is a research method used to identify frequencies and recurring words, subjects, and concepts in image, video, or audio content. It transforms qualitative information into quantitative data to help discover trends and conclusions that will later support important research or business decisions. This method is often used by marketers to understand brand sentiment from the mouths of customers themselves. Through that, they can extract valuable information to improve their products and services. It is recommended to use content analytics tools for this method as manually performing it is very time-consuming and can lead to human error or subjectivity issues. Having a clear goal in mind before diving into it is another great practice for avoiding getting lost in the fog.
- Thematic analysis: This method focuses on analyzing qualitative data, such as interview transcripts, survey questions, and others, to identify common patterns and separate the data into different groups according to found similarities or themes. For example, imagine you want to analyze what customers think about your restaurant. For this purpose, you do a thematic analysis on 1000 reviews and find common themes such as “fresh food”, “cold food”, “small portions”, “friendly staff”, etc. With those recurring themes in hand, you can extract conclusions about what could be improved or enhanced based on your customer’s experiences. Since this technique is more exploratory, be open to changing your research questions or goals as you go.
- Narrative analysis: A bit more specific and complicated than the two previous methods, it is used to analyze stories and discover their meaning. These stories can be extracted from testimonials, case studies, and interviews, as these formats give people more space to tell their experiences. Given that collecting this kind of data is harder and more time-consuming, sample sizes for narrative analysis are usually smaller, which makes it harder to reproduce its findings. However, it is still a valuable technique for understanding customers' preferences and mindsets.
- Discourse analysis : This method is used to draw the meaning of any type of visual, written, or symbolic language in relation to a social, political, cultural, or historical context. It is used to understand how context can affect how language is carried out and understood. For example, if you are doing research on power dynamics, using discourse analysis to analyze a conversation between a janitor and a CEO and draw conclusions about their responses based on the context and your research questions is a great use case for this technique. That said, like all methods in this section, discourse analytics is time-consuming as the data needs to be analyzed until no new insights emerge.
- Grounded theory analysis : The grounded theory approach aims to create or discover a new theory by carefully testing and evaluating the data available. Unlike all other qualitative approaches on this list, grounded theory helps extract conclusions and hypotheses from the data instead of going into the analysis with a defined hypothesis. This method is very popular amongst researchers, analysts, and marketers as the results are completely data-backed, providing a factual explanation of any scenario. It is often used when researching a completely new topic or with little knowledge as this space to start from the ground up.
Quantitative Data Interpretation
If quantitative data interpretation could be summed up in one word (and it really can’t), that word would be “numerical.” There are few certainties when it comes to data analysis, but you can be sure that if the research you are engaging in has no numbers involved, it is not quantitative research, as this analysis refers to a set of processes by which numerical data is analyzed. More often than not, it involves the use of statistical modeling such as standard deviation, mean, and median. Let’s quickly review the most common statistical terms:
- Mean: A mean represents a numerical average for a set of responses. When dealing with a data set (or multiple data sets), a mean will represent the central value of a specific set of numbers. It is the sum of the values divided by the number of values within the data set. Other terms that can be used to describe the concept are arithmetic mean, average, and mathematical expectation.
- Standard deviation: This is another statistical term commonly used in quantitative analysis. Standard deviation reveals the distribution of the responses around the mean. It describes the degree of consistency within the responses; together with the mean, it provides insight into data sets.
- Frequency distribution: This is a measurement gauging the rate of a response appearance within a data set. When using a survey, for example, frequency distribution, it can determine the number of times a specific ordinal scale response appears (i.e., agree, strongly agree, disagree, etc.). Frequency distribution is extremely keen in determining the degree of consensus among data points.
Typically, quantitative data is measured by visually presenting correlation tests between two or more variables of significance. Different processes can be used together or separately, and comparisons can be made to ultimately arrive at a conclusion. Other signature interpretation processes of quantitative data include:
- Regression analysis: Essentially, it uses historical data to understand the relationship between a dependent variable and one or more independent variables. Knowing which variables are related and how they developed in the past allows you to anticipate possible outcomes and make better decisions going forward. For example, if you want to predict your sales for next month, you can use regression to understand what factors will affect them, such as products on sale and the launch of a new campaign, among many others.
- Cohort analysis: This method identifies groups of users who share common characteristics during a particular time period. In a business scenario, cohort analysis is commonly used to understand customer behaviors. For example, a cohort could be all users who have signed up for a free trial on a given day. An analysis would be carried out to see how these users behave, what actions they carry out, and how their behavior differs from other user groups.
- Predictive analysis: As its name suggests, the predictive method aims to predict future developments by analyzing historical and current data. Powered by technologies such as artificial intelligence and machine learning, predictive analytics practices enable businesses to identify patterns or potential issues and plan informed strategies in advance.
- Prescriptive analysis: Also powered by predictions, the prescriptive method uses techniques such as graph analysis, complex event processing, and neural networks, among others, to try to unravel the effect that future decisions will have in order to adjust them before they are actually made. This helps businesses to develop responsive, practical business strategies.
- Conjoint analysis: Typically applied to survey analysis, the conjoint approach is used to analyze how individuals value different attributes of a product or service. This helps researchers and businesses to define pricing, product features, packaging, and many other attributes. A common use is menu-based conjoint analysis, in which individuals are given a “menu” of options from which they can build their ideal concept or product. Through this, analysts can understand which attributes they would pick above others and drive conclusions.
- Cluster analysis: Last but not least, the cluster is a method used to group objects into categories. Since there is no target variable when using cluster analysis, it is a useful method to find hidden trends and patterns in the data. In a business context, clustering is used for audience segmentation to create targeted experiences. In market research, it is often used to identify age groups, geographical information, and earnings, among others.
Now that we have seen how to interpret data, let's move on and ask ourselves some questions: What are some of the benefits of data interpretation? Why do all industries engage in data research and analysis? These are basic questions, but they often don’t receive adequate attention.
Your Chance: Want to test a powerful data analysis software? Use our 14-days free trial & start extracting insights from your data!
Why Data Interpretation Is Important

The purpose of collection and interpretation is to acquire useful and usable information and to make the most informed decisions possible. From businesses to newlyweds researching their first home, data collection and interpretation provide limitless benefits for a wide range of institutions and individuals.
Data analysis and interpretation, regardless of the method and qualitative/quantitative status, may include the following characteristics:
- Data identification and explanation
- Comparing and contrasting data
- Identification of data outliers
- Future predictions
Data analysis and interpretation, in the end, help improve processes and identify problems. It is difficult to grow and make dependable improvements without, at the very least, minimal data collection and interpretation. What is the keyword? Dependable. Vague ideas regarding performance enhancement exist within all institutions and industries. Yet, without proper research and analysis, an idea is likely to remain in a stagnant state forever (i.e., minimal growth). So… what are a few of the business benefits of digital age data analysis and interpretation? Let’s take a look!
1) Informed decision-making: A decision is only as good as the knowledge that formed it. Informed data decision-making can potentially set industry leaders apart from the rest of the market pack. Studies have shown that companies in the top third of their industries are, on average, 5% more productive and 6% more profitable when implementing informed data decision-making processes. Most decisive actions will arise only after a problem has been identified or a goal defined. Data analysis should include identification, thesis development, and data collection, followed by data communication.
If institutions only follow that simple order, one that we should all be familiar with from grade school science fairs, then they will be able to solve issues as they emerge in real-time. Informed decision-making has a tendency to be cyclical. This means there is really no end, and eventually, new questions and conditions arise within the process that need to be studied further. The monitoring of data results will inevitably return the process to the start with new data and sights.
2) Anticipating needs with trends identification: data insights provide knowledge, and knowledge is power. The insights obtained from market and consumer data analyses have the ability to set trends for peers within similar market segments. A perfect example of how data analytics can impact trend prediction is evidenced in the music identification application Shazam . The application allows users to upload an audio clip of a song they like but can’t seem to identify. Users make 15 million song identifications a day. With this data, Shazam has been instrumental in predicting future popular artists.
When industry trends are identified, they can then serve a greater industry purpose. For example, the insights from Shazam’s monitoring benefits not only Shazam in understanding how to meet consumer needs but also grant music executives and record label companies an insight into the pop-culture scene of the day. Data gathering and interpretation processes can allow for industry-wide climate prediction and result in greater revenue streams across the market. For this reason, all institutions should follow the basic data cycle of collection, interpretation, decision-making, and monitoring.
3) Cost efficiency: Proper implementation of analytics processes can provide businesses with profound cost advantages within their industries. A recent data study performed by Deloitte vividly demonstrates this in finding that data analysis ROI is driven by efficient cost reductions. Often, this benefit is overlooked because making money is typically viewed as “sexier” than saving money. Yet, sound data analyses have the ability to alert management to cost-reduction opportunities without any significant exertion of effort on the part of human capital.
A great example of the potential for cost efficiency through data analysis is Intel. Prior to 2012, Intel would conduct over 19,000 manufacturing function tests on their chips before they could be deemed acceptable for release. To cut costs and reduce test time, Intel implemented predictive data analyses. By using historical and current data, Intel now avoids testing each chip 19,000 times by focusing on specific and individual chip tests. After its implementation in 2012, Intel saved over $3 million in manufacturing costs. Cost reduction may not be as “sexy” as data profit, but as Intel proves, it is a benefit of data analysis that should not be neglected.
4) Clear foresight: companies that collect and analyze their data gain better knowledge about themselves, their processes, and their performance. They can identify performance challenges when they arise and take action to overcome them. Data interpretation through visual representations lets them process their findings faster and make better-informed decisions on the company's future.
Key Data Interpretation Skills You Should Have
Just like any other process, data interpretation and analysis require researchers or analysts to have some key skills to be able to perform successfully. It is not enough just to apply some methods and tools to the data; the person who is managing it needs to be objective and have a data-driven mind, among other skills.
It is a common misconception to think that the required skills are mostly number-related. While data interpretation is heavily analytically driven, it also requires communication and narrative skills, as the results of the analysis need to be presented in a way that is easy to understand for all types of audiences.
Luckily, with the rise of self-service tools and AI-driven technologies, data interpretation is no longer segregated for analysts only. However, the topic still remains a big challenge for businesses that make big investments in data and tools to support it, as the interpretation skills required are still lacking. It is worthless to put massive amounts of money into extracting information if you are not going to be able to interpret what that information is telling you. For that reason, below we list the top 5 data interpretation skills your employees or researchers should have to extract the maximum potential from the data.
- Data Literacy: The first and most important skill to have is data literacy. This means having the ability to understand, work, and communicate with data. It involves knowing the types of data sources, methods, and ethical implications of using them. In research, this skill is often a given. However, in a business context, there might be many employees who are not comfortable with data. The issue is the interpretation of data can not be solely responsible for the data team, as it is not sustainable in the long run. Experts advise business leaders to carefully assess the literacy level across their workforce and implement training instances to ensure everyone can interpret their data.
- Data Tools: The data interpretation and analysis process involves using various tools to collect, clean, store, and analyze the data. The complexity of the tools varies depending on the type of data and the analysis goals. Going from simple ones like Excel to more complex ones like databases, such as SQL, or programming languages, such as R or Python. It also involves visual analytics tools to bring the data to life through the use of graphs and charts. Managing these tools is a fundamental skill as they make the process faster and more efficient. As mentioned before, most modern solutions are now self-service, enabling less technical users to use them without problem.
- Critical Thinking: Another very important skill is to have critical thinking. Data hides a range of conclusions, trends, and patterns that must be discovered. It is not just about comparing numbers; it is about putting a story together based on multiple factors that will lead to a conclusion. Therefore, having the ability to look further from what is right in front of you is an invaluable skill for data interpretation.
- Data Ethics: In the information age, being aware of the legal and ethical responsibilities that come with the use of data is of utmost importance. In short, data ethics involves respecting the privacy and confidentiality of data subjects, as well as ensuring accuracy and transparency for data usage. It requires the analyzer or researcher to be completely objective with its interpretation to avoid any biases or discrimination. Many countries have already implemented regulations regarding the use of data, including the GDPR or the ACM Code Of Ethics. Awareness of these regulations and responsibilities is a fundamental skill that anyone working in data interpretation should have.
- Domain Knowledge: Another skill that is considered important when interpreting data is to have domain knowledge. As mentioned before, data hides valuable insights that need to be uncovered. To do so, the analyst needs to know about the industry or domain from which the information is coming and use that knowledge to explore it and put it into a broader context. This is especially valuable in a business context, where most departments are now analyzing data independently with the help of a live dashboard instead of relying on the IT department, which can often overlook some aspects due to a lack of expertise in the topic.
Common Data Analysis And Interpretation Problems

The oft-repeated mantra of those who fear data advancements in the digital age is “big data equals big trouble.” While that statement is not accurate, it is safe to say that certain data interpretation problems or “pitfalls” exist and can occur when analyzing data, especially at the speed of thought. Let’s identify some of the most common data misinterpretation risks and shed some light on how they can be avoided:
1) Correlation mistaken for causation: our first misinterpretation of data refers to the tendency of data analysts to mix the cause of a phenomenon with correlation. It is the assumption that because two actions occurred together, one caused the other. This is inaccurate, as actions can occur together, absent a cause-and-effect relationship.
- Digital age example: assuming that increased revenue results from increased social media followers… there might be a definitive correlation between the two, especially with today’s multi-channel purchasing experiences. But that does not mean an increase in followers is the direct cause of increased revenue. There could be both a common cause and an indirect causality.
- Remedy: attempt to eliminate the variable you believe to be causing the phenomenon.
2) Confirmation bias: our second problem is data interpretation bias. It occurs when you have a theory or hypothesis in mind but are intent on only discovering data patterns that support it while rejecting those that do not.
- Digital age example: your boss asks you to analyze the success of a recent multi-platform social media marketing campaign. While analyzing the potential data variables from the campaign (one that you ran and believe performed well), you see that the share rate for Facebook posts was great, while the share rate for Twitter Tweets was not. Using only Facebook posts to prove your hypothesis that the campaign was successful would be a perfect manifestation of confirmation bias.
- Remedy: as this pitfall is often based on subjective desires, one remedy would be to analyze data with a team of objective individuals. If this is not possible, another solution is to resist the urge to make a conclusion before data exploration has been completed. Remember to always try to disprove a hypothesis, not prove it.
3) Irrelevant data: the third data misinterpretation pitfall is especially important in the digital age. As large data is no longer centrally stored and as it continues to be analyzed at the speed of thought, it is inevitable that analysts will focus on data that is irrelevant to the problem they are trying to correct.
- Digital age example: in attempting to gauge the success of an email lead generation campaign, you notice that the number of homepage views directly resulting from the campaign increased, but the number of monthly newsletter subscribers did not. Based on the number of homepage views, you decide the campaign was a success when really it generated zero leads.
- Remedy: proactively and clearly frame any data analysis variables and KPIs prior to engaging in a data review. If the metric you use to measure the success of a lead generation campaign is newsletter subscribers, there is no need to review the number of homepage visits. Be sure to focus on the data variable that answers your question or solves your problem and not on irrelevant data.
4) Truncating an Axes: When creating a graph to start interpreting the results of your analysis, it is important to keep the axes truthful and avoid generating misleading visualizations. Starting the axes in a value that doesn’t portray the actual truth about the data can lead to false conclusions.
- Digital age example: In the image below, we can see a graph from Fox News in which the Y-axes start at 34%, making it seem that the difference between 35% and 39.6% is way higher than it actually is. This could lead to a misinterpretation of the tax rate changes.

* Source : www.venngage.com *
- Remedy: Be careful with how your data is visualized. Be respectful and realistic with axes to avoid misinterpretation of your data. See below how the Fox News chart looks when using the correct axis values. This chart was created with datapine's modern online data visualization tool.

5) (Small) sample size: Another common problem is using a small sample size. Logically, the bigger the sample size, the more accurate and reliable the results. However, this also depends on the size of the effect of the study. For example, the sample size in a survey about the quality of education will not be the same as for one about people doing outdoor sports in a specific area.
- Digital age example: Imagine you ask 30 people a question, and 29 answer “yes,” resulting in 95% of the total. Now imagine you ask the same question to 1000, and 950 of them answer “yes,” which is again 95%. While these percentages might look the same, they certainly do not mean the same thing, as a 30-person sample size is not a significant number to establish a truthful conclusion.
- Remedy: Researchers say that in order to determine the correct sample size to get truthful and meaningful results, it is necessary to define a margin of error that will represent the maximum amount they want the results to deviate from the statistical mean. Paired with this, they need to define a confidence level that should be between 90 and 99%. With these two values in hand, researchers can calculate an accurate sample size for their studies.
6) Reliability, subjectivity, and generalizability : When performing qualitative analysis, researchers must consider practical and theoretical limitations when interpreting the data. In some cases, this type of research can be considered unreliable because of uncontrolled factors that might or might not affect the results. This is paired with the fact that the researcher has a primary role in the interpretation process, meaning he or she decides what is relevant and what is not, and as we know, interpretations can be very subjective.
Generalizability is also an issue that researchers face when dealing with qualitative analysis. As mentioned in the point about having a small sample size, it is difficult to draw conclusions that are 100% representative because the results might be biased or unrepresentative of a wider population.
While these factors are mostly present in qualitative research, they can also affect the quantitative analysis. For example, when choosing which KPIs to portray and how to portray them, analysts can also be biased and represent them in a way that benefits their analysis.
- Digital age example: Biased questions in a survey are a great example of reliability and subjectivity issues. Imagine you are sending a survey to your clients to see how satisfied they are with your customer service with this question: “How amazing was your experience with our customer service team?”. Here, we can see that this question clearly influences the response of the individual by putting the word “amazing” on it.
- Remedy: A solution to avoid these issues is to keep your research honest and neutral. Keep the wording of the questions as objective as possible. For example: “On a scale of 1-10, how satisfied were you with our customer service team?”. This does not lead the respondent to any specific answer, meaning the results of your survey will be reliable.
Data Interpretation Best Practices & Tips

Data analysis and interpretation are critical to developing sound conclusions and making better-informed decisions. As we have seen with this article, there is an art and science to the interpretation of data. To help you with this purpose, we will list a few relevant techniques, methods, and tricks you can implement for a successful data management process.
As mentioned at the beginning of this post, the first step to interpreting data in a successful way is to identify the type of analysis you will perform and apply the methods respectively. Clearly differentiate between qualitative (observe, document, and interview notice, collect and think about things) and quantitative analysis (you lead research with a lot of numerical data to be analyzed through various statistical methods).
1) Ask the right data interpretation questions
The first data interpretation technique is to define a clear baseline for your work. This can be done by answering some critical questions that will serve as a useful guideline to start. Some of them include: what are the goals and objectives of my analysis? What type of data interpretation method will I use? Who will use this data in the future? And most importantly, what general question am I trying to answer?
Once all this information has been defined, you will be ready for the next step: collecting your data.
2) Collect and assimilate your data
Now that a clear baseline has been established, it is time to collect the information you will use. Always remember that your methods for data collection will vary depending on what type of analysis method you use, which can be qualitative or quantitative. Based on that, relying on professional online data analysis tools to facilitate the process is a great practice in this regard, as manually collecting and assessing raw data is not only very time-consuming and expensive but is also at risk of errors and subjectivity.
Once your data is collected, you need to carefully assess it to understand if the quality is appropriate to be used during a study. This means, is the sample size big enough? Were the procedures used to collect the data implemented correctly? Is the date range from the data correct? If coming from an external source, is it a trusted and objective one?
With all the needed information in hand, you are ready to start the interpretation process, but first, you need to visualize your data.
3) Use the right data visualization type
Data visualizations such as business graphs , charts, and tables are fundamental to successfully interpreting data. This is because data visualization via interactive charts and graphs makes the information more understandable and accessible. As you might be aware, there are different types of visualizations you can use, but not all of them are suitable for any analysis purpose. Using the wrong graph can lead to misinterpretation of your data, so it’s very important to carefully pick the right visual for it. Let’s look at some use cases of common data visualizations.
- Bar chart: One of the most used chart types, the bar chart uses rectangular bars to show the relationship between 2 or more variables. There are different types of bar charts for different interpretations, including the horizontal bar chart, column bar chart, and stacked bar chart.
- Line chart: Most commonly used to show trends, acceleration or decelerations, and volatility, the line chart aims to show how data changes over a period of time, for example, sales over a year. A few tips to keep this chart ready for interpretation are not using many variables that can overcrowd the graph and keeping your axis scale close to the highest data point to avoid making the information hard to read.
- Pie chart: Although it doesn’t do a lot in terms of analysis due to its uncomplex nature, pie charts are widely used to show the proportional composition of a variable. Visually speaking, showing a percentage in a bar chart is way more complicated than showing it in a pie chart. However, this also depends on the number of variables you are comparing. If your pie chart needs to be divided into 10 portions, then it is better to use a bar chart instead.
- Tables: While they are not a specific type of chart, tables are widely used when interpreting data. Tables are especially useful when you want to portray data in its raw format. They give you the freedom to easily look up or compare individual values while also displaying grand totals.
With the use of data visualizations becoming more and more critical for businesses’ analytical success, many tools have emerged to help users visualize their data in a cohesive and interactive way. One of the most popular ones is the use of BI dashboards . These visual tools provide a centralized view of various graphs and charts that paint a bigger picture of a topic. We will discuss the power of dashboards for an efficient data interpretation practice in the next portion of this post. If you want to learn more about different types of graphs and charts , take a look at our complete guide on the topic.
4) Start interpreting
After the tedious preparation part, you can start extracting conclusions from your data. As mentioned many times throughout the post, the way you decide to interpret the data will solely depend on the methods you initially decided to use. If you had initial research questions or hypotheses, then you should look for ways to prove their validity. If you are going into the data with no defined hypothesis, then start looking for relationships and patterns that will allow you to extract valuable conclusions from the information.
During the process of interpretation, stay curious and creative, dig into the data, and determine if there are any other critical questions that should be asked. If any new questions arise, you need to assess if you have the necessary information to answer them. Being able to identify if you need to dedicate more time and resources to the research is a very important step. No matter if you are studying customer behaviors or a new cancer treatment, the findings from your analysis may dictate important decisions in the future. Therefore, taking the time to really assess the information is key. For that purpose, data interpretation software proves to be very useful.
5) Keep your interpretation objective
As mentioned above, objectivity is one of the most important data interpretation skills but also one of the hardest. Being the person closest to the investigation, it is easy to become subjective when looking for answers in the data. A good way to stay objective is to show the information related to the study to other people, for example, research partners or even the people who will use your findings once they are done. This can help avoid confirmation bias and any reliability issues with your interpretation.
Remember, using a visualization tool such as a modern dashboard will make the interpretation process way easier and more efficient as the data can be navigated and manipulated in an easy and organized way. And not just that, using a dashboard tool to present your findings to a specific audience will make the information easier to understand and the presentation way more engaging thanks to the visual nature of these tools.
6) Mark your findings and draw conclusions
Findings are the observations you extracted from your data. They are the facts that will help you drive deeper conclusions about your research. For example, findings can be trends and patterns you found during your interpretation process. To put your findings into perspective, you can compare them with other resources that use similar methods and use them as benchmarks.
Reflect on your own thinking and reasoning and be aware of the many pitfalls data analysis and interpretation carry—correlation versus causation, subjective bias, false information, inaccurate data, etc. Once you are comfortable with interpreting the data, you will be ready to develop conclusions, see if your initial questions were answered, and suggest recommendations based on them.
Interpretation of Data: The Use of Dashboards Bridging The Gap
As we have seen, quantitative and qualitative methods are distinct types of data interpretation and analysis. Both offer a varying degree of return on investment (ROI) regarding data investigation, testing, and decision-making. But how do you mix the two and prevent a data disconnect? The answer is professional data dashboards.
For a few years now, dashboards have become invaluable tools to visualize and interpret data. These tools offer a centralized and interactive view of data and provide the perfect environment for exploration and extracting valuable conclusions. They bridge the quantitative and qualitative information gap by unifying all the data in one place with the help of stunning visuals.
Not only that, but these powerful tools offer a large list of benefits, and we will discuss some of them below.
1) Connecting and blending data. With today’s pace of innovation, it is no longer feasible (nor desirable) to have bulk data centrally located. As businesses continue to globalize and borders continue to dissolve, it will become increasingly important for businesses to possess the capability to run diverse data analyses absent the limitations of location. Data dashboards decentralize data without compromising on the necessary speed of thought while blending both quantitative and qualitative data. Whether you want to measure customer trends or organizational performance, you now have the capability to do both without the need for a singular selection.
2) Mobile Data. Related to the notion of “connected and blended data” is that of mobile data. In today’s digital world, employees are spending less time at their desks and simultaneously increasing production. This is made possible because mobile solutions for analytical tools are no longer standalone. Today, mobile analysis applications seamlessly integrate with everyday business tools. In turn, both quantitative and qualitative data are now available on-demand where they’re needed, when they’re needed, and how they’re needed via interactive online dashboards .
3) Visualization. Data dashboards merge the data gap between qualitative and quantitative data interpretation methods through the science of visualization. Dashboard solutions come “out of the box” and are well-equipped to create easy-to-understand data demonstrations. Modern online data visualization tools provide a variety of color and filter patterns, encourage user interaction, and are engineered to help enhance future trend predictability. All of these visual characteristics make for an easy transition among data methods – you only need to find the right types of data visualization to tell your data story the best way possible.
4) Collaboration. Whether in a business environment or a research project, collaboration is key in data interpretation and analysis. Dashboards are online tools that can be easily shared through a password-protected URL or automated email. Through them, users can collaborate and communicate through the data in an efficient way. Eliminating the need for infinite files with lost updates. Tools such as datapine offer real-time updates, meaning your dashboards will update on their own as soon as new information is available.
Examples Of Data Interpretation In Business
To give you an idea of how a dashboard can fulfill the need to bridge quantitative and qualitative analysis and help in understanding how to interpret data in research thanks to visualization, below, we will discuss three valuable examples to put their value into perspective.
1. Customer Satisfaction Dashboard
This market research dashboard brings together both qualitative and quantitative data that are knowledgeably analyzed and visualized in a meaningful way that everyone can understand, thus empowering any viewer to interpret it. Let’s explore it below.

**click to enlarge**
The value of this template lies in its highly visual nature. As mentioned earlier, visuals make the interpretation process way easier and more efficient. Having critical pieces of data represented with colorful and interactive icons and graphs makes it possible to uncover insights at a glance. For example, the colors green, yellow, and red on the charts for the NPS and the customer effort score allow us to conclude that most respondents are satisfied with this brand with a short glance. A further dive into the line chart below can help us dive deeper into this conclusion, as we can see both metrics developed positively in the past 6 months.
The bottom part of the template provides visually stunning representations of different satisfaction scores for quality, pricing, design, and service. By looking at these, we can conclude that, overall, customers are satisfied with this company in most areas.
2. Brand Analysis Dashboard
Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs.

When interpreting information, context is key to understanding it correctly. For that reason, the dashboard starts by offering insights into the demographics of the surveyed audience. In general, we can see ages and gender are diverse. Therefore, we can conclude these brands are not targeting customers from a specified demographic, an important aspect to put the surveyed answers into perspective.
Looking at the awareness portion, we can see that brand B is the most popular one, with brand D coming second on both questions. This means brand D is not doing wrong, but there is still room for improvement compared to brand B. To see where brand D could improve, the researcher could go into the bottom part of the dashboard and consult the answers for branding themes and celebrity analysis. These are important as they give clear insight into what people and messages the audience associates with brand D. This is an opportunity to exploit these topics in different ways and achieve growth and success.
3. Product Innovation Dashboard
Our third and last dashboard example shows the answers to a survey on product innovation for a technology company. Just like the previous templates, the interactive and visual nature of the dashboard makes it the perfect tool to interpret data efficiently and effectively.

Starting from right to left, we first get a list of the top 5 products by purchase intention. This information lets us understand if the product being evaluated resembles what the audience already intends to purchase. It is a great starting point to see how customers would respond to the new product. This information can be complemented with other key metrics displayed in the dashboard. For example, the usage and purchase intention track how the market would receive the product and if they would purchase it, respectively. Interpreting these values as positive or negative will depend on the company and its expectations regarding the survey.
Complementing these metrics, we have the willingness to pay. Arguably, one of the most important metrics to define pricing strategies. Here, we can see that most respondents think the suggested price is a good value for money. Therefore, we can interpret that the product would sell for that price.
To see more data analysis and interpretation examples for different industries and functions, visit our library of business dashboards .
To Conclude…
As we reach the end of this insightful post about data interpretation and analysis, we hope you have a clear understanding of the topic. We've covered the definition and given some examples and methods to perform a successful interpretation process.
The importance of data interpretation is undeniable. Dashboards not only bridge the information gap between traditional data interpretation methods and technology, but they can help remedy and prevent the major pitfalls of the process. As a digital age solution, they combine the best of the past and the present to allow for informed decision-making with maximum data interpretation ROI.
To start visualizing your insights in a meaningful and actionable way, test our online reporting software for free with our 14-day trial !
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research Research Tools and Apps
Data Interpretation: Definition and Steps with Examples

A good data interpretation process is key to making your data usable. It will help you make sure you’re drawing the correct conclusions and acting on your information.
No matter what, data is everywhere in the modern world. There are two groups and organizations: those drowning in data or not using it appropriately and those benefiting.
In this blog, you will learn the definition of data interpretation and its primary steps and examples.
What is Data Interpretation
Data interpretation is the process of reviewing data and arriving at relevant conclusions using various analytical research methods. Data analysis assists researchers in categorizing, manipulating data , and summarizing data to answer critical questions.
LEARN ABOUT: Level of Analysis
In business terms, the interpretation of data is the execution of various processes. This process analyzes and revises data to gain insights and recognize emerging patterns and behaviors. These conclusions will assist you as a manager in making an informed decision based on numbers while having all of the facts at your disposal.
Importance of Data Interpretation
Raw data is useless unless it’s interpreted. Data interpretation is important to businesses and people. The collected data helps make informed decisions.
Make better decisions
Any decision is based on the information that is available at the time. People used to think that many diseases were caused by bad blood, which was one of the four humors. So, the solution was to get rid of the bad blood. We now know that things like viruses, bacteria, and immune responses can cause illness and can act accordingly.
In the same way, when you know how to collect and understand data well, you can make better decisions. You can confidently choose a path for your organization or even your life instead of working with assumptions.
The most important thing is to follow a transparent process to reduce mistakes and tiredness when making decisions.
Find trends and take action
Another practical use of data interpretation is to get ahead of trends before they reach their peak. Some people have made a living by researching industries, spotting trends, and then making big bets on them.
LEARN ABOUT: Action Research
With the proper data interpretations and a little bit of work, you can catch the start of trends and use them to help your business or yourself grow.
Better resource allocation
The last importance of data interpretation we will discuss is the ability to use people, tools, money, etc., more efficiently. For example, If you know via strong data interpretation that a market is underserved, you’ll go after it with more energy and win.
In the same way, you may find out that a market you thought was a good fit is actually bad. This could be because the market is too big for your products to serve, there is too much competition, or something else.
No matter what, you can move the resources you need faster and better to get better results.
What are the steps in interpreting data?
Here are some steps to interpreting data correctly.
Gather the data
The very first step in data interpretation is gathering all relevant data. You can do this by first visualizing it in a bar, graph, or pie chart. This step aims to analyze the data accurately and without bias. Now is the time to recall how you conducted your research.
Here are two question patterns that will help you to understand better.
- Were there any flaws or changes that occurred during the data collection process?
- Have you saved any observatory notes or indicators?
You can proceed to the next stage when you have all of your data.
- Develop your discoveries
This is a summary of your findings. Here, you thoroughly examine the data to identify trends, patterns, or behavior. If you are researching a group of people using a sample population, this is the section where you examine behavioral patterns. You can compare these deductions to previous data sets, similar data sets, or general hypotheses in your industry. This step’s goal is to compare these deductions before drawing any conclusions.
- Draw Conclusions
After you’ve developed your findings from your data sets, you can draw conclusions based on your discovered trends. Your findings should address the questions that prompted your research. If they do not respond, inquire about why; it may produce additional research or questions.
LEARN ABOUT: Research Process Steps
- Give recommendations
The interpretation procedure of data comes to a close with this stage. Every research conclusion must include a recommendation. As recommendations are a summary of your findings and conclusions, they should be brief. There are only two options for recommendations; you can either recommend a course of action or suggest additional research.
Data interpretation examples
Here are two examples of data interpretations to help you understand it better:
Let’s say your users fall into four age groups. So a company can see which age group likes their content or product. Based on bar charts or pie charts, they can develop a marketing strategy to reach uninvolved groups or an outreach strategy to grow their core user base.
Another example of data analysis is the use of recruitment CRM by businesses. They utilize it to find candidates, track their progress, and manage their entire hiring process to determine how they can better automate their workflow.
Overall, data interpretation is an essential factor in data-driven decision-making. It should be performed on a regular basis as part of an iterative interpretation process. Investors, developers, and sales and acquisition professionals can benefit from routine data interpretation. It is what you do with those insights that determine the success of your business.
Contact QuestionPro experts if you need assistance conducting research or creating a data analysis. We can walk you through the process and help you make the most of your data.
MORE LIKE THIS

Cannabis Industry Business Intelligence: Impact on Research
May 28, 2024

Top 10 Dynata Alternatives & Competitors
May 27, 2024
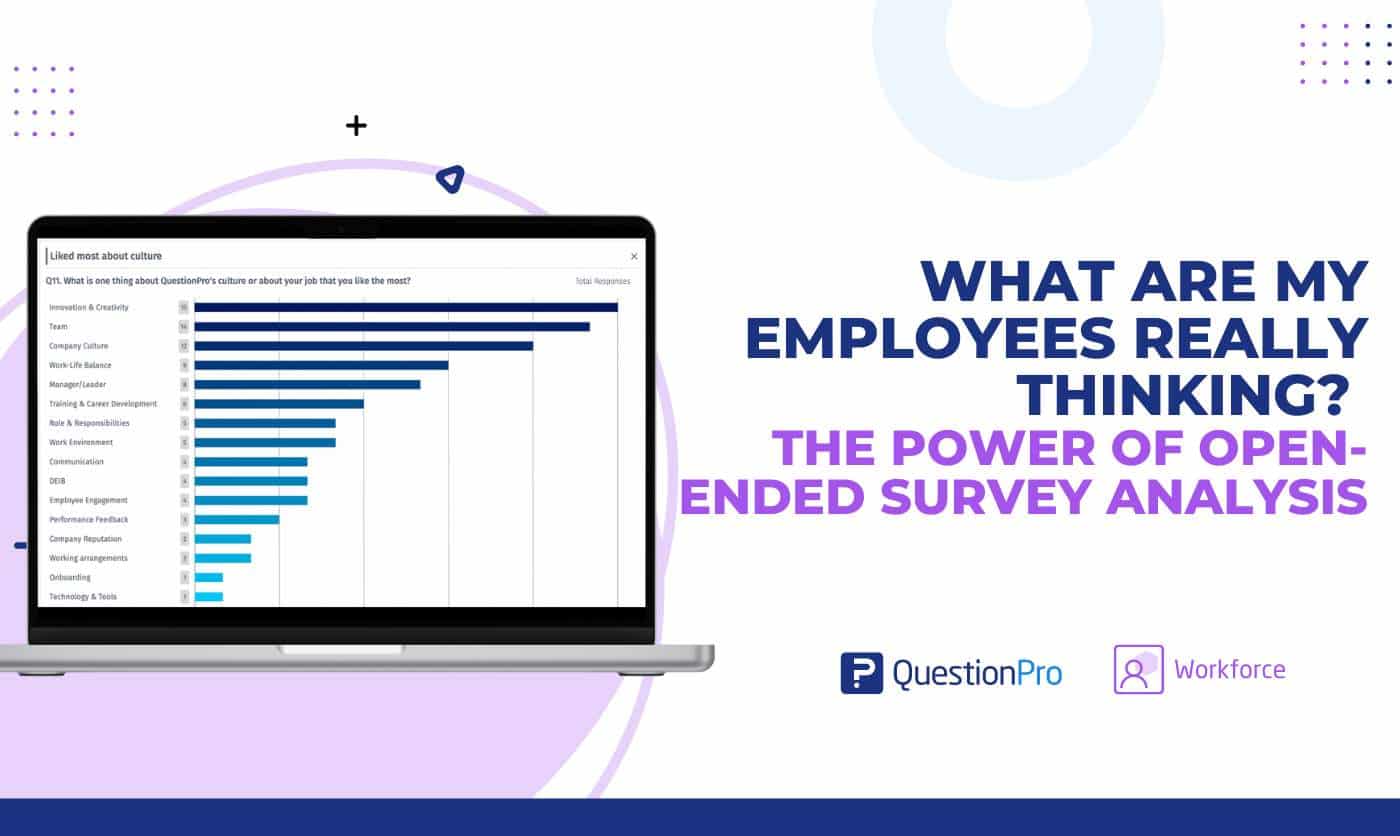
What Are My Employees Really Thinking? The Power of Open-ended Survey Analysis
May 24, 2024

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Case Study | Definition, Examples & Methods
Case Study | Definition, Examples & Methods
Published on 5 May 2022 by Shona McCombes . Revised on 30 January 2023.
A case study is a detailed study of a specific subject, such as a person, group, place, event, organisation, or phenomenon. Case studies are commonly used in social, educational, clinical, and business research.
A case study research design usually involves qualitative methods , but quantitative methods are sometimes also used. Case studies are good for describing , comparing, evaluating, and understanding different aspects of a research problem .
Table of contents
When to do a case study, step 1: select a case, step 2: build a theoretical framework, step 3: collect your data, step 4: describe and analyse the case.
A case study is an appropriate research design when you want to gain concrete, contextual, in-depth knowledge about a specific real-world subject. It allows you to explore the key characteristics, meanings, and implications of the case.
Case studies are often a good choice in a thesis or dissertation . They keep your project focused and manageable when you don’t have the time or resources to do large-scale research.
You might use just one complex case study where you explore a single subject in depth, or conduct multiple case studies to compare and illuminate different aspects of your research problem.
Prevent plagiarism, run a free check.
Once you have developed your problem statement and research questions , you should be ready to choose the specific case that you want to focus on. A good case study should have the potential to:
- Provide new or unexpected insights into the subject
- Challenge or complicate existing assumptions and theories
- Propose practical courses of action to resolve a problem
- Open up new directions for future research
Unlike quantitative or experimental research, a strong case study does not require a random or representative sample. In fact, case studies often deliberately focus on unusual, neglected, or outlying cases which may shed new light on the research problem.
If you find yourself aiming to simultaneously investigate and solve an issue, consider conducting action research . As its name suggests, action research conducts research and takes action at the same time, and is highly iterative and flexible.
However, you can also choose a more common or representative case to exemplify a particular category, experience, or phenomenon.
While case studies focus more on concrete details than general theories, they should usually have some connection with theory in the field. This way the case study is not just an isolated description, but is integrated into existing knowledge about the topic. It might aim to:
- Exemplify a theory by showing how it explains the case under investigation
- Expand on a theory by uncovering new concepts and ideas that need to be incorporated
- Challenge a theory by exploring an outlier case that doesn’t fit with established assumptions
To ensure that your analysis of the case has a solid academic grounding, you should conduct a literature review of sources related to the topic and develop a theoretical framework . This means identifying key concepts and theories to guide your analysis and interpretation.
There are many different research methods you can use to collect data on your subject. Case studies tend to focus on qualitative data using methods such as interviews, observations, and analysis of primary and secondary sources (e.g., newspaper articles, photographs, official records). Sometimes a case study will also collect quantitative data .
The aim is to gain as thorough an understanding as possible of the case and its context.
In writing up the case study, you need to bring together all the relevant aspects to give as complete a picture as possible of the subject.
How you report your findings depends on the type of research you are doing. Some case studies are structured like a standard scientific paper or thesis, with separate sections or chapters for the methods , results , and discussion .
Others are written in a more narrative style, aiming to explore the case from various angles and analyse its meanings and implications (for example, by using textual analysis or discourse analysis ).
In all cases, though, make sure to give contextual details about the case, connect it back to the literature and theory, and discuss how it fits into wider patterns or debates.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2023, January 30). Case Study | Definition, Examples & Methods. Scribbr. Retrieved 27 May 2024, from https://www.scribbr.co.uk/research-methods/case-studies/
Is this article helpful?

Shona McCombes
Other students also liked, correlational research | guide, design & examples, a quick guide to experimental design | 5 steps & examples, descriptive research design | definition, methods & examples.
Organizing Your Social Sciences Research Assignments
- Annotated Bibliography
- Analyzing a Scholarly Journal Article
- Group Presentations
- Dealing with Nervousness
- Using Visual Aids
- Grading Someone Else's Paper
- Types of Structured Group Activities
- Group Project Survival Skills
- Leading a Class Discussion
- Multiple Book Review Essay
- Reviewing Collected Works
- Writing a Case Analysis Paper
- Writing a Case Study
- About Informed Consent
- Writing Field Notes
- Writing a Policy Memo
- Writing a Reflective Paper
- Writing a Research Proposal
- Generative AI and Writing
- Acknowledgments
A case study research paper examines a person, place, event, condition, phenomenon, or other type of subject of analysis in order to extrapolate key themes and results that help predict future trends, illuminate previously hidden issues that can be applied to practice, and/or provide a means for understanding an important research problem with greater clarity. A case study research paper usually examines a single subject of analysis, but case study papers can also be designed as a comparative investigation that shows relationships between two or more subjects. The methods used to study a case can rest within a quantitative, qualitative, or mixed-method investigative paradigm.
Case Studies. Writing@CSU. Colorado State University; Mills, Albert J. , Gabrielle Durepos, and Eiden Wiebe, editors. Encyclopedia of Case Study Research . Thousand Oaks, CA: SAGE Publications, 2010 ; “What is a Case Study?” In Swanborn, Peter G. Case Study Research: What, Why and How? London: SAGE, 2010.
How to Approach Writing a Case Study Research Paper
General information about how to choose a topic to investigate can be found under the " Choosing a Research Problem " tab in the Organizing Your Social Sciences Research Paper writing guide. Review this page because it may help you identify a subject of analysis that can be investigated using a case study design.
However, identifying a case to investigate involves more than choosing the research problem . A case study encompasses a problem contextualized around the application of in-depth analysis, interpretation, and discussion, often resulting in specific recommendations for action or for improving existing conditions. As Seawright and Gerring note, practical considerations such as time and access to information can influence case selection, but these issues should not be the sole factors used in describing the methodological justification for identifying a particular case to study. Given this, selecting a case includes considering the following:
- The case represents an unusual or atypical example of a research problem that requires more in-depth analysis? Cases often represent a topic that rests on the fringes of prior investigations because the case may provide new ways of understanding the research problem. For example, if the research problem is to identify strategies to improve policies that support girl's access to secondary education in predominantly Muslim nations, you could consider using Azerbaijan as a case study rather than selecting a more obvious nation in the Middle East. Doing so may reveal important new insights into recommending how governments in other predominantly Muslim nations can formulate policies that support improved access to education for girls.
- The case provides important insight or illuminate a previously hidden problem? In-depth analysis of a case can be based on the hypothesis that the case study will reveal trends or issues that have not been exposed in prior research or will reveal new and important implications for practice. For example, anecdotal evidence may suggest drug use among homeless veterans is related to their patterns of travel throughout the day. Assuming prior studies have not looked at individual travel choices as a way to study access to illicit drug use, a case study that observes a homeless veteran could reveal how issues of personal mobility choices facilitate regular access to illicit drugs. Note that it is important to conduct a thorough literature review to ensure that your assumption about the need to reveal new insights or previously hidden problems is valid and evidence-based.
- The case challenges and offers a counter-point to prevailing assumptions? Over time, research on any given topic can fall into a trap of developing assumptions based on outdated studies that are still applied to new or changing conditions or the idea that something should simply be accepted as "common sense," even though the issue has not been thoroughly tested in current practice. A case study analysis may offer an opportunity to gather evidence that challenges prevailing assumptions about a research problem and provide a new set of recommendations applied to practice that have not been tested previously. For example, perhaps there has been a long practice among scholars to apply a particular theory in explaining the relationship between two subjects of analysis. Your case could challenge this assumption by applying an innovative theoretical framework [perhaps borrowed from another discipline] to explore whether this approach offers new ways of understanding the research problem. Taking a contrarian stance is one of the most important ways that new knowledge and understanding develops from existing literature.
- The case provides an opportunity to pursue action leading to the resolution of a problem? Another way to think about choosing a case to study is to consider how the results from investigating a particular case may result in findings that reveal ways in which to resolve an existing or emerging problem. For example, studying the case of an unforeseen incident, such as a fatal accident at a railroad crossing, can reveal hidden issues that could be applied to preventative measures that contribute to reducing the chance of accidents in the future. In this example, a case study investigating the accident could lead to a better understanding of where to strategically locate additional signals at other railroad crossings so as to better warn drivers of an approaching train, particularly when visibility is hindered by heavy rain, fog, or at night.
- The case offers a new direction in future research? A case study can be used as a tool for an exploratory investigation that highlights the need for further research about the problem. A case can be used when there are few studies that help predict an outcome or that establish a clear understanding about how best to proceed in addressing a problem. For example, after conducting a thorough literature review [very important!], you discover that little research exists showing the ways in which women contribute to promoting water conservation in rural communities of east central Africa. A case study of how women contribute to saving water in a rural village of Uganda can lay the foundation for understanding the need for more thorough research that documents how women in their roles as cooks and family caregivers think about water as a valuable resource within their community. This example of a case study could also point to the need for scholars to build new theoretical frameworks around the topic [e.g., applying feminist theories of work and family to the issue of water conservation].
Eisenhardt, Kathleen M. “Building Theories from Case Study Research.” Academy of Management Review 14 (October 1989): 532-550; Emmel, Nick. Sampling and Choosing Cases in Qualitative Research: A Realist Approach . Thousand Oaks, CA: SAGE Publications, 2013; Gerring, John. “What Is a Case Study and What Is It Good for?” American Political Science Review 98 (May 2004): 341-354; Mills, Albert J. , Gabrielle Durepos, and Eiden Wiebe, editors. Encyclopedia of Case Study Research . Thousand Oaks, CA: SAGE Publications, 2010; Seawright, Jason and John Gerring. "Case Selection Techniques in Case Study Research." Political Research Quarterly 61 (June 2008): 294-308.
Structure and Writing Style
The purpose of a paper in the social sciences designed around a case study is to thoroughly investigate a subject of analysis in order to reveal a new understanding about the research problem and, in so doing, contributing new knowledge to what is already known from previous studies. In applied social sciences disciplines [e.g., education, social work, public administration, etc.], case studies may also be used to reveal best practices, highlight key programs, or investigate interesting aspects of professional work.
In general, the structure of a case study research paper is not all that different from a standard college-level research paper. However, there are subtle differences you should be aware of. Here are the key elements to organizing and writing a case study research paper.
I. Introduction
As with any research paper, your introduction should serve as a roadmap for your readers to ascertain the scope and purpose of your study . The introduction to a case study research paper, however, should not only describe the research problem and its significance, but you should also succinctly describe why the case is being used and how it relates to addressing the problem. The two elements should be linked. With this in mind, a good introduction answers these four questions:
- What is being studied? Describe the research problem and describe the subject of analysis [the case] you have chosen to address the problem. Explain how they are linked and what elements of the case will help to expand knowledge and understanding about the problem.
- Why is this topic important to investigate? Describe the significance of the research problem and state why a case study design and the subject of analysis that the paper is designed around is appropriate in addressing the problem.
- What did we know about this topic before I did this study? Provide background that helps lead the reader into the more in-depth literature review to follow. If applicable, summarize prior case study research applied to the research problem and why it fails to adequately address the problem. Describe why your case will be useful. If no prior case studies have been used to address the research problem, explain why you have selected this subject of analysis.
- How will this study advance new knowledge or new ways of understanding? Explain why your case study will be suitable in helping to expand knowledge and understanding about the research problem.
Each of these questions should be addressed in no more than a few paragraphs. Exceptions to this can be when you are addressing a complex research problem or subject of analysis that requires more in-depth background information.
II. Literature Review
The literature review for a case study research paper is generally structured the same as it is for any college-level research paper. The difference, however, is that the literature review is focused on providing background information and enabling historical interpretation of the subject of analysis in relation to the research problem the case is intended to address . This includes synthesizing studies that help to:
- Place relevant works in the context of their contribution to understanding the case study being investigated . This would involve summarizing studies that have used a similar subject of analysis to investigate the research problem. If there is literature using the same or a very similar case to study, you need to explain why duplicating past research is important [e.g., conditions have changed; prior studies were conducted long ago, etc.].
- Describe the relationship each work has to the others under consideration that informs the reader why this case is applicable . Your literature review should include a description of any works that support using the case to investigate the research problem and the underlying research questions.
- Identify new ways to interpret prior research using the case study . If applicable, review any research that has examined the research problem using a different research design. Explain how your use of a case study design may reveal new knowledge or a new perspective or that can redirect research in an important new direction.
- Resolve conflicts amongst seemingly contradictory previous studies . This refers to synthesizing any literature that points to unresolved issues of concern about the research problem and describing how the subject of analysis that forms the case study can help resolve these existing contradictions.
- Point the way in fulfilling a need for additional research . Your review should examine any literature that lays a foundation for understanding why your case study design and the subject of analysis around which you have designed your study may reveal a new way of approaching the research problem or offer a perspective that points to the need for additional research.
- Expose any gaps that exist in the literature that the case study could help to fill . Summarize any literature that not only shows how your subject of analysis contributes to understanding the research problem, but how your case contributes to a new way of understanding the problem that prior research has failed to do.
- Locate your own research within the context of existing literature [very important!] . Collectively, your literature review should always place your case study within the larger domain of prior research about the problem. The overarching purpose of reviewing pertinent literature in a case study paper is to demonstrate that you have thoroughly identified and synthesized prior studies in relation to explaining the relevance of the case in addressing the research problem.
III. Method
In this section, you explain why you selected a particular case [i.e., subject of analysis] and the strategy you used to identify and ultimately decide that your case was appropriate in addressing the research problem. The way you describe the methods used varies depending on the type of subject of analysis that constitutes your case study.
If your subject of analysis is an incident or event . In the social and behavioral sciences, the event or incident that represents the case to be studied is usually bounded by time and place, with a clear beginning and end and with an identifiable location or position relative to its surroundings. The subject of analysis can be a rare or critical event or it can focus on a typical or regular event. The purpose of studying a rare event is to illuminate new ways of thinking about the broader research problem or to test a hypothesis. Critical incident case studies must describe the method by which you identified the event and explain the process by which you determined the validity of this case to inform broader perspectives about the research problem or to reveal new findings. However, the event does not have to be a rare or uniquely significant to support new thinking about the research problem or to challenge an existing hypothesis. For example, Walo, Bull, and Breen conducted a case study to identify and evaluate the direct and indirect economic benefits and costs of a local sports event in the City of Lismore, New South Wales, Australia. The purpose of their study was to provide new insights from measuring the impact of a typical local sports event that prior studies could not measure well because they focused on large "mega-events." Whether the event is rare or not, the methods section should include an explanation of the following characteristics of the event: a) when did it take place; b) what were the underlying circumstances leading to the event; and, c) what were the consequences of the event in relation to the research problem.
If your subject of analysis is a person. Explain why you selected this particular individual to be studied and describe what experiences they have had that provide an opportunity to advance new understandings about the research problem. Mention any background about this person which might help the reader understand the significance of their experiences that make them worthy of study. This includes describing the relationships this person has had with other people, institutions, and/or events that support using them as the subject for a case study research paper. It is particularly important to differentiate the person as the subject of analysis from others and to succinctly explain how the person relates to examining the research problem [e.g., why is one politician in a particular local election used to show an increase in voter turnout from any other candidate running in the election]. Note that these issues apply to a specific group of people used as a case study unit of analysis [e.g., a classroom of students].
If your subject of analysis is a place. In general, a case study that investigates a place suggests a subject of analysis that is unique or special in some way and that this uniqueness can be used to build new understanding or knowledge about the research problem. A case study of a place must not only describe its various attributes relevant to the research problem [e.g., physical, social, historical, cultural, economic, political], but you must state the method by which you determined that this place will illuminate new understandings about the research problem. It is also important to articulate why a particular place as the case for study is being used if similar places also exist [i.e., if you are studying patterns of homeless encampments of veterans in open spaces, explain why you are studying Echo Park in Los Angeles rather than Griffith Park?]. If applicable, describe what type of human activity involving this place makes it a good choice to study [e.g., prior research suggests Echo Park has more homeless veterans].
If your subject of analysis is a phenomenon. A phenomenon refers to a fact, occurrence, or circumstance that can be studied or observed but with the cause or explanation to be in question. In this sense, a phenomenon that forms your subject of analysis can encompass anything that can be observed or presumed to exist but is not fully understood. In the social and behavioral sciences, the case usually focuses on human interaction within a complex physical, social, economic, cultural, or political system. For example, the phenomenon could be the observation that many vehicles used by ISIS fighters are small trucks with English language advertisements on them. The research problem could be that ISIS fighters are difficult to combat because they are highly mobile. The research questions could be how and by what means are these vehicles used by ISIS being supplied to the militants and how might supply lines to these vehicles be cut off? How might knowing the suppliers of these trucks reveal larger networks of collaborators and financial support? A case study of a phenomenon most often encompasses an in-depth analysis of a cause and effect that is grounded in an interactive relationship between people and their environment in some way.
NOTE: The choice of the case or set of cases to study cannot appear random. Evidence that supports the method by which you identified and chose your subject of analysis should clearly support investigation of the research problem and linked to key findings from your literature review. Be sure to cite any studies that helped you determine that the case you chose was appropriate for examining the problem.
IV. Discussion
The main elements of your discussion section are generally the same as any research paper, but centered around interpreting and drawing conclusions about the key findings from your analysis of the case study. Note that a general social sciences research paper may contain a separate section to report findings. However, in a paper designed around a case study, it is common to combine a description of the results with the discussion about their implications. The objectives of your discussion section should include the following:
Reiterate the Research Problem/State the Major Findings Briefly reiterate the research problem you are investigating and explain why the subject of analysis around which you designed the case study were used. You should then describe the findings revealed from your study of the case using direct, declarative, and succinct proclamation of the study results. Highlight any findings that were unexpected or especially profound.
Explain the Meaning of the Findings and Why They are Important Systematically explain the meaning of your case study findings and why you believe they are important. Begin this part of the section by repeating what you consider to be your most important or surprising finding first, then systematically review each finding. Be sure to thoroughly extrapolate what your analysis of the case can tell the reader about situations or conditions beyond the actual case that was studied while, at the same time, being careful not to misconstrue or conflate a finding that undermines the external validity of your conclusions.
Relate the Findings to Similar Studies No study in the social sciences is so novel or possesses such a restricted focus that it has absolutely no relation to previously published research. The discussion section should relate your case study results to those found in other studies, particularly if questions raised from prior studies served as the motivation for choosing your subject of analysis. This is important because comparing and contrasting the findings of other studies helps support the overall importance of your results and it highlights how and in what ways your case study design and the subject of analysis differs from prior research about the topic.
Consider Alternative Explanations of the Findings Remember that the purpose of social science research is to discover and not to prove. When writing the discussion section, you should carefully consider all possible explanations revealed by the case study results, rather than just those that fit your hypothesis or prior assumptions and biases. Be alert to what the in-depth analysis of the case may reveal about the research problem, including offering a contrarian perspective to what scholars have stated in prior research if that is how the findings can be interpreted from your case.
Acknowledge the Study's Limitations You can state the study's limitations in the conclusion section of your paper but describing the limitations of your subject of analysis in the discussion section provides an opportunity to identify the limitations and explain why they are not significant. This part of the discussion section should also note any unanswered questions or issues your case study could not address. More detailed information about how to document any limitations to your research can be found here .
Suggest Areas for Further Research Although your case study may offer important insights about the research problem, there are likely additional questions related to the problem that remain unanswered or findings that unexpectedly revealed themselves as a result of your in-depth analysis of the case. Be sure that the recommendations for further research are linked to the research problem and that you explain why your recommendations are valid in other contexts and based on the original assumptions of your study.
V. Conclusion
As with any research paper, you should summarize your conclusion in clear, simple language; emphasize how the findings from your case study differs from or supports prior research and why. Do not simply reiterate the discussion section. Provide a synthesis of key findings presented in the paper to show how these converge to address the research problem. If you haven't already done so in the discussion section, be sure to document the limitations of your case study and any need for further research.
The function of your paper's conclusion is to: 1) reiterate the main argument supported by the findings from your case study; 2) state clearly the context, background, and necessity of pursuing the research problem using a case study design in relation to an issue, controversy, or a gap found from reviewing the literature; and, 3) provide a place to persuasively and succinctly restate the significance of your research problem, given that the reader has now been presented with in-depth information about the topic.
Consider the following points to help ensure your conclusion is appropriate:
- If the argument or purpose of your paper is complex, you may need to summarize these points for your reader.
- If prior to your conclusion, you have not yet explained the significance of your findings or if you are proceeding inductively, use the conclusion of your paper to describe your main points and explain their significance.
- Move from a detailed to a general level of consideration of the case study's findings that returns the topic to the context provided by the introduction or within a new context that emerges from your case study findings.
Note that, depending on the discipline you are writing in or the preferences of your professor, the concluding paragraph may contain your final reflections on the evidence presented as it applies to practice or on the essay's central research problem. However, the nature of being introspective about the subject of analysis you have investigated will depend on whether you are explicitly asked to express your observations in this way.
Problems to Avoid
Overgeneralization One of the goals of a case study is to lay a foundation for understanding broader trends and issues applied to similar circumstances. However, be careful when drawing conclusions from your case study. They must be evidence-based and grounded in the results of the study; otherwise, it is merely speculation. Looking at a prior example, it would be incorrect to state that a factor in improving girls access to education in Azerbaijan and the policy implications this may have for improving access in other Muslim nations is due to girls access to social media if there is no documentary evidence from your case study to indicate this. There may be anecdotal evidence that retention rates were better for girls who were engaged with social media, but this observation would only point to the need for further research and would not be a definitive finding if this was not a part of your original research agenda.
Failure to Document Limitations No case is going to reveal all that needs to be understood about a research problem. Therefore, just as you have to clearly state the limitations of a general research study , you must describe the specific limitations inherent in the subject of analysis. For example, the case of studying how women conceptualize the need for water conservation in a village in Uganda could have limited application in other cultural contexts or in areas where fresh water from rivers or lakes is plentiful and, therefore, conservation is understood more in terms of managing access rather than preserving access to a scarce resource.
Failure to Extrapolate All Possible Implications Just as you don't want to over-generalize from your case study findings, you also have to be thorough in the consideration of all possible outcomes or recommendations derived from your findings. If you do not, your reader may question the validity of your analysis, particularly if you failed to document an obvious outcome from your case study research. For example, in the case of studying the accident at the railroad crossing to evaluate where and what types of warning signals should be located, you failed to take into consideration speed limit signage as well as warning signals. When designing your case study, be sure you have thoroughly addressed all aspects of the problem and do not leave gaps in your analysis that leave the reader questioning the results.
Case Studies. Writing@CSU. Colorado State University; Gerring, John. Case Study Research: Principles and Practices . New York: Cambridge University Press, 2007; Merriam, Sharan B. Qualitative Research and Case Study Applications in Education . Rev. ed. San Francisco, CA: Jossey-Bass, 1998; Miller, Lisa L. “The Use of Case Studies in Law and Social Science Research.” Annual Review of Law and Social Science 14 (2018): TBD; Mills, Albert J., Gabrielle Durepos, and Eiden Wiebe, editors. Encyclopedia of Case Study Research . Thousand Oaks, CA: SAGE Publications, 2010; Putney, LeAnn Grogan. "Case Study." In Encyclopedia of Research Design , Neil J. Salkind, editor. (Thousand Oaks, CA: SAGE Publications, 2010), pp. 116-120; Simons, Helen. Case Study Research in Practice . London: SAGE Publications, 2009; Kratochwill, Thomas R. and Joel R. Levin, editors. Single-Case Research Design and Analysis: New Development for Psychology and Education . Hilldsale, NJ: Lawrence Erlbaum Associates, 1992; Swanborn, Peter G. Case Study Research: What, Why and How? London : SAGE, 2010; Yin, Robert K. Case Study Research: Design and Methods . 6th edition. Los Angeles, CA, SAGE Publications, 2014; Walo, Maree, Adrian Bull, and Helen Breen. “Achieving Economic Benefits at Local Events: A Case Study of a Local Sports Event.” Festival Management and Event Tourism 4 (1996): 95-106.
Writing Tip
At Least Five Misconceptions about Case Study Research
Social science case studies are often perceived as limited in their ability to create new knowledge because they are not randomly selected and findings cannot be generalized to larger populations. Flyvbjerg examines five misunderstandings about case study research and systematically "corrects" each one. To quote, these are:
Misunderstanding 1 : General, theoretical [context-independent] knowledge is more valuable than concrete, practical [context-dependent] knowledge. Misunderstanding 2 : One cannot generalize on the basis of an individual case; therefore, the case study cannot contribute to scientific development. Misunderstanding 3 : The case study is most useful for generating hypotheses; that is, in the first stage of a total research process, whereas other methods are more suitable for hypotheses testing and theory building. Misunderstanding 4 : The case study contains a bias toward verification, that is, a tendency to confirm the researcher’s preconceived notions. Misunderstanding 5 : It is often difficult to summarize and develop general propositions and theories on the basis of specific case studies [p. 221].
While writing your paper, think introspectively about how you addressed these misconceptions because to do so can help you strengthen the validity and reliability of your research by clarifying issues of case selection, the testing and challenging of existing assumptions, the interpretation of key findings, and the summation of case outcomes. Think of a case study research paper as a complete, in-depth narrative about the specific properties and key characteristics of your subject of analysis applied to the research problem.
Flyvbjerg, Bent. “Five Misunderstandings About Case-Study Research.” Qualitative Inquiry 12 (April 2006): 219-245.
- << Previous: Writing a Case Analysis Paper
- Next: Writing a Field Report >>
- Last Updated: May 7, 2024 9:45 AM
- URL: https://libguides.usc.edu/writingguide/assignments
- The 1%: Conquer Your Consulting Case Interview
- Consulting Career Secrets
- Cover Letter & Resume
- McKinsey Solve Game (Imbellus)
- BCG Online Case (+ Pymetrics, Spark Hire)
- Bain Aptitude Tests (SOVA, Pymetrics, HireVue)
- Kearney Recruitment Test
- BCG Cognitive Test Practice
- All-in-One Case Interview Preparation
- Industry Cheat Sheets
- Structuring & Brainstorming
- Data & Chart Interpretation
- Case Math Mastery
- McKinsey Interview Academy
- Brainteasers
How to Interpret Charts and Data in Case Interviews

Last Updated on March 27, 2024
On your journey to solve the case in a case interview, you must sort through and interpret data presented in the form of charts and data tables. The exhibit interpretation in a case is usually the most straightforward section since it is the only part of the case where you do not need to come up with new content, rather read and interpret what is already there.
Still, it is an essential skill you need to learn and master to rank highly with your interviewers. Mastering case interview charts is crucial for candidates aiming to excel in consulting data analysis.
In fact, 90% of consulting case interviews will have you interpret charts and data or 100% of top-tier firm interviews such as McKinsey , BCG , and Bain .
This article is part of our consulting case interview series. It aims to teach you how to interpret charts in consulting interviews, ensuring you’re well-prepared to tackle this aspect of the process. For the other articles, please click below:
- Overview of case interviews: what is a consulting case interview?
- How to create a case interview framework
- How to ace case interview exhibit and chart interpretation (this article)
- How to ace case interview math questions
Charts and Exhibits in Consulting Case Interviews
Before diving deep into specific charts, let’s understand the basics of mastering data analysis for consulting case interviews.
Two types of exhibits
Exhibits in presentations and analytical reports in case interviews generally fall into two primary categories, each with its unique approach to data visualization:
- Charts – This category encompasses a variety of graphical representations used to visualize data, making complex information easier to understand at a glance. These can include but are not limited to, scatter plots that display data points across two dimensions, bubble charts that add a third dimension with the size of the bubble, line graphs that show trends over time, bar charts that compare quantities among different groups, and pie charts that illustrate the proportional breakdown of a whole into its constituent parts. Other visualization tools like histograms, area charts, and radar charts also fall into this category, each offering distinct advantages for presenting specific types of data.
- Tables – As a more traditional form of data presentation, tables organize data in rows and columns, providing a straightforward way to display numerical values, text information, or both. They are particularly useful for presenting detailed data where precise values are important. Tables enable viewers to compare individual data points directly and are often used to supplement charts by providing the exact figures that the charts represent visually.
Both charts and tables play crucial roles in conveying information, whether it’s financial figures for a company, growth metrics for a market, demographic statistics for a country, or product comparisons among competitors. The choice between a chart and a table often depends on the nature of the data being presented and the message the presenter wishes to convey.
Some charts are better suited for demonstrating trends over time, such as line graphs, while others, like pie charts, are ideal for showing composition. The challenge, especially in scenarios like case interviews, lies in working with the type of exhibit provided, which may not always be the most optimal for the data or context at hand. This requires flexibility and creativity from the interviewee to make the most of the available tools and effectively interpret the underlying data insights.
The challenges to overcome
As a case interview candidate, you need to quickly skim through the data, elicit the key insights, and derive what it means for the situation at hand within the context of the case (the so-what? ). Many candidates struggle with this part of the interview since they either do not have a clear approach or are unsure how to spot key insights.
In fact, being able to quickly skim through a wide range of data, elicit the key information, and derive top-down what it means for the question at hand is a key skill that all major consulting firms are looking for in candidates.
You can train this skill and improve your analytical approach to data tables and graphs and along the way improve your overall performance in the case.
Let’s first look at what to expect in a case interview.
Types of Charts and Exhibits in Case Interviews
The good news for you: Firms such as McKinsey, BCG, and Bain always use the same types of charts in their case interviews as well as on the job.
Below is an almost exhaustive library of all charts and common variations you should expect during the case interview, covering 99% of what we have seen in interviews, on the job, and from colleagues.
More often than not, you will be presented with more than one chart and have to interpret and find the key insights by combining the two. Also, sometimes charts can be combined and a bar chart could also contain a line or two from a typical line chart. Understanding a variety of chart interpretation skills is fundamental during your consulting case practice.
As a side note: We have populated the charts with random numbers and random legends to make them appear more realistic as they would look like in a case interview. In practice, each chart can display many things.

Chart and Exhibit Course and Drills for Case Interviews
Learn how to decipher and analyze charts and exhibits in a case interview like a real top-tier consultant. This course teaches you a proven methodology and strategy to interpret every chart you encounter in the context of the case interview with ease.
Essential chart types for consulting case interviews include bar graphs, pie charts, and scatter plots, among others.
Bar charts are most commonly used when comparing values of several items at a specific point in time, or 1-2 items at several time intervals. Too many items or time intervals have a negative impact on the readability.
One variation you might come across in case interviews is the stacked bar chart . It extends the standard bar chart by one or more categorical variables. Each bar is divided into two or more sub-bars, each one corresponding to a different categorical variable.

Another variation of the bar chart is the 100% bar chart . It’s a stacked bar chart that shows the relative percentage of multiple data series in stacked bars, with the total of each full bar always equalling 100%. Be aware that, while all bars have the same height visually, they do not necessarily have the same total.

The clustered bar chart visualizes multiple sets of data over the same categories (like revenue of two products over three years).

Bar charts are less suitable to illustrate parts to visualize parts of a whole unless they come in a waterfall chart form. A waterfall chart can be either built up to a total or built down from a starting point to a new ending point.

A specific form of a bar chart would be a histogram , which displays an approximate representation of the distribution of numerical data. Histograms can be used to provide insights into mean and standard deviation.

Line charts
Line charts illustrate time-series data, i.e. development, and trends in data over a specific time period. Contrary to bar charts, they consume almost no space since the points in time are connected by lines, which allows visualizing a large number of time intervals.

They are not used to show data breakdowns and tend to become confusing with more than 5 simultaneous variables (lines).
The pie chart’s core strength is to visualize proportions. They include all parts of a whole, without any overlap in their segmentation. Pie charts can also be displayed as donut chars (same, just with a hole in the middle).

Time series cannot be displayed with pie charts.
Scatter plots
Scatter plots visualize how two variables relate to each other by plotting data points on a matrix. They are an extremely powerful tool to look at the correlation of variables by being able to display an infinite amount of data points, while still keeping readability.

Scatter plots are limited by the number of axes (e.g., two axes can display two variables).
The bubble chart is a variation of the scatter plot that allows displaying the size of a certain data point, thereby introducing a third variable into the picture. The size of the bubble can visualize many things. It usually shows much fewer data points than a scatter plot.
Area charts
An area chart is a combination of a line and bar chart, visualizing how the values of one or more variables change over the progression of a second variable, usually time.

Like a bar chart, there can be different variations such as stacked area charts or 100% area charts.
Spider charts
A spider chart, also called a radar chart, can be used to display multivariate data in the form of a two-dimensional chart with three or more quantitative variables represented on axes starting from the same point. A line connects the data values for each spoke.

Flow charts
Flow charts or process charts visualize a process or a system and its individual parts. They can be used to describe, improve, and communicate simple or complex processes in clear and easy-to-understand diagrams.
Below, I have pasted your consulting application journey , which is well suited to demonstrate the merits of flow charts.

Now that you know what types of charts can show up in a case interview, let’s have a brief look at data tables.
Data tables
Data tables display information in tabular form with labeled rows and/or columns. They are commonly used to display client data (e.g., financial information), market data (e.g., sales information), economic data (e.g., GDP), and population data (e.g., demographics) amongst other things. Their format helps to organize disparate data and permits you to quickly digest it.
The way data is presented in tabular form can differ. For an example of the different stylistic elements a data table can contain, check out the table below. Familiarize yourself with best practices for data tables in case interviews to enhance your proficiency.

We’ve compiled essential tips for consulting case interview chart interpretation to help you excel in your analytical approach. Our guide to exhibit analysis in consulting interviews will walk you through the process, ensuring you’re fully equipped. Employ strategies for effective consulting case analysis to systematically approach each case.
To interpret charts most effectively and find their ‘so-what’ to impress the interviewer, you need to demonstrate structured thinking and strong communication whenever you are asked to interpret data in the form of tables, graphs, etc.
A 7-step approach to distinctive chart interpretation
If you want to impress interviewers by interpreting exhibits in the most effective and time-conserving manner, follow these seven steps :
- Restate and clarify the purpose of your exhibit analysis , i.e., what you want to do with it (candidate-led format) or play back the question you are trying to answer (interviewer-led format). You must be clear about the purpose of the exhibit at the given stage of the case. The exhibit does not exist in a vacuum but is the result of your probing (candidate-led format) or the natural case sequence (interviewer-led format), and it should be looked at with a certain goal in mind, usually to verify a certain hypothesis of yours. An exhibit without context has no purpose. Only if you approach the exhibit interpretation with a clear objective in mind will you be able to spot and interpret the correct insights.
- Briefly describe what you see on the exhibit by looking at the title, units, labels, legends, columns, rows, etc. You want to familiarize yourself with what you see and play it back to the interviewer in two to three sentences. Keep this part brief.
- Clarify whenever something is unclear. Never interpret a chart before confirming your assumptions about what is displayed with the interviewer. It could be that you are not familiar with a word, concept, label, or some explanations might be missing. Always be clear about what the chart is covering. For instance, is it our client’s data, is it market data, or is it competitor data? Are you dealing with the general population or a subset of it? Is the chart backward-looking or a forecast?
- Ask for time to structure your thoughts , usually around 30 seconds to one minute. During that period, write down the key insights, the implications, and the next steps.
- Communicate your key insights , which are the two to four most important data points on a chart, usually outliers or data points that surprise you. Communicate in a structured, top-down manner.
- Communicate the implications (the so-what? ) proactively, interpreting the data in the context of the case and highlighting what you would recommend based on the available data (what to do) or what the data tells you about the situation at hand (what it means).
- Communicate the next steps , discussing automatically how you would move forward in a structured manner, for instance, what additional analyses you want to conduct or what concrete implementation measures you would recommend.
This approach is highly effective in guiding your exhibit analysis and decision-making about what to do with the data.
The importance of taking time
I want to stress the importance of taking time to think about your analysis , the fourth step of my approach. This habit is the biggest differentiator between successful and unsuccessful candidates, and I see its impact daily. Unsuccessful candidates try to rush through their analysis, reading and interpreting the chart on the go, all while talking to the interviewer.
As a result, they miss key facts, fail to properly contextualize data for the case at hand, appear unstructured and chaotic, and overall take longer. I remember the disappointed faces of candidates that I challenged based on their rushed analysis and the aha moments that resulted. By thinking about these things beforehand, you can streamline your insight generation, contextualization, and communication. Taking the time comes with two additional benefits:
- You demonstrate to the interviewer that you can push back under pressure and are confident enough to take time to think (highly relevant when dealing with demanding senior clients).
- You get additional time to identify what might be unclear related to the information from the interviewer or the exhibit itself. Exhibits might come with missing or unclear labels, units, or legends and you want to clarify what is displayed before discussing the correct insights and implications.
Communicate top-down
Whenever you present an insight during a case interview you should communicate your findings top-down . The same is true when presenting your interpretation of a chart, table, graph, etc. Start with the single most important fact you can extract from the chart.
- Give the answer or the key insights the interviewer is looking for ( “I see three key insights,….” ).
- Discuss the implications of the data, the ‘so-what’ for the client problem you are trying to figure out and find a recommendation for. Tie those findings to the case and your analysis and interpret their implications. ( “Based on this it suggests that….” )
- Move on to the next steps. ( “To move this forward I would….” )
Don’t start going in circles; don’t go astray. Stay structured and hit the interviewer with the key points. The interviewer mimics the client and senior clients usually don’t have much time to spare. Every sentence in the chart interpretation part should add value to your analysis. Stay away from empty words and phrases or worse aimless rambling.
By setting your communication up that way, you demonstrate that you are able to
- Retrieve key insights in a data set quickly.
- Communicate top-down with senior executives.
- Consider the impact of the data on the current issue.
- Move forward.
Also, you give the interviewer a chance to dig deeper to understand your reasoning.
Avoid the Most Common Pitfalls
Candidates often encounter difficulties with exhibit analysis consulting, highlighting the importance of thorough consulting interview preparation.
The 2 key mistakes
Avoid the two most common mistakes I see in almost every initial case with my clients:
- Do not read back every detail and data point from the chart. A senior partner once told me in the early days of my career that he did not need assisted reading when I was guiding him through all data points on a chart instead of focusing on the relevant key insights only. This reminded me of many of my interviewees, who tend to do the same without proper training or coaching.
- Ensure you translate the data and insights into actual implications and recommendations. Good candidates can elicit the key pieces of information from an exhibit. Excellent candidates interpret these findings in the context of the case and use them to sharpen their hypotheses, deduct implications, and plan a way forward.
Further pitfalls
Other common pitfalls to avoid include:
Steer clear of these common pitfalls and you already fare better than 80% of the case interview candidates I’ve interviewed before our first coaching session where they learn the right habits.
Typical Exhibit Insights to Look Out For
Learning how to dissect case interview visuals and data table analysis can set you apart. You need to understand what to look out for.
Types of data points
Usually, you are confronted with many different data points and information on one or two exhibits. To figure out what the key insights are, group the data points on any given exhibit into three different categories:
- Data points that are relevant for you: The key is to select the most important bits of information, usually outliers, unexpected data, or abnormalities that are relevant in the context of the case, and most striking when looking at the exhibit. Some of those insights might be generated by combining several data points.
- Data points that are not relevant: There are always other things you could discuss, but in the interest of time, skip every data point that is not relevant for the case or your hypothesis or simply not interesting enough (e.g., a two percent drop in revenue for one particular product category is not that interesting if another product’s revenue dropped by 23%). Think 80/20 .
- Misleading data points: Not all information shown to you is insightful or important, and some might even be misleading, just to create noise and distract you. Some exhibits might contain decoys that trick you into faulty conclusions. Hence, think before you speak and do not blurt out faulty statements that come to your mind quickly and might be based on wrong assumptions.
Let’s have a look into the typical data points that are relevant for you – the first category from above.
Typical categories of insights
- internal vs. external (e.g., client vs. market)
- internal vs. internal (e.g., product A vs. product B)
- external vs. external (e.g., competitor A vs. competitor B)
- scenarios (e.g., supplier A vs. supplier B; option A vs. option B).
- breakdown of a process (e.g., customer journey)
- breakdown of financials (e.g., revenue)
- breakdown of business segments (e.g., sales)
- breakdown of geographic regions (e.g., growth).
- positive (e.g., cost and quality)
- negative (e.g., age and health).
- financials (e.g., revenue)
- customer data (e.g., purchasing behavior, satisfaction).
Types of insights, usually outliers
- A figure or group of figures is very small or very large compared to the others, often based on a comparison of patterns and correlations.
- A figure is very different from what you would have expected (rejects your hypothesis) or exactly what you would have expected (confirms your hypothesis).
- A figure or breakdown of figures is very different than others.
- A figure or group of figures shows high or low growth (decline) compared to the others.
- The data changes significantly at a certain point (e.g., spikes or bottoms, trend reversals).
- On average, the figures look good, however, when digging deeper into specific segments you see certain issues or deviations.
Learn how to spot those kinds of patterns quickly.
When you are given two or more charts, the key insights often come from combining the data points of both. For instance, if you are comparing checkout speed across several stores the number of cashier desks alone is not enough. You might only get to an insight if you are able to relate the number of cashier desks to things such as the size of the store, the number of customers, the number of items purchased, etc.
Train Chart Interpretation
Improving your exhibit interpretation skills for consulting can dramatically increase your chances of success. Enhance your consulting interview preparation with chart analysis by practicing with real-world examples and professionals.
Free practice
You can quickly improve your exhibit interpretation skills by applying the approach, the right communication, and the tips above to practical examples. Prepare for case interviews by analyzing charts in magazines such as The Economist or The Wall Street Journal . A quick Google search for “ Chart of the day” yields thousands of results that you can use to practice and hone your chart interpretation skills. To check your insights, compare them with the text of the articles accompanying these charts. Additionally, look for online case libraries and go through university consulting club casebooks.
When practicing, follow the steps I describe above.
- Internalize the seven steps.
- Time yourself to create realistic conditions and pressure (one minute to think, one to two minutes to communicate your analysis).
- Train your eyes to find insights quickly based on outliers and abnormalities.
- Train your mind to generate implications and next steps in the context of the case.
- Become comfortable with the top-down communication of your analysis by practicing out loud, including recording yourself and critically listening to your performance.
Courses and professional coaches
For those keen on enhancing their chart analysis skills through a comprehensive approach, our dedicated course offers an invaluable resource . It’s designed with precision to cater to learners at all levels, featuring extensive discussions on a plethora of examples and equipped with 50 practice questions. These questions are not ordinary; they come with high-quality charts and data tables that meet the rigorous standards of top-tier consulting firms like McKinsey, the Boston Consulting Group, and Bain & Company. This course is the fastest and most realistic way to practice and master chart analysis, providing you with the tools and insights needed to excel in your endeavors.
Alternatively, I do offer private coaching sessions and – at the time of updating this article – have conducted more than 1,600 case interview sessions.
In addition, establish a case interview math practice routine since case math might be based – as a follow-up question – on the exhibits you receive during the interview.
How We Help You Ace MBB Interviews
We have specialized in placing people from all walks of life with different backgrounds into top consulting firms both as generalist hires as well as specialized hires and experts. As former McKinsey consultants and interview experts, we help you by
- tailoring your resume and cover letter to meet consulting firms’ highest standards
- showing you how to pass the different online assessments and tests for McKinsey , BCG , and Bain
- showing you how to ace McKinsey interviews and the PEI with our video academy
- coaching you in our 1-on-1 sessions to become an excellent case solver and impress with your fit answers (90% success rate after 5 sessions)
- preparing your math to be bulletproof for every case interview
- helping you structure creative and complex case interviews
- teaching you how to interpret charts and exhibits like a consultant
- providing you with cheat sheets and overviews for 27 industries .
Reach out to us if you have any questions! We are happy to help and offer a tailored program to help you break into consulting.

Frequently Asked Questions: Chart Interpretation
Navigating through charts and data tables in case interviews can be daunting. Here’s a FAQ to help you deepen your understanding and sharpen your exhibit interpretation skills for success in consulting case interviews.
How can I develop a hypothesis before analyzing the charts and data tables in a case interview? Start by understanding the case’s objectives and identifying potential areas of interest or concern. Use this initial insight to frame a hypothesis that your analysis of charts and data tables will either support or refute.
Are there specific types of charts or data tables that are more prevalent in certain industries or types of case studies? Yes, certain industries prefer specific types of data visualization. For example, financial sectors often use line charts for trend analysis, while marketing studies may rely on pie charts to illustrate market segments.
What are the best practices for managing time while interpreting exhibits during a case interview? Quickly skim the exhibit to grasp the main idea, then focus on the most relevant data points that relate to your hypothesis. Practice a structured approach to quickly elicit insights without sacrificing thoroughness.
Can you provide examples of how misinterpreting a chart or data table has led to incorrect conclusions in real consulting projects? Common errors include misreading the scale on graphs, overlooking footnotes that clarify data, and assuming correlation implies causation without further analysis.
How does the interpretation of exhibits differ between candidate-led and interviewer-led case interviews? In candidate-led interviews, you choose which data to explore to support your hypothesis, while in interviewer-led cases, you’ll analyze the exhibits provided by the interviewer in line with their questions.
What are some advanced techniques for identifying interesting data points? Look for data points that don’t fit the overall trend or pattern, question outliers, and consider the broader context of the case to determine whether the data is truly relevant.
How can candidates effectively practice exhibit interpretation outside of the context of a case interview (e.g., using real-world data)? Engage with real-world business news, analyze the charts and data presented, and try to draw conclusions or insights as if you were preparing a consulting recommendation. Work with proper drill programs.
What role do cultural or regional differences play in the presentation and interpretation of data in case interviews across different offices of MBB firms? From my experience, there is no difference across firms and offices. All firms work on a global scale on similar business problems, which is also reflected in the types of interviews and exhibits.
How can a candidate demonstrate their analytical skills when the data presented in the exhibit is insufficient or incomplete? Highlight the gaps in the data, suggest ways to fill these gaps based on logical assumptions, and explain how additional information would influence your analysis.
In sum, understanding data visualization in consulting cases is pivotal for articulating compelling recommendations.
Struggling with charts and data in case interviews?
We know that mastering the art of exhibit interpretation can be daunting, but you’re not alone in this journey. If you have any questions or need further clarification, don’t hesitate to ask them below in the comment section. Your queries not only help you but also assist others facing similar challenges. Let’s navigate the complexities of case interviews together and turn obstacles into stepping stones for success.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *

Florian spent 5 years with McKinsey as a senior consultant. He is an experienced consulting interviewer and problem-solving coach, having interviewed 100s of candidates in real and mock interviews. He started StrategyCase.com to make top-tier consulting firms more accessible for top talent, using tailored and up-to-date know-how about their recruiting. He ranks as the most successful consulting case and fit interview coach, generating more than 500 offers with MBB, tier-2 firms, Big 4 consulting divisions, in-house consultancies, and boutique firms through direct coaching of his clients over the last 3.5 years. His books “The 1%: Conquer Your Consulting Case Interview” and “Consulting Career Secrets” are available via Amazon.
Most Popular Products

Search website
Strategycase.com.
© 2024 | Contact: +43 6706059449 | Mattiellistrasse 3/28, 1040 Vienna, Austria
- Terms & Conditions
- Privacy Policy
- Universities & consulting clubs
- American Express
Click on the image to learn more.

- Privacy Policy
Home » Case Study – Methods, Examples and Guide
Case Study – Methods, Examples and Guide
Table of Contents

A case study is a research method that involves an in-depth examination and analysis of a particular phenomenon or case, such as an individual, organization, community, event, or situation.
It is a qualitative research approach that aims to provide a detailed and comprehensive understanding of the case being studied. Case studies typically involve multiple sources of data, including interviews, observations, documents, and artifacts, which are analyzed using various techniques, such as content analysis, thematic analysis, and grounded theory. The findings of a case study are often used to develop theories, inform policy or practice, or generate new research questions.
Types of Case Study
Types and Methods of Case Study are as follows:
Single-Case Study
A single-case study is an in-depth analysis of a single case. This type of case study is useful when the researcher wants to understand a specific phenomenon in detail.
For Example , A researcher might conduct a single-case study on a particular individual to understand their experiences with a particular health condition or a specific organization to explore their management practices. The researcher collects data from multiple sources, such as interviews, observations, and documents, and uses various techniques to analyze the data, such as content analysis or thematic analysis. The findings of a single-case study are often used to generate new research questions, develop theories, or inform policy or practice.
Multiple-Case Study
A multiple-case study involves the analysis of several cases that are similar in nature. This type of case study is useful when the researcher wants to identify similarities and differences between the cases.
For Example, a researcher might conduct a multiple-case study on several companies to explore the factors that contribute to their success or failure. The researcher collects data from each case, compares and contrasts the findings, and uses various techniques to analyze the data, such as comparative analysis or pattern-matching. The findings of a multiple-case study can be used to develop theories, inform policy or practice, or generate new research questions.
Exploratory Case Study
An exploratory case study is used to explore a new or understudied phenomenon. This type of case study is useful when the researcher wants to generate hypotheses or theories about the phenomenon.
For Example, a researcher might conduct an exploratory case study on a new technology to understand its potential impact on society. The researcher collects data from multiple sources, such as interviews, observations, and documents, and uses various techniques to analyze the data, such as grounded theory or content analysis. The findings of an exploratory case study can be used to generate new research questions, develop theories, or inform policy or practice.
Descriptive Case Study
A descriptive case study is used to describe a particular phenomenon in detail. This type of case study is useful when the researcher wants to provide a comprehensive account of the phenomenon.
For Example, a researcher might conduct a descriptive case study on a particular community to understand its social and economic characteristics. The researcher collects data from multiple sources, such as interviews, observations, and documents, and uses various techniques to analyze the data, such as content analysis or thematic analysis. The findings of a descriptive case study can be used to inform policy or practice or generate new research questions.
Instrumental Case Study
An instrumental case study is used to understand a particular phenomenon that is instrumental in achieving a particular goal. This type of case study is useful when the researcher wants to understand the role of the phenomenon in achieving the goal.
For Example, a researcher might conduct an instrumental case study on a particular policy to understand its impact on achieving a particular goal, such as reducing poverty. The researcher collects data from multiple sources, such as interviews, observations, and documents, and uses various techniques to analyze the data, such as content analysis or thematic analysis. The findings of an instrumental case study can be used to inform policy or practice or generate new research questions.
Case Study Data Collection Methods
Here are some common data collection methods for case studies:
Interviews involve asking questions to individuals who have knowledge or experience relevant to the case study. Interviews can be structured (where the same questions are asked to all participants) or unstructured (where the interviewer follows up on the responses with further questions). Interviews can be conducted in person, over the phone, or through video conferencing.
Observations
Observations involve watching and recording the behavior and activities of individuals or groups relevant to the case study. Observations can be participant (where the researcher actively participates in the activities) or non-participant (where the researcher observes from a distance). Observations can be recorded using notes, audio or video recordings, or photographs.
Documents can be used as a source of information for case studies. Documents can include reports, memos, emails, letters, and other written materials related to the case study. Documents can be collected from the case study participants or from public sources.
Surveys involve asking a set of questions to a sample of individuals relevant to the case study. Surveys can be administered in person, over the phone, through mail or email, or online. Surveys can be used to gather information on attitudes, opinions, or behaviors related to the case study.
Artifacts are physical objects relevant to the case study. Artifacts can include tools, equipment, products, or other objects that provide insights into the case study phenomenon.
How to conduct Case Study Research
Conducting a case study research involves several steps that need to be followed to ensure the quality and rigor of the study. Here are the steps to conduct case study research:
- Define the research questions: The first step in conducting a case study research is to define the research questions. The research questions should be specific, measurable, and relevant to the case study phenomenon under investigation.
- Select the case: The next step is to select the case or cases to be studied. The case should be relevant to the research questions and should provide rich and diverse data that can be used to answer the research questions.
- Collect data: Data can be collected using various methods, such as interviews, observations, documents, surveys, and artifacts. The data collection method should be selected based on the research questions and the nature of the case study phenomenon.
- Analyze the data: The data collected from the case study should be analyzed using various techniques, such as content analysis, thematic analysis, or grounded theory. The analysis should be guided by the research questions and should aim to provide insights and conclusions relevant to the research questions.
- Draw conclusions: The conclusions drawn from the case study should be based on the data analysis and should be relevant to the research questions. The conclusions should be supported by evidence and should be clearly stated.
- Validate the findings: The findings of the case study should be validated by reviewing the data and the analysis with participants or other experts in the field. This helps to ensure the validity and reliability of the findings.
- Write the report: The final step is to write the report of the case study research. The report should provide a clear description of the case study phenomenon, the research questions, the data collection methods, the data analysis, the findings, and the conclusions. The report should be written in a clear and concise manner and should follow the guidelines for academic writing.
Examples of Case Study
Here are some examples of case study research:
- The Hawthorne Studies : Conducted between 1924 and 1932, the Hawthorne Studies were a series of case studies conducted by Elton Mayo and his colleagues to examine the impact of work environment on employee productivity. The studies were conducted at the Hawthorne Works plant of the Western Electric Company in Chicago and included interviews, observations, and experiments.
- The Stanford Prison Experiment: Conducted in 1971, the Stanford Prison Experiment was a case study conducted by Philip Zimbardo to examine the psychological effects of power and authority. The study involved simulating a prison environment and assigning participants to the role of guards or prisoners. The study was controversial due to the ethical issues it raised.
- The Challenger Disaster: The Challenger Disaster was a case study conducted to examine the causes of the Space Shuttle Challenger explosion in 1986. The study included interviews, observations, and analysis of data to identify the technical, organizational, and cultural factors that contributed to the disaster.
- The Enron Scandal: The Enron Scandal was a case study conducted to examine the causes of the Enron Corporation’s bankruptcy in 2001. The study included interviews, analysis of financial data, and review of documents to identify the accounting practices, corporate culture, and ethical issues that led to the company’s downfall.
- The Fukushima Nuclear Disaster : The Fukushima Nuclear Disaster was a case study conducted to examine the causes of the nuclear accident that occurred at the Fukushima Daiichi Nuclear Power Plant in Japan in 2011. The study included interviews, analysis of data, and review of documents to identify the technical, organizational, and cultural factors that contributed to the disaster.
Application of Case Study
Case studies have a wide range of applications across various fields and industries. Here are some examples:
Business and Management
Case studies are widely used in business and management to examine real-life situations and develop problem-solving skills. Case studies can help students and professionals to develop a deep understanding of business concepts, theories, and best practices.
Case studies are used in healthcare to examine patient care, treatment options, and outcomes. Case studies can help healthcare professionals to develop critical thinking skills, diagnose complex medical conditions, and develop effective treatment plans.
Case studies are used in education to examine teaching and learning practices. Case studies can help educators to develop effective teaching strategies, evaluate student progress, and identify areas for improvement.
Social Sciences
Case studies are widely used in social sciences to examine human behavior, social phenomena, and cultural practices. Case studies can help researchers to develop theories, test hypotheses, and gain insights into complex social issues.
Law and Ethics
Case studies are used in law and ethics to examine legal and ethical dilemmas. Case studies can help lawyers, policymakers, and ethical professionals to develop critical thinking skills, analyze complex cases, and make informed decisions.
Purpose of Case Study
The purpose of a case study is to provide a detailed analysis of a specific phenomenon, issue, or problem in its real-life context. A case study is a qualitative research method that involves the in-depth exploration and analysis of a particular case, which can be an individual, group, organization, event, or community.
The primary purpose of a case study is to generate a comprehensive and nuanced understanding of the case, including its history, context, and dynamics. Case studies can help researchers to identify and examine the underlying factors, processes, and mechanisms that contribute to the case and its outcomes. This can help to develop a more accurate and detailed understanding of the case, which can inform future research, practice, or policy.
Case studies can also serve other purposes, including:
- Illustrating a theory or concept: Case studies can be used to illustrate and explain theoretical concepts and frameworks, providing concrete examples of how they can be applied in real-life situations.
- Developing hypotheses: Case studies can help to generate hypotheses about the causal relationships between different factors and outcomes, which can be tested through further research.
- Providing insight into complex issues: Case studies can provide insights into complex and multifaceted issues, which may be difficult to understand through other research methods.
- Informing practice or policy: Case studies can be used to inform practice or policy by identifying best practices, lessons learned, or areas for improvement.
Advantages of Case Study Research
There are several advantages of case study research, including:
- In-depth exploration: Case study research allows for a detailed exploration and analysis of a specific phenomenon, issue, or problem in its real-life context. This can provide a comprehensive understanding of the case and its dynamics, which may not be possible through other research methods.
- Rich data: Case study research can generate rich and detailed data, including qualitative data such as interviews, observations, and documents. This can provide a nuanced understanding of the case and its complexity.
- Holistic perspective: Case study research allows for a holistic perspective of the case, taking into account the various factors, processes, and mechanisms that contribute to the case and its outcomes. This can help to develop a more accurate and comprehensive understanding of the case.
- Theory development: Case study research can help to develop and refine theories and concepts by providing empirical evidence and concrete examples of how they can be applied in real-life situations.
- Practical application: Case study research can inform practice or policy by identifying best practices, lessons learned, or areas for improvement.
- Contextualization: Case study research takes into account the specific context in which the case is situated, which can help to understand how the case is influenced by the social, cultural, and historical factors of its environment.
Limitations of Case Study Research
There are several limitations of case study research, including:
- Limited generalizability : Case studies are typically focused on a single case or a small number of cases, which limits the generalizability of the findings. The unique characteristics of the case may not be applicable to other contexts or populations, which may limit the external validity of the research.
- Biased sampling: Case studies may rely on purposive or convenience sampling, which can introduce bias into the sample selection process. This may limit the representativeness of the sample and the generalizability of the findings.
- Subjectivity: Case studies rely on the interpretation of the researcher, which can introduce subjectivity into the analysis. The researcher’s own biases, assumptions, and perspectives may influence the findings, which may limit the objectivity of the research.
- Limited control: Case studies are typically conducted in naturalistic settings, which limits the control that the researcher has over the environment and the variables being studied. This may limit the ability to establish causal relationships between variables.
- Time-consuming: Case studies can be time-consuming to conduct, as they typically involve a detailed exploration and analysis of a specific case. This may limit the feasibility of conducting multiple case studies or conducting case studies in a timely manner.
- Resource-intensive: Case studies may require significant resources, including time, funding, and expertise. This may limit the ability of researchers to conduct case studies in resource-constrained settings.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Observational Research – Methods and Guide

Quantitative Research – Methods, Types and...

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide

Survey Research – Types, Methods, Examples
How to understand and interpret clinical data
This resource, part of the acute pain learning series, has been developed to help pharmacists understand the quality of evidence from clinical data to inform the advice they give to patients.
Shutterstock.com
- A broad range of clinical evidence exists, but understanding the quality and the relevance of those data can be complicated.
- Understanding study design, as well as the statistics and common terms used in the literature will make this vital source of information more accessible.
- Pharmacy professionals must be able to extropolate this information from the evidence base and correctly apply it to patients.
Clinical data inform guidelines and practice, and are the foundation upon which evidence-based medicine rests. However, not all data are equivalent or of equal quality. Consequently, pharmacists and pharmacy teams must develop strategies to assess the quality of evidence for health claims, effectiveness and applicability.
This article will examine the sources of evidence; the variety of evidence types and study designs; and how results are tÂypically reported. It also looks at the precautions pharmacists and pharmacy teams should take when interpreting results as part of the clinical decision-making process, and the questions you should ask yourself when applying evidence-based practice to your patient (see Box), because these decisions can ultimately affect patients. For information on clinical guidelines and the evidence-base to support the management of acute pain, see ‘ Clinical guidelines and evidence base for acute pain management’ .
Types of analytic study design
Experimental.
The objective of clinical studies is to establish the effect of an intervention (e.g. drugs, devices and/or health education). This is achieved by controlling for bias and minimising variation. Randomised controlled trials (RCTs) are considered to be the ‘gold standard’ for the evaluation of proposed interventions (e.g. a new drug treatment). Studies of this type minimise selection bias through randomising the allocation of the intervention and a control (e.g. placebo or standard drug treatment) to participants [1] . In randomised crossover studies, interpatient variability — which may affect outcomes of the study — may be precluded from influencing the findings by allowing participants to serve as their own control. This involves exposing the control participants allocated to the treatment and vice versa at different, predetermined stages of the study, then comparing outcome measures accordingly [2] . Unlike open-label trials, blinding both participants and researchers (‘double blind’) to the intervention type further reduces bias during outcome reporting and interpretation.
Observational analytic
Where allocation of a suitable control may not be possible in some situations (owing to practical or ethical reasons), observational studies — which generally do not involve direct intervention by the researchers — may be carried out. More specifically, a cohort study involves the observation of a group of subjects from the population and tracking outcomes at specified intervals over a given period of time (longitudinal). Alternatively, a cross-sectional study includes subgroups that are representative of the subpopulations that exist in a population of interest and provides a snapshot of outcomes. In the absence of a control group, subjects who are exposed to a treatment may still be compared with other subjects who are matched for one or more relevant variables (e.g. age, health status, socioeconomic background) but are not exposed to the treatment. These are considered to be case-controlled studies.
Systematic review
When a sufficient number of studies have been carried out, the findings can be synthesised in a systematic review, which may involve statistical analysis (also known as meta-analysis). In some instances, different interventions, which have not been directly studied in the same trial but share a common comparator in other studies, may still be compared indirectly in a network meta-analysis (see Figure 1) [3] .

Figure 1: Overview of the main types of analytic study design, including some of their advantages and disadvantages
*Relative to the other options
Sources of evidence
When looking to answer a clinical question, there are many places to find evidence. The Cochrane Database of Systematic Reviews [4] is an excellent starting point because, among other things, each systematic review is independently compiled by at least two people [5] . Included studies are also assessed for quality as well as bias. Evidence summaries available from the Joanna Briggs Institute, an international not-for-profit, research and development centre within the Faculty of Health and Medical Sciences at the University of Adelaide, are also a useful resource as these provide overviews of synthesised evidence presented in systematic reviews [6] . Additionally, evidence from individual studies can be obtained from medical databases including PubMed [7] , EMBASE [8] , CINAHL [9] and the National Institute for Health and Care Excellence [10] , which will include clinical studies from prominent medical journals such as The New England Journal of Medicine [11] , The Lancet [12] , The British Medical Journal [13] and the Journal of the American Medical Association [14] .
Interpreting clinical study data
Once the relevant sources of data have been located, it is important to look more closely at the findings. The questions typically asked of evidence categorically fit into either or both of the following:
- Is treatment or intervention X effective?
- What are the risks associated with the treatment or intervention?
However, the answer is often entangled in a string of numbers and statistics; numbers needed to treat (NNT); odds ratio (OR); hazard ratio (HR); relative risk (RR); absolute risk; confidence intervals (CIs); and P- values. These common terms are best described using a worked example — below is an extract from the Systolic Blood Pressure Intervention Trial (SPRINT) [15] , a randomised, controlled, open-label trial that examined the benefits and risks of prescribing intensive treatment (intervention) versus standard treatment (control) to lower the blood pressure of patients with hypertension.
“… a significantly lower rate of the primary composite outcome in the intensive-treatment group than in the standard-treatment group (1.65% per year vs. 2.19% per year; HR with intensive treatment, 0.75; 95% CI, 0.64–0.89; P<0.001)… Trial participants assigned to the lower systolic blood-pressure target (intensive-treatment group), as compared with those assigned to the higher target (standard-treatment group), had a 25% lower relative risk of the primary outcome… the NNT with a strategy of intensive blood pressure control to prevent one primary outcome event was 61.” [15]
Plainly said, the average annual proportion of patients who suffered a primary composite outcome (i.e. myocardial infarction, other acute coronary syndromes, stroke, heart failure, or death from cardiovascular causes) was lower in the intensive treatment group (1.65%) compared with the control group who received the standard treatment (2.19%).
The HR is the ratio of the chance of an event occurring in the intervention group compared with the control group. In this example, the chance of the primary composite outcome occurring in the intensive treatment group is 75% of (i.e. lower than) the control group, so the ratio is 0.75.
As clinical studies generally involve only a sample of participants from a population (rather than the whole population), CIs are provided to estimate the range in which a statistic for the whole population might be found at a specified probability. Here, it could be said that there is a 95% probability that the true HR for patients from the whole population who are receiving intensive treatment (compared with standard treatment) will be between 0.64 and 0.89 (95% CI, 0.64–0.89), and the probability ( P -value) of the 0.75 HR being erroneous is less than 0.001 (i.e. P <0.001).
The RR describes the ratio of probabilities of an event occurring in a group exposed to treatment compared with that in the control group [16] . In this example, the RR of the primary outcome of the intensive-treatment group as compared with the standard-treatment group is 0.75 (1.65%/2.19% = 0.75; i.e. 25% lower).
NNT refers to the number of patients who need to receive the intervention for one patient to incur the intended outcome of the treatment. In this example, a value of 61 for the NNT (after a median of 3.26 years) can be interpreted in the following way: 1 in every 61 patients receive additional protection to prevent one primary outcome by getting the intensive treatment compared with standard treatments. It is calculated by taking the inverse of the absolute risk reduction, which is the difference in rates of the outcome in the treatment group and that of the control group.
Precautions to take
In order to implement evidence-based practice, there are some questions you need to ask yourself about the clinical data and how to apply it to your patient (see Box).
Box: Key questions to ask when assessing clinical data
- Looking at the level of blinding (e.g. open label, single blind, double blind), the number of participants in the study and the confidence interval (i.e. a wide confidence interval indicates uncertainty in the results) will help here;
- There is also a risk of bias if the trial was cut short or a lot of patients were lost to follow-up.
- Looking at the exclusion criteria for the trial will help here.
- Looking at the variance of the treatment effects will help here; the larger the variance, the less likely the treatment will be for an individual.
- Looking at the statistical significance will help here.
- Looking at how the benefit and harm profiles compare will help here.
- Looking at how the interventions were administered will help here.
- Looking at trial registers and conflicts of interest could help here.
It is not always possible to avoid bias; therefore, it is important to consider potential sources of it when interpreting clinical data. This typically includes inappropriate (or lack of) randomisation of treatment allocation, blinding and treatment of incomplete data [5] . It also important to consider the validity of the data; whether claims are accurately represented. For example, it would be misleading to report and compare incidences of a certain event (such as heart attacks) by absolute numbers rather than that per capita between two comparable communities, because the former does not account for population size, which is likely to influence the findings.
In any study, it is also important to note possible confounding variables. In the SPRINT example above, the researchers excluded patients who had diabetes mellitus or prior stroke because they have a known comorbidity and risk factor, respectively, that would affect the primary outcome of the study. However, by doing this, findings and conclusions are reflective of patients with hypertension in the population and should not be extrapolated to include patients with diabetes mellitus or prior stroke. Other relevant variables that could impact the outcomes of the study (e.g. age, cholesterol levels and body mass index) were adjusted for during analysis.
Outcomes reported in studies where a conflict of interest may exist, such as that arising from research funded by drug companies, should be scrutinised further as outcomes have been shown to be more likely in favour of the sponsor [17] . Collectively, it is also prudent to consider the effect of “publication bias” that typically arises when positive trials are published, while negative trials are likely to remain unpublished, leading to conclusions based on the appraisal of incomplete evidence (see Box). Hence, examining entries and evidence in trial registers (e.g. the WHO International Clinical Trials Registry Platform [18] , UK Clinical Trials Gateway [19] , ISRCTN Registry [20] , ClinicalTrials.gov [21] , Australian New Zealand Clinical Trials Registry [22] ), is considered good practice. Furthermore, as primary outcomes are included in submissions to the trials registry, prior to the commencement of the trial, it enables easy identification of selective reporting [23] . Additionally, reporting guidelines may also be consulted to assess completeness and transparency [24] .
It is a privilege to have a variety of quality sources of evidence (i.e. systematic review databases, medical databases, medical journals and trials registries) that can be accessed and inform clinical decision-making. However, as trials are typically conducted on a sample, rather than the whole population it is important to consider how accurately and the extent to which the findings are representative of the population. Therefore, results (e.g. HR and RR) are typically statistical probabilities, where a high level of confidence (e.g. 95% or 99%) with a reasonably narrow CI or significance indicated by a small P -value (e.g. P <0.05) are more likely to be reflective of outcomes that can be expected in the population given the same intervention.
Furthermore, it is prudent to consider risk of bias, data validity, confounding variables, conflicts of interest, publication bias and selective reporting. These factors are generally best addressed by examining evidence from a variety of sources prior to drawing conclusions and making recommendations for patients.
What do I do next?
The next article in our campaign will explain how you talk to patients about their acute pain management, by using the skills you have gained from understanding the range of guidelines and evidence available.
Safety, mechanism of action and efficacy of over-the-counter pain relief
These video summaries aim to help pharmacists and pharmacy teams make evidence-based product recommendations when consulting with patients about OTC pain relief:
- Safety of over-the-counter pain relief
- Mechanism of action of over-the-counter pain relief
- Efficacy of over-the-counter pain relief
Promotional content from Reckitt
[1] Cox DR. Randomization for concealment. JLL Bulletin: Commentaries on the history of treatment evaluation. 2009. Available at: http://www.jameslindlibrary.org/articles/randomization-for-concealment/ (accessed July 2019)
[2] Sills GJ & Brodie MJ. Antiepileptic drugs: Clinical drug development in epilepsy. In: Schwartzkroin PA, editor. Encyclopedia of Basic Epilepsy Research . Oxford: Academic Press; 2009;1477–1485. doi: 10.1016/B978-012373961-2.00033-3
[3] Li T, Puhan MA, Vedula SS et al. ; The Ad Hoc Network Meta-analysis Methods Meeting Working Group. Network meta-analysis-highly attractive but more methodological research is needed. BMC Med 2011;9(1):79. doi: 10.1186/1741-7015-9-79
[4] Cochrane Library. Available at: https://www.cochranelibrary.com (accessed July 2019)
[5] Higgins J & Green S (Eds). Cochrane Handbook for Systematic Reviews of Interventions. The importance of a team. 2011. Available at: http://handbook-5-1.cochrane.org (accessed July 2019)
[6] The Joanna Briggs Institute. JBI Clinical Online Network of Evidence for Care and Therapeutics (COnNECT+). Available at: http://connect.jbiconnectplus.org/ (accessed July 2019)
[7] PubMed. US National Library of Medicine. Available at: https://www.ncbi.nlm.nih.gov/pubmed/ (accessed July 2019)
[8] Embase. Elsevier. Available at: https://www.elsevier.com/solutions/embase-biomedical-research#search (accessed July 2019)
[9] CINAHL Database. EBSCO Industries. Available at: https://health.ebsco.com/products/the-cinahl-database (accessed July 2019)
[10] National Institute for Health and Care Excellence. Available at: https://www.evidence.nhs.uk/ (accessed July 2019)
[11] The New England Journal of Medicine . Available at: https://www.nejm.org/ (accessed July 2019)
[12] The Lancet. Elsevier Inc. Available at: https://www.thelancet.com/ (accessed July 2019)
[13] The British Medical Journal . BMJ Publishing Group Ltd. Available at: https://www.bmj.com/ (accessed July 2019)
[14] JAMA Network . Available at: https://jamanetwork.com/journals/jama/ (accessed July 2019)
[15] Wright JT Jr, Williamson JD, Whelton PK et al. ; SPRINT research group. A randomized trial of intensive versus standard blood-pressure control. N Engl J Med 2015;373(22):2103–2116. doi: 10.1056/NEJMoa1511939
[16] Tenny S & Hoffman MR. Relative Risk. In: StatPearls. Treasure Island (FL): StatPearls Publishing. 2019. PMID: 28613574
[17] Lexchin J, Bero LA, Djulbegovic B & Clark O. Pharmaceutical industry sponsorship and research outcome and quality: systematic review. BMJ 2003;326(7400):1167. doi: 10.1136/bmj.326.7400.1167
[18] World Health Organization. International Clinical Trials Registry Platform (ICTRP). Available at: https://www.who.int/ictrp/network/primary/en/ (accessed July 2019)
[19] UK Clinical Trials Gateway. Available at: https://www.ukctg.nihr.ac.uk/home/ (accesssed April 2019)
[20] ISRCTN Registry. BioMed Central Ltd. Available from: https://www.isrctn.com/ (accessed April 2019)
[21] ClinicalTrials.gov. NIH, US National Library of Medicine. Available at: https://clinicaltrials.gov/ (accessed July 2019)
[22] Australian New Zealand Clinical Trials Registry. Available at: http://www.anzctr.org.au/ (accessed July 2019)
[23] Eysenbach G. Tackling publication bias and selective reporting in health informatics research: register your ehealth trials in the international ehealth studies registry. J Med Internet Res 2004;6(3):e35. doi: 10.2196/jmir.6.3.e35
[24] EQUATOR Network. UK EQUATOR Centre. Available at: http://www.equator-network.org/ (accessed July 2019)
You might also be interested in…
Artificial intelligence: act or be acted upon — staying relevant in the ai era, equality, diversity and inclusion: why true allyship must shift words into action, pharmacy needs to be at the forefront of shaping digital health — but how do we get there.
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock ( ) or https:// means you've safely connected to the .gov website. Share sensitive information only on official, secure websites.

Analyzing and Interpreting Data
Richard C. Dicker
- Planning the Analysis
- Analyzing Data from a Field Investigation
- Summary Exposure Tables
Stratified Analysis
- Confounding
- Effect Modification
- Dose-Response
- Interpreting Data from a Field Investigation
Field investigations are usually conducted to identify the factors that increased a person’s risk for a disease or other health outcome. In certain field investigations, identifying the cause is sufficient; if the cause can be eliminated, the problem is solved. In other investigations, the goal is to quantify the association between exposure (or any population characteristic) and the health outcome to guide interventions or advance knowledge. Both types of field investigations require suitable, but not necessarily sophisticated, analytic methods. This chapter describes the strategy for planning an analysis, methods for conducting the analysis, and guidelines for interpreting the results.
A thoughtfully planned and carefully executed analysis is as crucial for a field investigation as it is for a protocol-based study. Planning is necessary to ensure that the appropriate hypotheses will be considered and that the relevant data will be collected, recorded, managed, analyzed, and interpreted to address those hypotheses. Therefore, the time to decide what data to collect and how to analyze those data is before you design your questionnaire, not after you have collected the data.
An analysis plan is a document that guides how you progress from raw data to the final report. It describes where you are starting (data sources and data sets), how you will look at and analyze the data, and where you need to finish (final report). It lays out the key components of the analysis in a logical sequence and provides a guide to follow during the actual analysis.
An analysis plan includes some or most of the content listed in Box 8.1 . Some of the listed elements are more likely to appear in an analysis plan for a protocol-based planned study, but even an outbreak investigation should include the key components in a more abbreviated analysis plan, or at least in a series of table shells.
- List of the research questions or hypotheses
- Source(s) of data
- Description of population or groups (inclusion or exclusion criteria)
- Source of data or data sets, particularly for secondary data analysis or population denominators
- Type of study
- How data will be manipulated
- Data sets to be used or merged
- New variables to be created
- Key variables (attach data dictionary of all variables)
- Demographic and exposure variables
- Outcome or endpoint variables
- Stratification variables (e.g., potential confounders or effect modifiers)
- How variables will be analyzed (e.g., as a continuous variable or grouped in categories)
- How to deal with missing values
- Order of analysis (e.g., frequency distributions, two-way tables, stratified analysis, dose-response, or group analysis)
- Measures of occurrence, association, tests of significance, or confidence intervals to be used
- Table shells to be used in analysis
- Tables shells to be included in final report
- Research question or hypotheses . The analysis plan usually begins with the research questions or hypotheses you plan to address. Well-reasoned research questions or hypotheses lead directly to the variables that need to be analyzed and the methods of analysis. For example, the question, “What caused the outbreak of gastroenteritis?” might be a suitable objective for a field investigation, but it is not a specific research question. A more specific question—for example, “Which foods were more likely to have been consumed by case-patients than by controls?”—indicates that key variables will be food items and case–control status and that the analysis method will be a two-by-two table for each food.
- Analytic strategies . Different types of studies (e.g., cohort, case–control, or cross-sectional) are analyzed with different measures and methods. Therefore, the analysis strategy must be consistent with how the data will be collected. For example, data from a simple retrospective cohort study should be analyzed by calculating and comparing attack rates among exposure groups. Data from a case–control study must be analyzed by comparing exposures among case-patients and controls, and the data must account for matching in the analysis if matching was used in the design. Data from a cross-sectional study or survey might need to incorporate weights or design effects in the analysis.The analysis plan should specify which variables are most important—exposures and outcomes of interest, other known risk factors, study design factors (e.g., matching variables), potential confounders, and potential effect modifiers.
- Data dictionary . A data dictionary is a document that provides key information about each variable. Typically, a data dictionary lists each variable’s name, a brief description, what type of variable it is (e.g., numeric, text, or date), allowable values, and an optional comment. Data dictionaries can be organized in different ways, but a tabular format with one row per variable, and columns for name, description, type, legal value, and comment is easy to organize (see example in Table 8.1 from an outbreak investigation of oropharyngeal tularemia [ 1 ]). A supplement to the data dictionary might include a copy of the questionnaire with the variable names written next to each question.
- Get to know your data . Plan to get to know your data by reviewing (1) the frequency of responses and descriptive statistics for each variable; (2) the minimum, maximum, and average values for each variable; (3) whether any variables have the same response for every record; and (4) whether any variables have many or all missing values. These patterns will influence how you analyze these variables or drop them from the analysis altogether.
- Table shells . The next step in developing the analysis plan is designing the table shells. A table shell, sometimes called a dummy table , is a table (e.g., frequency distribution or two-by-two table) that is titled and fully labeled but contains no data. The numbers will be filled in as the analysis progresses. Table shells provide a guide to the analysis, so their sequence should proceed in logical order from simple (e.g., descriptive epidemiology) to more complex (e.g., analytic epidemiology) ( Box 8.2 ). Each table shell should indicate which measures (e.g., attack rates, risk ratios [RR] or odds ratios [ORs], 95% confidence intervals [CIs]) and statistics (e.g., chi-square and p value) should accompany the table. See Handout 8.1 for an example of a table shell created for the field investigation of oropharyngeal tularemia ( 1 ).
The first two tables usually generated as part of the analysis of data from a field investigation are those that describe clinical features of the case-patients and present the descriptive epidemiology. Because descriptive epidemiology is addressed in Chapter 6 , the remainder of this chapter addresses the analytic epidemiology tools used most commonly in field investigations.
Handout 8.2 depicts output from the Classic Analysis module of Epi Info 7 (Centers for Disease Control and Prevention, Atlanta, GA) ( 2 ). It demonstrates the output from the TABLES command for data from a typical field investigation. Note the key elements of the output: (1) a cross-tabulated table summarizing the results, (2) point estimates of measures of association, (3) 95% CIs for each point estimate, and (4) statistical test results. Each of these elements is discussed in the following sections.
Source: Adapted from Reference 1 .
Handout 8.2 : Time, by date of illness onset (could be included in Table 1, but for outbreaks, better to display as an epidemic curve).
Table 1 . Clinical features (e.g., signs and symptoms, percentage of laboratory-confirmed cases, percentage of hospitalized patients, and percentage of patients who died).
Table 2 . Demographic (e.g., age and sex) and other key characteristics of study participants by case–control status if case–control study.
Place (geographic area of residence or occurrence in Table 2 or in a spot or shaded map).
Table 3 . Primary tables of exposure-outcome association.
Table 4 . Stratification (Table 3 with separate effects and assessment of confounding and effect modification).
Table 5 . Refinements (Table 3 with, for example, dose-response, latency, and use of more sensitive or more specific case definition).
Table 6 . Specific group analyses.
Two-by-Two Tables
A two-by-two table is so named because it is a cross-tabulation of two variables—exposure and health outcome—that each have two categories, usually “yes” and “no” ( Handout 8.3 ). The two-by-two table is the best way to summarize data that reflect the association between a particular exposure (e.g., consumption of a specific food) and the health outcome of interest (e.g., gastroenteritis). The association is usually quantified by calculating a measure of association (e.g., a risk ratio [RR] or OR) from the data in the two-by-two table (see the following section).
- In a typical two-by-two table used in field epidemiology, disease status (e.g., ill or well, case or control) is represented along the top of the table, and exposure status (e.g., exposed or unexposed) along the side.
- Depending on the exposure being studied, the rows can be labeled as shown in Table 8.3 , or for example, as exposed and unexposed or ever and never . By convention, the exposed group is placed on the top row.
- Depending on the disease or health outcome being studied, the columns can be labeled as shown in Handout 8.3, or for example, as ill and well, case and control , or dead and alive . By convention, the ill or case group is placed in the left column.
- The intersection of a row and a column in which a count is recorded is known as a cell . The letters a, b, c , and d within the four cells refer to the number of persons with the disease status indicated in the column heading at the top and the exposure status indicated in the row label to the left. For example, cell c contains the number of ill but unexposed persons. The row totals are labeled H 1 and H 0 (or H 2 [H for horizontal ]) and the columns are labeled V 1 and V 0 (or V 2 [V for vertical ]). The total number of persons included in the two-by-two table is written in the lower right corner and is represented by the letter T or N .
- If the data are from a cohort study, attack rates (i.e., the proportion of persons who become ill during the time period of interest) are sometimes provided to the right of the row totals. RRs or ORs, CIs, or p values are often provided to the right of or beneath the table.
The illustrative cross-tabulation of tap water consumption (exposure) and illness status (outcome) from the investigation of oropharyngeal tularemia is displayed in Table 8.2 ( 1 ).
Table Shell: Association Between Drinking Water From Different Sources And Oropharyngeal Tularemia (Sancaktepe Village, Bayburt Province, Turkey, July– August 2013)
Abbreviation: CI, confidence interval. Adapted from Reference 1 .
Typical Output From Classic Analysis Module, Epi Info Version 7, Using The Tables Command
Source: Reference 2 .
Table Shell: Association Between Drinking Water From Different Sources and Oropharyngeal Tularemia (Sancaktepe Village, Bayburt Province, Turkey, July– August 2013)
Abbreviation: CI, confidence interval.
Risk ratio = 26.59 / 10.59 = 2.5; 95% confidence interval = (1.3–4.9); chi-square (uncorrected) = 8.7 (p = 0.003). Source: Adapted from Reference 1.
Measures of Association
A measure of association quantifies the strength or magnitude of the statistical association between an exposure and outcome. Measures of association are sometimes called measures of effect because if the exposure is causally related to the health outcome, the measure quantifies the effect of exposure on the probability that the health outcome will occur.
The measures of association most commonly used in field epidemiology are all ratios—RRs, ORs, prevalence ratios (PRs), and prevalence ORs (PORs). These ratios can be thought of as comparing the observed with the expected—that is, the observed amount of disease among persons exposed versus the expected (or baseline) amount of disease among persons unexposed. The measures clearly demonstrate whether the amount of disease among the exposed group is similar to, higher than, or lower than (and by how much) the amount of disease in the baseline group.
- The value of each measure of association equals 1.0 when the amount of disease is the same among the exposed and unexposed groups.
- The measure has a value greater than 1.0 when the amount of disease is greater among the exposed group than among the unexposed group, consistent with a harmful effect.
- The measure has a value less than 1.0 when the amount of disease among the exposed group is less than it is among the unexposed group, as when the exposure protects against occurrence of disease (e.g., vaccination).
Different measures of association are used with different types of studies. The most commonly used measure in a typical outbreak investigation retrospective cohort study is the RR , which is simply the ratio of attack rates. For most case–control studies, because attack rates cannot be calculated, the measure of choice is the OR .
Cross-sectional studies or surveys typically measure prevalence (existing cases) rather than incidence (new cases) of a health condition. Prevalence measures of association analogous to the RR and OR—the PR and POR , respectively—are commonly used.
Risk Ratio (Relative Risk)
The RR, the preferred measure for cohort studies, is calculated as the attack rate (risk) among the exposed group divided by the attack rate (risk) among the unexposed group. Using the notations in Handout 8.3,
RR=risk exposed /risk unexposed = (a/H 1 ) / (c/H 0 )
From Table 8.2 , the attack rate (i.e., risk) for acquiring oropharyngeal tularemia among persons who had drunk tap water at the banquet was 26.6%. The attack rate (i.e., risk) for those who had not drunk tap water was 10.6%. Thus, the RR is calculated as 0.266/ 0.106 = 2.5. That is, persons who had drunk tap water were 2.5 times as likely to become ill as those who had not drunk tap water ( 1 ).
The OR is the preferred measure of association for case–control data. Conceptually, it is calculated as the odds of exposure among case-patients divided by the odds of exposure among controls. However, in practice, it is calculated as the cross-product ratio. Using the notations in Handout 8.3,
The illustrative data in Handout 8.4 are from a case–control study of acute renal failure in Panama in 2006 (3). Because the data are from a case–control study, neither attack rates (risks) nor an RR can be calculated. The OR—calculated as 37 × 110/ (29 × 4) = 35.1—is exceptionally high, indicating a strong association between ingesting liquid cough syrup and acute renal failure.
Confounding is the distortion of an exposure–outcome association by the effect of a third factor (a confounder ). A third factor might be a confounder if it is
- Associated with the outcome independent of the exposure—that is, it must be an independent risk factor; and,
- Associated with the exposure but is not a consequence of it.
Consider a hypothetical retrospective cohort study of mortality among manufacturing employees that determined that workers involved with the manufacturing process were substantially more likely to die during the follow-up period than office workers and salespersons in the same industry.
- The increase in mortality reflexively might be attributed to one or more exposures during the manufacturing process.
- If, however, the manufacturing workers’ average age was 15 years older than the other workers, mortality reasonably could be expected to be higher among the older workers.
- In that situation, age likely is a confounder that could account for at least some of the increased mortality. (Note that age satisfies the two criteria described previously: increasing age is associated with increased mortality, regardless of occupation; and, in that industry, age was associated with job—specifically, manufacturing employees were older than the office workers).
Unfortunately, confounding is common. The first step in dealing with confounding is to look for it. If confounding is identified, the second step is to control for or adjust for its distorting effect by using available statistical methods.
Looking for Confounding
The most common method for looking for confounding is to stratify the exposure–outcome association of interest by the third variable suspected to be a confounder.
- Because one of the two criteria for a confounding variable is that it should be associated with the outcome, the list of potential confounders should include the known risk factors for the disease. The list also should include matching variables. Because age frequently is a confounder, it should be considered a potential confounder in any data set.
- For each stratum, compute a stratum-specific measure of association. If the stratification variable is sex, only women will be in one stratum and only men in the other. The exposure–outcome association is calculated separately for women and for men. Sex can no longer be a confounder in these strata because women are compared with women and men are compared with men.
The OR is a useful measure of association because it provides an estimate of the association between exposure and disease from case–control data when an RR cannot be calculated. Additionally, when the outcome is relatively uncommon among the population (e.g., <5%), the OR from a case–control study approximates the RR that would have been derived from a cohort study, had one been performed. However, when the outcome is more common, the OR overestimates the RR.
Prevalence Ratio and Prevalence Odds Ratio
Cross-sectional studies or surveys usually measure the prevalence rather than incidence of a health status (e.g., vaccination status) or condition (e.g., hypertension) among a population. The prevalence measures of association analogous to the RR and OR are, respectively, the PR and POR .
The PR is calculated as the prevalence among the index group divided by the prevalence among the comparison group. Using the notations in Handout 8.3 ,
PR = prevalence index / prevalence comparison = (a/H 1 ) / (c/H 0 )
The POR is calculated like an OR.
POR = ad/bc
In a study of HIV seroprevalence among current users of crack cocaine versus never users, 165 of 780 current users were HIV-positive (prevalence = 21.2%), compared with 40 of 464 never users (prevalence = 8.6%) (4). The PR and POR were close (2.5 and 2.8, respectively), but the PR is easier to explain.
Odds ratio = 35.1; 95% confidence interval = (11.6–106.4); chi-square (uncorrected) = 65.6 (p<0.001). Source: Adapted from Reference 3 .
Measures of Public Health Impact
A measure of public health impact places the exposure–disease association in a public health perspective. The impact measure reflects the apparent contribution of the exposure to the health outcome among a population. For example, for an exposure associated with an increased risk for disease (e.g., smoking and lung cancer), the attributable risk percent represents the amount of lung cancer among smokers ascribed to smoking, which also can be regarded as the expected reduction in disease load if the exposure could be removed or had never existed.
For an exposure associated with a decreased risk for disease (e.g., vaccination), the prevented fraction represents the observed reduction in disease load attributable to the current level of exposure among the population. Note that the terms attributable and prevented convey more than mere statistical association. They imply a direct cause-and-effect relationship between exposure and disease. Therefore, these measures should be presented only after thoughtful inference of causality.
Attributable Risk Percent
The attributable risk percent (attributable fraction or proportion among the exposed, etiologic fraction) is the proportion of cases among the exposed group presumably attributable to the exposure. This measure assumes that the level of risk among the unexposed group (who are considered to have the baseline or background risk for disease) also applies to the exposed group, so that only the excess risk should be attributed to the exposure. The attributable risk percent can be calculated with either of the following algebraically equivalent formulas:
Attributable risk percent = (risk exposed / risk unexposed ) / risk exposed = (RR–1) / RR
In a case– control study, if the OR is a reasonable approximation of the RR, an attributable risk percent can be calculated from the OR.
Attributable risk percent = (OR–1) / OR
In the outbreak setting, attributable risk percent can be used to quantify how much of the disease burden can be ascribed to particular exposure.
Prevented Fraction Among the Exposed Group (Vaccine Efficacy)
The prevented fraction among the exposed group can be calculated when the RR or OR is less than 1.0. This measure is the proportion of potential cases prevented by a beneficial exposure (e.g., bed nets that prevent nighttime mosquito bites and, consequently, malaria). It can also be regarded as the proportion of new cases that would have occurred in the absence of the beneficial exposure. Algebraically, the prevented fraction among the exposed population is identical to vaccine efficacy.
Prevented fraction among the exposed group = vaccine efficacy = (risk exposed / risk unexposed ) /= risk unexposed = 1 RR
Handout 8.5 displays data from a varicella (chickenpox) outbreak at an elementary school in Nebraska in 2004 ( 5 ). The risk for varicella was 13.6% among vaccinated children and 66.7% among unvaccinated children. The vaccine efficacy based on these data was calculated as (0.667 – 0.130)/ 0.667 = 0.805, or 80.5%. This vaccine efficacy of 80.5% indicates that vaccination prevented approximately 80% of the cases that would have otherwise occurred among vaccinated children had they not been vaccinated.
Risk ratio = 13.0/ 66.7 = 0.195; vaccine efficacy = (66.7 − 13.0)/ 66.7 = 80.5%. Source: Adapted from Reference 5 .
Tests of Statistical Significance
Tests of statistical significance are used to determine how likely the observed results would have occurred by chance alone if exposure was unrelated to the health outcome. This section describes the key factors to consider when applying statistical tests to data from two-by-two tables.
- Statistical testing begins with the assumption that, among the source population, exposure is unrelated to disease. This assumption is known as the null hypothesis . The alternative hypothesis , which will be adopted if the null hypothesis proves to be implausible, is that exposure is associated with disease.
- Next, compute a measure of association (e.g., an RR or OR).
- A small p value means that you would be unlikely to observe such an association if the null hypothesis were true. In other words, a small p value indicates that the null hypothesis is implausible, given available data.
- If this p value is smaller than a predetermined cutoff, called alpha (usually 0.05 or 5%), you discard (reject) the null hypothesis in favor of the alternative hypothesis. The association is then said to be statistically significant .
- If the p value is larger than the cutoff (e.g., p value >0.06), do not reject the null hypothesis; the apparent association could be a chance finding.
- In a type I error (also called alpha error ), the null hypothesis is rejected when in fact it is true.
- In a type II error (also called beta error ), the null hypothesis is not rejected when in fact it is false.
Testing and Interpreting Data in a Two-by-Two Table
For data in a two-by-two table Epi Info reports the results from two different tests—chi-square test and Fisher exact test—each with variations ( Handout 8.2 ). These tests are not specific to any particular measure of association. The same test can be used regardless of whether you are interested in RR, OR, or attributable risk percent.
- If the expected value in any cell is less than 5. Fisher exact test is the commonly accepted standard when the expected value in any cell is less than 5. (Remember: The expected value for any cell can be determined by multiplying the row total by the column total and dividing by the table total.)
- If all expected values in the two-by-two table are 5 or greater. Choose one of the chi-square tests. Fortunately, for most analyses, the three chi-square formulas provide p values sufficiently similar to make the same decision regarding the null hypothesis based on all three. However, when the different formulas point to different decisions (usually when all three p values are approximately 0.05), epidemiologic judgment is required. Some field epidemiologists prefer the Yates-corrected formula because they are least likely to make a type I error (but most likely to make a type II error). Others acknowledge that the Yates correction often overcompensates; therefore, they prefer the uncorrected formula. Epidemiologists who frequently perform stratified analyses are accustomed to using the Mantel-Haenszel formula; therefore, they tend to use this formula even for simple two-by-two tables.
- Measure of association. The measures of association (e.g., RRs and ORs) reflect the strength of the association between an exposure and a disease. These measures are usually independent of the size of the study and can be regarded as the best guess of the true degree of association among the source population. However, the measure gives no indication of its reliability (i.e., how much faith to put in it).
- Test of significance. In contrast, a test of significance provides an indication of how likely it is that the observed association is the result of chance. Although the chi-square test statistic is influenced both by the magnitude of the association and the study size, it does not distinguish the contribution of each one. Thus, the measure of association and the test of significance (or a CI; see Confidence Intervals for Measures of Association) provide complementary information.
- Role of statistical significance. Statistical significance does not by itself indicate a cause-and-effect association. An observed association might indeed represent a causal connection, but it might also result from chance, selection bias, information bias, confounding, or other sources of error in the study’s design, execution, or analysis. Statistical testing relates only to the role of chance in explaining an observed association, and statistical significance indicates only that chance is an unlikely, although not impossible, explanation of the association. Epidemiologic judgment is required when considering these and other criteria for inferring causation (e.g., consistency of the findings with those from other studies, the temporal association between exposure and disease, or biologic plausibility).
- Public health implications of statistical significance. Finally, statistical significance does not necessarily mean public health significance. With a large study, a weak association with little public health or clinical relevance might nonetheless be statistically significant. More commonly, if a study is small, an association of public health or clinical importance might fail to reach statistically significance.
Confidence Intervals for Measures of Association
Many medical and public health journals now require that associations be described by measures of association and CIs rather than p values or other statistical tests. A measure of association such as an RR or OR provides a single value (point estimate) that best quantifies the association between an exposure and health outcome. A CI provides an interval estimate or range of values that acknowledge the uncertainty of the single number point estimate, particularly one that is based on a sample of the population.
The 95% Confidence Interval
Statisticians define a 95% CI as the interval that, given repeated sampling of the source population, will include, or cover, the true association value 95% of the time. The epidemiologic concept of a 95% CI is that it includes range of values consistent with the data in the study ( 6 ).
Relation Between Chi-Square Test and Confidence Interval
The chi-square test and the CI are closely related. The chi-square test uses the observed data to determine the probability ( p value) under the null hypothesis, and one rejects the null hypothesis if the probability is less than alpha (e.g., 0.05). The CI uses a preselected probability value, alpha (e.g., 0.05), to determine the limits of the interval (1 − alpha = 0.95), and one rejects the null hypothesis if the interval does not include the null association value. Both indicate the precision of the observed association; both are influenced by the magnitude of the association and the size of the study group. Although both measure precision, neither addresses validity (lack of bias).
Interpreting the Confidence Interval
- Meaning of a confidence interval . A CI can be regarded as the range of values consistent with the data in a study. Suppose a study conducted locally yields an RR of 4.0 for the association between intravenous drug use and disease X; the 95% CI ranges from 3.0 to 5.3. From that study, the best estimate of the association between intravenous drug use and disease X among the general population is 4.0, but the data are consistent with values anywhere from 3.0 to 5.3. A study of the same association conducted elsewhere that yielded an RR of 3.2 or 5.2 would be considered compatible, but a study that yielded an RR of 1.2 or 6.2 would not be considered compatible. Now consider a different study that yields an RR of 1.0, a CI from 0.9 to 1.1, and a p value = 0.9. Rather than interpreting these results as nonsignificant and uninformative, you can conclude that the exposure neither increases nor decreases the risk for disease. That message can be reassuring if the exposure had been of concern to a worried public. Thus, the values that are included in the CI and values that are excluded by the CI both provide important information.
- Width of the confidence interval. The width of a CI (i.e., the included values) reflects the precision with which a study can pinpoint an association. A wide CI reflects a large amount of variability or imprecision. A narrow CI reflects less variability and higher precision. Usually, the larger the number of subjects or observations in a study, the greater the precision and the narrower the CI.
- Relation of the confidence interval to the null hypothesis. Because a CI reflects the range of values consistent with the data in a study, the CI can be used as a substitute for statistical testing (i.e., to determine whether the data are consistent with the null hypothesis). Remember: the null hypothesis specifies that the RR or OR equals 1.0; therefore, a CI that includes 1.0 is compatible with the null hypothesis. This is equivalent to concluding that the null hypothesis cannot be rejected. In contrast, a CI that does not include 1.0 indicates that the null hypothesis should be rejected because it is inconsistent with the study results. Thus, the CI can be used as a surrogate test of statistical significance.
Confidence Intervals in the Foodborne Outbreak Setting
In the setting of a foodborne outbreak, the goal is to identify the food or other vehicle that caused illness. In this setting, a measure of the association (e.g., an RR or OR) is calculated to identify the food(s) or other consumable(s) with high values that might have caused the outbreak. The investigator does not usually care if the RR for a specific food item is 5.7 or 9.3, just that the RR is high and unlikely to be caused by chance and, therefore, that the item should be further evaluated. For that purpose, the point estimate (RR or OR) plus a p value is adequate and a CI is unnecessary.
For field investigations intended to identify one or more vehicles or risk factors for disease, consider constructing a single table that can summarize the associations for multiple exposures of interest. For foodborne outbreak investigations, the table typically includes one row for each food item and columns for the name of the food; numbers of ill and well persons, by food consumption history; food-specific attack rates (if a cohort study was conducted); RR or OR; chi-square or p value; and, sometimes, a 95% CI. The food most likely to have caused illness will usually have both of the following characteristics:
- An elevated RR, OR, or chi-square (small p value), reflecting a substantial difference in attack rates among those who consumed that food and those who did not.
- The majority of the ill persons had consumed that food; therefore, the exposure can explain or account for most if not all of the cases.
In illustrative summary Table 8.3 , tap water had the highest RR (and the only p value <0.05, based on the 95% CI excluding 1.0) and might account for 46 of 55 cases.
Abbreviation: CI, confidence interval. Source: Adapted from Reference 1 .
Stratification is the examination of an exposure–disease association in two or more categories (strata) of a third variable (e.g., age). It is a useful tool for assessing whether confounding is present and, if it is, controlling for it. Stratification is also the best method for identifying effect modification . Both confounding and effect modification are addressed in following sections.
Stratification is also an effective method for examining the effects of two different exposures on a disease. For example, in a foodborne outbreak, two foods might seem to be associated with illness on the basis of elevated RRs or ORs. Possibly both foods were contaminated or included the same contaminated ingredient. Alternatively, the two foods might have been eaten together (e.g., peanut butter and jelly or doughnuts and milk), with only one being contaminated and the other guilty by association. Stratification is one way to tease apart the effects of the two foods.
Creating Strata of Two-by-Two Tables
- To stratify by sex, create a two-by-two table for males and another table for females.
- To stratify by age, decide on age groupings, making certain not to have overlapping ages; then create a separate two-by-two table for each age group.
- For example, the data in Table 8.2 are stratified by sex in Handouts 8.6 and 8.7 . The RR for drinking tap water and experiencing oropharyngeal tularemia is 2.3 among females and 3.6 among males, but stratification also allows you to see that women have a higher risk than men, regardless of tap water consumption.
The Two-by-Four Table
Stratified tables (e.g., Handouts 8.6 and 8.7 ) are useful when the stratification variable is not of primary interest (i.e., is not being examined as a cause of the outbreak). However, when each of the two exposures might be the cause, a two-by-four table is better for disentangling the effects of the two variables. Consider a case–control study of a hypothetical hepatitis A outbreak that yielded elevated ORs both for doughnuts (OR = 6.0) and milk (OR = 3.9). The data organized in a two-by-four table ( Handout 8.8 ) disentangle the effects of the two foods—exposure to doughnuts alone is strongly associated with illness (OR = 6.0), but exposure to milk alone is not (OR = 1.0).
When two foods cause illness—for example when they are both contaminated or have a common ingredient—the two-by-four table is the best way to see their individual and joint effects.
Source: Adapted from Reference 1.
Crude odds ratio for doughnuts = 6.0; crude odds ratio for milk = 3.9.
- To look for confounding, first examine the smallest and largest values of the stratum-specific measures of association and compare them with the value of the combined table (called the crude value ). Confounding is present if the crude value is outside the range between the smallest and largest stratum-specific values.
- If the crude risk ratio or odds ratio is outside the range of the stratum-specific ones.
- If the crude risk ratio or odds ratio differs from the Mantel-Haenszel adjusted one by >10% or >20%.
Controlling for Confounding
- One method of controlling for confounding is by calculating a summary RR or OR based on a weighted average of the stratum-specific data. The Mantel-Haenszel technique ( 6 ) is a popular method for performing this task.
- A second method is by using a logistic regression model that includes the exposure of interest and one or more confounding variables. The model produces an estimate of the OR that controls for the effect of the confounding variable(s).
Effect modification or effect measure modification means that the degree of association between an exposure and an outcome differs among different population groups. For example, measles vaccine is usually highly effective in preventing disease if administered to children aged 12 months or older but is less effective if administered before age 12 months. Similarly, tetracycline can cause tooth mottling among children, but not adults. In both examples, the association (or effect) of the exposure (measles vaccine or tetracycline) is a function of, or is modified by, a third variable (age in both examples).
Because effect modification means different effects among different groups, the first step in looking for effect modification is to stratify the exposure–outcome association of interest by the third variable suspected to be the effect modifier. Next, calculate the measure of association (e.g., RR or OR) for each stratum. Finally, assess whether the stratum-specific measures of association are substantially different by using one of two methods.
- Examine the stratum-specific measures of association. Are they different enough to be of public health or scientific importance?
- Determine whether the variation in magnitude of the association is statistically significant by using the Breslow-Day Test for homogeneity of odds ratios or by testing the interaction term in logistic regression.
If effect modification is present, present each stratum-specific result separately.
In epidemiology, dose-response means increased risk for the health outcome with increasing (or, for a protective exposure, decreasing) amount of exposure. Amount of exposure reflects quantity of exposure (e.g., milligrams of folic acid or number of scoops of ice cream consumed), or duration of exposure (e.g., number of months or years of exposure), or both.
The presence of a dose-response effect is one of the well-recognized criteria for inferring causation. Therefore, when an association between an exposure and a health outcome has been identified based on an elevated RR or OR, consider assessing for a dose-response effect.
As always, the first step is to organize the data. One convenient format is a 2-by-H table, where H represents the categories or doses of exposure. An RR for a cohort study or an OR for a case–control study can be calculated for each dose relative to the lowest dose or the unexposed group ( Handout 8.9 ). CIs can be calculated for each dose. Reviewing the data and the measures of association in this format and displaying the measures graphically can provide a sense of whether a dose-response association is present. Additionally, statistical techniques can be used to assess such associations, even when confounders must be considered.
The basic data layout for a matched-pair analysis is a two-by-two table that seems to resemble the simple unmatched two-by-two tables presented earlier in this chapter, but it is different ( Handout 8.10 ). In the matched-pair two-by-two table, each cell represents the number of matched pairs that meet the row and column criteria. In the unmatched two-by-two table, each cell represents the number of persons who meet the criteria.
In Handout 8.10 , cell e contains the number of pairs in which the case-patient is exposed and the control is exposed; cell f contains the number of pairs with an exposed case-patient and an unexposed control, cell g contains the number of pairs with an unexposed case-patient and an exposed control, and cell h contains the number of pairs in which neither the case-patient nor the matched control is exposed. Cells e and h are called concordant pairs because the case-patient and control are in the same exposure category. Cells f and g are called discordant pairs .
Odds ratio = f/ g.
In a matched-pair analysis, only the discordant pairs are used to calculate the OR. The OR is computed as the ratio of the discordant pairs.
The test of significance for a matched-pair analysis is the McNemar chi-square test.
Handout 8.11 displays data from the classic pair-matched case–control study conducted in 1980 to assess the association between tampon use and toxic shock syndrome ( 7 ).
Odds ratio = 9/ 1 = 9.0; uncorrected McNemar chi-square test = 6.40 (p = 0.01). Source: Adapted from Reference 7 .
- Larger matched sets and variable matching. In certain studies, two, three, four, or a variable number of controls are matched with case-patients. The best way to analyze these larger or variable matched sets is to consider each set (e.g., triplet or quadruplet) as a unique stratum and then analyze the data by using the Mantel-Haenszel methods or logistic regression to summarize the strata (see Controlling for Confounding).
- Does a matched design require a matched analysis? Usually, yes. In a pair-matched study, if the pairs are unique (e.g., siblings or friends), pair-matched analysis is needed. If the pairs are based on a nonunique characteristic (e.g., sex or grade in school), all of the case-patients and all of the controls from the same stratum (sex or grade) can be grouped together, and a stratified analysis can be performed.
In practice, some epidemiologists perform the matched analysis but then perform an unmatched analysis on the same data. If the results are similar, they might opt to present the data in unmatched fashion. In most instances, the unmatched OR will be closer to 1.0 than the matched OR (bias toward the null). This bias, which is related to confounding, might be either trivial or substantial. The chi-square test result from unmatched data can be particularly misleading because it is usually larger than the McNemar test result from the matched data. The decision to use a matched analysis or unmatched analysis is analogous to the decision to present crude or adjusted results; epidemiologic judgment must be used to avoid presenting unmatched results that are misleading.
Logistic Regression
In recent years, logistic regression has become a standard tool in the field epidemiologist’s toolkit because user-friendly software has become widely available and its ability to assess effects of multiple variables has become appreciated. Logistic regression is a statistical modeling method analogous to linear regression but for a binary outcome (e.g., ill/well or case/control). As with other types of regression, the outcome (the dependent variable) is modeled as a function of one or more independent variables. The independent variables include the exposure(s) of interest and, often, confounders and interaction terms.
- The exponentiation of a given beta coefficient (e β ) equals the OR for that variable while controlling for the effects of all of the other variables in the model.
- If the model includes only the outcome variable and the primary exposure variable coded as (0,1), e β should equal the OR you can calculate from the two-by-two table. For example, a logistic regression model of the oropharyngeal tularemia data with tap water as the only independent variable yields an OR of 3.06, exactly the same value to the second decimal as the crude OR. Similarly, a model that includes both tap water and sex as independent variables yields an OR for tap water of 3.24, almost identical to the Mantel-Haenszel OR for tap water controlling for sex of 3.26. (Note that logistic regression provides ORs rather than RRs, which is not ideal for field epidemiology cohort studies.)
- Logistic regression also can be used to assess dose-response associations, effect modification, and more complex associations. A variant of logistic regression called conditional logistic regression is particularly appropriate for pair-matched data.
Sophisticated analytic techniques cannot atone for sloppy data ! Analytic techniques such as those described in this chapter are only as good as the data to which they are applied. Analytic techniques—whether simple, stratified, or modeling—use the information at hand. They do not know or assess whether the correct comparison group was selected, the response rate was adequate, exposure and outcome were accurately defined, or the data coding and entry were free of errors. Analytic techniques are merely tools; the analyst is responsible for knowing the quality of the data and interpreting the results appropriately.
A computer can crunch numbers more quickly and accurately than the investigator can by hand, but the computer cannot interpret the results. For a two-by-two table, Epi Info provides both an RR and an OR, but the investigator must choose which is best based on the type of study performed. For that table, the RR and the OR might be elevated; the p value might be less than 0.05; and the 95% CI might not include 1.0. However, do those statistical results guarantee that the exposure is a true cause of disease? Not necessarily. Although the association might be causal, flaws in study design, execution, and analysis can result in apparent associations that are actually artifacts. Chance, selection bias, information bias, confounding, and investigator error should all be evaluated as possible explanations for an observed association. The first step in evaluating whether an apparent association is real and causal is to review the list of factors that can cause a spurious association, as listed in Epidemiologic Interpretation Checklist 1 ( Box 8.4 ).
- Selection bias
- Information bias
- Investigator error
- True association
Epidemiologic Interpretation Checklist 1
Chance is one possible explanation for an observed association between exposure and outcome. Under the null hypothesis, you assume that your study population is a sample from a source population in which that exposure is not associated with disease; that is, the RR and OR equal 1. Could an elevated (or lowered) OR be attributable simply to variation caused by chance? The role of chance is assessed by using tests of significance (or, as noted earlier, by interpreting CIs). Chance is an unlikely explanation if
- The p value is less than alpha (usually set at 0.05), or
- The CI for the RR or OR excludes 1.0.
However, chance can never be ruled out entirely. Even if the p value is as small as 0.01, that study might be the one study in 100 in which the null hypothesis is true and chance is the explanation. Note that tests of significance evaluate only the role of chance—they do not address the presence of selection bias, information bias, confounding, or investigator error.
Selection bias is a systematic error in the designation of the study groups or in the enrollment of study participants that results in a mistaken estimate of an exposure’s effect on the risk for disease. Selection bias can be thought of as a problem resulting from who gets into the study or how. Selection bias can arise from the faulty design of a case– control study through, for example, use of an overly broad case definition (so that some persons in the case group do not actually have the disease being studied) or inappropriate control group, or when asymptomatic cases are undetected among the controls. In the execution phase, selection bias can result if eligible persons with certain exposure and disease characteristics choose not to participate or cannot be located. For example, if ill persons with the exposure of interest know the hypothesis of the study and are more willing to participate than other ill persons, cell a in the two-by-two table will be artificially inflated compared with cell c , and the OR also will be inflated. Evaluating the possible role of selection bias requires examining how case-patients and controls were specified and were enrolled.
Information bias is a systematic error in the data collection from or about the study participants that results in a mistaken estimate of an exposure’s effect on the risk for disease. Information bias might arise by including poor wording or understanding of a question on a questionnaire; poor recall; inconsistent interviewing technique; or if a person knowingly provides false information, either to hide the truth or, as is common among certain cultures, in an attempt to please the interviewer.
Confounding is the distortion of an exposure–disease association by the effect of a third factor, as discussed earlier in this chapter. To evaluate the role of confounding, ensure that potential confounders have been identified, evaluated, and controlled for as necessary.
Investigator error can occur at any step of a field investigation, including design, conduct, analysis, and interpretation. In the analysis, a misplaced semicolon in a computer program, an erroneous transcription of a value, use of the wrong formula, or misreading of results can all yield artifactual associations. Preventing this type of error requires rigorous checking of work and asking colleagues to carefully review the work and conclusions.
To reemphasize, before considering whether an association is causal, consider whether the association can be explained by chance, selection bias, information bias, confounding, or investigator error . Now suppose that an elevated RR or OR has a small p value and narrow CI that does not include 1.0; therefore, chance is an unlikely explanation. Specification of case-patients and controls was reasonable and participation was good; therefore, selection bias is an unlikely explanation. Information was collected by using a standard questionnaire by an experienced and well-trained interviewer. Confounding by other risk factors was assessed and determined not to be present or to have been controlled for. Data entry and calculations were verified. However, before concluding that the association is causal, the strength of the association, its biologic plausibility, consistency with results from other studies, temporal sequence, and dose-response association, if any, need to be considered ( Box 8.5 ).
- Strength of the association
- Biologic plausibility
- Consistency with other studies
- Exposure precedes disease
- Dose-response effect
Epidemiologic Interpretation Checklist 2
Strength of the association means that a stronger association has more causal credibility than a weak one. If the true RR is 1.0, subtle selection bias, information bias, or confounding can result in an RR of 1.5, but the bias would have to be dramatic and hopefully obvious to the investigator to account for an RR of 9.0.
Biological plausibility means an association has causal credibility if is consistent with the known pathophysiology, known vehicles, natural history of the health outcome, animal models, and other relevant biological factors. For an implicated food vehicle in an infectious disease outbreak, has the food been implicated in previous outbreaks, or—even better—has the agent been identified in the food? Although some outbreaks are caused by new or previously unrecognized pathogens, vehicles, or risk factors, most are caused by those that have been recognized previously.
Consider c onsistency with other studies . Are the results consistent with those from previous studies? A finding is more plausible if it has been replicated by different investigators using different methods for different populations.
Exposure precedes disease seems obvious, but in a retrospective cohort study, documenting that exposure precedes disease can be difficult. Suppose, for example, that persons with a particular type of leukemia are more likely than controls to have antibodies to a particular virus. It might be tempting to conclude that the virus caused the leukemia, but caution is required because viral infection might have occurred after the onset of leukemic changes.
Evidence of a dose-response effect adds weight to the evidence for causation. A dose-response effect is not a necessary feature for an association to be causal; some causal association might exhibit a threshold effect, for example. Nevertheless, it is usually thought to add credibility to the association.
In many field investigations, a likely culprit might not meet all the criteria discussed in this chapter. Perhaps the response rate was less than ideal, the etiologic agent could not be isolated from the implicated food, or no dose-response was identified. Nevertheless, if the public’s health is at risk, failure to meet every criterion should not be used as an excuse for inaction. As George Comstock stated, “The art of epidemiologic reasoning is to draw sensible conclusions from imperfect data” ( 8 ). After all, field epidemiology is a tool for public health action to promote and protect the public’s health on the basis of science (sound epidemiologic methods), causal reasoning, and a healthy dose of practical common sense.
All scientific work is incomplete—whether it be observational or experimental. All scientific work is liable to be upset or modified by advancing knowledge. That does not confer upon us a freedom to ignore the knowledge we already have, or to postpone the action it seems to demand at a given time ( 9 ).
— Sir Austin Bradford Hill (1897–1991), English Epidemiologist and Statistician
- Aktas D, Celebi B, Isik ME, et al. Oropharyngeal tularemia outbreak associated with drinking contaminated tap water, Turkey, July–September 2013. Emerg Infect Dis. 2015;21:2194–6.
- Centers for Disease Control and Prevention. Epi Info. https://www.cdc.gov/epiinfo/index.html
- Rentz ED, Lewis L, Mujica OJ, et al. Outbreak of acute renal failure in Panama in 2006: a case-–control study. Bull World Health Organ. 2008;86:749–56.
- Edlin BR, Irwin KL, Faruque S, et al. Intersecting epidemics—crack cocaine use and HIV infection among inner-city young adults. N Eng J Med. 1994;331:1422–7.
- Centers for Disease Control and Prevention. Varicella outbreak among vaccinated children—Nebraska, 2004. MMWR. 2006;55;749–52.
- Rothman KJ. Epidemiology: an introduction . New York: Oxford University Press; 2002: p . 113–29.
- Shands KN, Schmid GP, Dan BB, et al. Toxic-shock syndrome in menstruating women: association with tampon use and Staphylococcus aureus and clinical features in 52 women. N Engl J Med . 1980;303:1436–42.
- Comstock GW. Vaccine evaluation by case–control or prospective studies. Am J Epidemiol. 1990;131:205–7.
- Hill AB. The environment and disease: association or causation? Proc R Soc Med. 1965;58:295–300.
< Previous Chapter 7: Designing and Conducting Analytic Studies in the Field
Next Chapter 9: Optimizing Epidemiology– Laboratory Collaborations >
The fellowship application period will be open March 1-June 5, 2024.
The host site application period is closed.
For questions about the EIS program, please contact us directly at [email protected] .
- Laboratory Leadership Service (LLS)
- Fellowships and Training Opportunities
- Division of Workforce Development
Exit Notification / Disclaimer Policy
- The Centers for Disease Control and Prevention (CDC) cannot attest to the accuracy of a non-federal website.
- Linking to a non-federal website does not constitute an endorsement by CDC or any of its employees of the sponsors or the information and products presented on the website.
- You will be subject to the destination website's privacy policy when you follow the link.
- CDC is not responsible for Section 508 compliance (accessibility) on other federal or private website.
Numbers, Facts and Trends Shaping Your World
Read our research on:
Full Topic List
Regions & Countries
- Publications
- Our Methods
- Short Reads
- Tools & Resources
Read Our Research On:
Electric Vehicle Charging Infrastructure in the U.S.
64% of americans live within 2 miles of a public charging station, and those who live closest to chargers view evs more positively, table of contents.
- Distribution of EV charging stations in the U.S.
- Who lives closest to EV charging stations?
- Attitudes toward EVs vary based on proximity to chargers
- Acknowledgments
- Appendix A: Regression analyses
- Appendix B: Vehicle-to-charger ratios for each state
- American Trends Panel survey methodology
- Additional survey questions
- Sources for geographic data

Pew Research Center conducted this study to understand Americans’ views on electric vehicles. We surveyed 10,329 U.S. adults from May 30 to June 4, 2023.
Everyone who took part in the survey is a member of the Center’s American Trends Panel (ATP), an online survey panel that is recruited through national, random sampling of residential addresses. This way, nearly all U.S. adults have a chance of selection. The survey is weighted to be representative of the U.S. adult population by gender, race, ethnicity, partisan affiliation, education and other categories. Read more about the ATP’s methodology .
We supplemented the data from the survey with data on EVs and charging stations from the U.S. Energy Department, specifically the Office of Energy Efficiency & Renewable Energy and its Alternative Fuels Data Center . This dataset is updated frequently; we accessed it for this study on Feb. 27, 2024.
The analysis in this report relies on two different measures of community type, one based on what ATP panelists self-reported when asked “How would you describe the community where you currently live?” This measure is used when discussing differences in public opinion towards EV charging infrastructure or related issues and distinguishes between urban, suburban and rural areas. The other measure is based on the U.S. Census Bureau’s urban-rural classification , which identifies urban and rural areas based on minimum housing unit density and/or population density thresholds.
Here are the questions used for this analysis, along with responses, and the survey methodology .
Several recent laws, including the 2021 Infrastructure Investment and Jobs Act and the 2022 Inflation Reduction Act, have sought to encourage the development of electric vehicle infrastructure and increase the adoption of electric vehicles (EVs). And a Pew Research Center survey paired with an analysis of U.S. Department of Energy data finds that roughly six-in-ten Americans now live within 2 miles of a public charger . There were over 61,000 publicly accessible electric vehicle charging stations in the United States as of February 2024.

The vast majority of EV charging occurs at home , but access to public infrastructure is tightly linked with Americans’ opinions of electric vehicles themselves. Our analysis finds that Americans who live close to public chargers view EVs more positively than those who are farther away .
Even when accounting for factors like partisan identification and community type, Americans who live close to EV chargers are more likely to say they:
- Already own an electric or hybrid vehicle
- Would consider buying an EV for their next vehicle
- Favor phasing out production of new gasoline cars and trucks by 2035
- Are confident that the U.S. will build the necessary infrastructure to support large numbers of EVs on the roads
Here are some other key takeaways from our geographic analysis of EV chargers:
The number of EV charging stations has more than doubled since 2020. In December 2020, the Department of Energy reported that there were nearly 29,000 public charging stations nationwide. By February 2024, that number had increased to more than 61,000 stations. Over 95% of the American public now lives in a county that has at least one public EV charging station.
EV charging stations are most accessible to residents of urban areas: 60% of urban residents live less than a mile from the nearest public EV charger , compared with 41% of those in the suburbs and just 17% of rural Americans.
How Americans view electric vehicles
- Today’s electric vehicle market: Slow growth in U.S., faster in China, Europe
As of Feb. 27, 2024, there are more than 61,000 publicly accessible electric vehicle charging stations with Level 2 or DC Fast chargers in the U.S. 1 That is a more than twofold increase from roughly 29,000 stations in 2020 . For reference, there are an estimated 145,000 gasoline fueling stations in the country.
EV charging stations can be found in two-thirds of all U.S. counties, which collectively include 95% of the country’s population.

Distribution by state
As has been the case in the past, California has the most EV charging infrastructure of any state. The state is home to a quarter of all public EV charging stations in the U.S., though this represents a slight decrease from the last time we analyzed this data source in May 2021. At that time, California contained 31% of all public EV charging stations in the U.S.
Californians with an EV might also have a harder time than residents of many states when it comes to the actual experience of finding and using a charger. Despite having the most charging stations of any state, California’s 43,780 individual public charging ports must provide service for the more than 1.2 million electric vehicles registered to its residents. That works out to one public port for every 29 EVs, a ratio that ranks California 49th across all 50 states and the District of Columbia.
At the other end of the spectrum, Wyoming (one-to-six), North Dakota (one-to-six) and West Virginia (one-to-eight) have the most ports relative to the much smaller number of EVs registered in their respective states.
Infrastructure growth in rural areas
Historically, rural parts of the country have had substantially less access to EV charging stations . Addressing that issue has been a focus of recent legislation passed into law. For instance, the 2022 Inflation Reduction Act (IRA) contains tax credits designed to incentivize the installation of EV charging stations outside urban areas.
Since the IRA’s tax credits became active , the number of EV charging stations nationwide has increased 29%. But rural parts of the U.S. have a slightly faster growth rate in their total number of charging stations when compared with urban areas (34% vs. 29%). 2 Even so, access to public EV charging remains heavily concentrated in urban areas, which account for nearly 90% of all stations in the U.S. as of Feb. 27, 2024.
The vast majority of Americans now live in a county with at least one public EV charging station, but some live closer to this infrastructure than others: 39% of Americans live within a mile of a public charging station, and 64% have a charging station within 2 miles of home.

Americans who live in cities are especially likely to have a public charging station very close to their home. Six-in-ten urban residents live within a mile of a public charger, compared with 41% of suburbanites and just 17% of rural Americans.
Because of this distribution, those who live closest to EV charging infrastructure tend to share the demographic characteristics of urban residents more broadly. For instance, they tend to be relatively young and are more likely to have a college degree than those in other community types.
Looking at political affiliation, 48% of Democrats and Democratic-leaning independents live within a mile of a public charger, compared with 31% of Republicans and Republican leaners.
However, there are no substantial differences in distance to the nearest charger by income. Similar shares of Americans with lower, middle and upper incomes live within a mile of public charging stations.
On the whole, the American public is fairly skeptical that the U.S. will be able to build the infrastructure necessary to support large numbers of EVs on the roads.

Just 17% of U.S. adults say they are extremely or very confident in the country’s ability to develop this infrastructure. But 20% of those who live within a mile of a public charger say they’re extremely or very confident that the U.S. will build the infrastructure necessary to support EVs, almost twice the share (11%) among those who live more than 2 miles from a charging station.
Likewise, those who live closer to public chargers are more likely to favor phasing out production of new gasoline cars and trucks by 2035. This view is held by 49% of those who live within a mile of a public charger, but just 30% of those who live more than 2 miles from one.
Owning – or considering – an electric vehicle
Americans who live near a public charger are a bit more likely to say they currently own an electric vehicle or hybrid. As of June 2023, 11% of those who live within a mile of a public charger said they owned an EV or hybrid; that figure is 7% for those who live more than 2 miles from a charging station.
Those who live close to public charging infrastructure are also much more likely to consider purchasing an EV in the future. Around half of those within a mile of a public charger say they are very or somewhat likely to consider purchasing an EV, compared with just 27% of those for whom the nearest charger is more than 2 miles away.

These trends persist if we look at urban, suburban and rural areas separately. 3 For instance, just 17% of rural Americans live within a mile of an EV charger, but those who do live close to one are substantially more likely to consider buying an EV in the future (33%) when compared with those who live more than 2 miles from the nearest charging station (21%).
Likewise, Democrats are much more likely than Republicans to say they’d consider buying an EV, but members of both parties are more willing to consider an EV when they live near charging infrastructure.
Just 15% of Republicans who live more than 2 miles from a charger say they are very or somewhat likely to consider an EV for their next vehicle purchase. But among Republicans who live within a mile of a charger, that share is 26%. And although 60% of Democrats living in close proximity to chargers say they’d consider buying an EV, that share drops to 50% among those whose nearest public charger is over 2 miles away.
Does road tripping experience affect attitudes toward EVs?

Some transportation experts have suggested that “range anxiety” associated with the need to charge EVs partway through longer road trips is a stumbling block to widespread EV adoption . But our data finds that attitudes toward EVs don’t differ that much based on how often people take long car trips.
In fact, those who regularly drive more than 100 miles are slightly more likely to say they currently own an electric vehicle or hybrid – and also to say they’d consider purchasing an EV in the future – when compared with those who make these trips less often.
- These charging stations collectively contain more than 164,000 individual ports. ↩
- The 2022 Inflation Reduction Act uses the Census Bureau’s definition of urban versus rural areas, which defines an urban area as a census block that encompasses at least 2,000 housing units or has a population of at least 5,000. ↩
- In addition to the results reported here, we used binary logistic regression to explore these (and other) relationships while accounting for other attributes (in regression parlance, while “controlling” for other factors). For more about this methodology and to see the results of that analysis in more detail, refer to Appendix A . ↩
Sign up for our weekly newsletter
Fresh data delivery Saturday mornings
Sign up for The Briefing
Weekly updates on the world of news & information
- Rural Residents & Tech
- Rural, Urban and Suburban Communities
How Republicans view climate change and energy issues
Growing share of americans favor more nuclear power, why some americans do not see urgency on climate change, what the data says about americans’ views of climate change, most popular, report materials.
1615 L St. NW, Suite 800 Washington, DC 20036 USA (+1) 202-419-4300 | Main (+1) 202-857-8562 | Fax (+1) 202-419-4372 | Media Inquiries
Research Topics
- Email Newsletters
ABOUT PEW RESEARCH CENTER Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
© 2024 Pew Research Center
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
How One Company Added Carbon Estimates to Its Customer Invoices
- Robert S. Kaplan
- Timmy Melotte

A four-step playbook to help businesses increase transparency and reduce emissions.
Soprema is an international building materials supplier, producing millions of square meters of waterproofing, insulating, and roofing products each year. In 2022, Pierre-Etienne Bindschedler, the company’s president and third-generation owner, committed to reporting the carbon footprint of each product on every customer invoice, and to help customers reduce the embedded GHG emissions in the products they purchased. Paper co-author Melotte, an experienced operations director, was selected to lead a pilot project to measure and subsequently lower the carbon embedded in its products. Melotte decided to follow the E-Liability Pilot Playbook, which divides a pilot project into four stages: Project Design, Data Collection; Data Analysis, and Action. This article describes how the pilot, which focused on the company’s bitumen waterproofing systems, unfolded at Soprema. The company estimates a potential carbon footprint reduction of 34% from the project.
In 2022, Pierre-Etienne Bindschedler, the president and third-generation owner of Soprema, set a goal to develop sustainable solutions for customers. Soprema is a multi-product, family-owned business in the middle of the building materials value chain and produces millions of square meters of waterproofing, insulating, and roofing products each year. Bindschedler wanted to report the carbon footprint of each product on every customer invoice, and to help customers reduce the embedded GHG emissions in the products they purchased.
- Robert S. Kaplan is a senior fellow and the Marvin Bower Professor of Leadership Development emeritus at Harvard Business School. He coauthored the McKinsey Award–winning HBR article “ Accounting for Climate Change ” (November–December 2021).
- TM Timmy Melotte is an Operational Excellence Director for Soprema International, a building materials supplier based in Limburg, Belgium
Partner Center
'ZDNET Recommends': What exactly does it mean?
ZDNET's recommendations are based on many hours of testing, research, and comparison shopping. We gather data from the best available sources, including vendor and retailer listings as well as other relevant and independent reviews sites. And we pore over customer reviews to find out what matters to real people who already own and use the products and services we’re assessing.
When you click through from our site to a retailer and buy a product or service, we may earn affiliate commissions. This helps support our work, but does not affect what we cover or how, and it does not affect the price you pay. Neither ZDNET nor the author are compensated for these independent reviews. Indeed, we follow strict guidelines that ensure our editorial content is never influenced by advertisers.
ZDNET's editorial team writes on behalf of you, our reader. Our goal is to deliver the most accurate information and the most knowledgeable advice possible in order to help you make smarter buying decisions on tech gear and a wide array of products and services. Our editors thoroughly review and fact-check every article to ensure that our content meets the highest standards. If we have made an error or published misleading information, we will correct or clarify the article. If you see inaccuracies in our content, please report the mistake via this form .
How to use ChatGPT to make charts and tables with Advanced Data Analysis

Know what floats my boat? Charts and graphs.
Give me a cool chart to dig into and I'm unreasonably happy. I love watching the news on election nights, not for the vote count, but for all the great charts. I switch between channels all evening to see every possible way that each network finds to present numerical data.
Is that weird? I don't think so.
Also: The moment I realized ChatGPT Plus was a game-changer for my business
As it turns out, ChatGPT does a great job making charts and tables. And given that this ubiquitous generative AI chatbot can synthesize a ton of information into something chart-worthy, what ChatGPT gives up in pretty presentation it more than makes up for in informational value.
It should come as no surprise to anybody that AI chatbots' feature sets are changing constantly. As of the time of this update (end of May, 2024), OpenAI has just come out with a Mac application and has release its GPT-4o LLM, which is available for both free and paying customers. The GPT-4o version that comes for the added-price Plus version is supposed to have interactive chart features and the ability to interact with the engine longer per session.
But, not so much. My free account doesn't offer GPT-4o at all yet. It hasn't rolled out to all free accounts yet. And while paid ChatGPT Plus plan does provide the interactive charts feature in Chrome and Safari, it doesn't in the Mac app.
Also: ChatGPT vs. ChatGPT Plus: Is a paid subscription still worth it?
This article was last updated when the Advanced Data Analysis features (which included charts) were only available to Plus customers. Even though some of those features are supposed to be available to free customers, since my free account doesn't have them yet, I'm going to present the rest of this article as if the charting features are only available to Plus customers. If you're a free customer and you have GPT-4o, feel free to try some of the prompts. Those features may work for you, and undoubtely will as we move forward in time.
Advanced Data Analysis produces relatively ugly charts. But it rocks. First, let's discuss where ChatGPT gets its data, then we'll make some tables.
How to use ChatGPT to make charts and tables
1. understand the different versions of chatgpt.
Earlier, we talked about which charting tools are available in which versions of ChatGPT. But there's more to it than simply charting tools. If you want to use ChatGPT productively, you need to understand what the various editions can do.
ChatGPT free version: This version has historically used the GPT-3.5 large language model (LLM), which isn't quite as capable as the GPT-4 version . As of May 2024, the GPT-4o LLM is also available to some free users and rolling out over time.
ChatGPT Plus: ChatGPT Plus is OpenAI's commercial, fully powered version of ChatGPT. Right now, ChatGPT Plus provides three major selection options per session: GPT-3.5, GPT-4, and GPT-4o. It used to offer plugins, but they've been replaced by custom GPTs .
The GPT-4 and GPT-4o versions now include DALL-E 3, Bing Web access, and Advanced Data Analysis. Some users have reported some difficulty with using Bing for web access. Most of what we will be doing is using the Advanced Data Analysis component. Even without Bing web access, GPT-4 and 4o report that training data now includes information up to December 2023.
Also: What does GPT stand for? Understanding GPT 3.5, GPT 4, GPT-4o, and more
For much of this article, we will be using the Advanced Data Analysis component of the GPT-4 option. This tool will import data tables in a wide range of file formats. While it doesn't specify a size limit for imported data, it can handle fairly large files, but will break if the files exceed some undefined level of complexity.
As ChatGPT Plus changes, and it will, we will update you with more information. For now, let's just look at making some cool charts.
ChatGPT Enterprise: Advanced Data Analytics and plugins are also available in the enterprise version . You can upload files to Enterprise, and they will remain confidential. Enterprise is also supposed to allow for bigger files and bigger responses. Pricing has not been specified.
2. Create a basic table
Let's start with an example. For the following demonstration, we'll be working with the top five cities in terms of population.
List the top five cities in the world by population. Include country.
I asked this question to ChatGPT's free version and here's what I got back:
Turning that data into a table is simple. Just tell ChatGPT you want a table:
Make a table of the top five cities in the world by population. Include country.
3. Manipulate the table
You can manipulate and customize a table by giving ChatGPT more detailed instructions. Again, using the free version, we'll add a population count field. Of course, that data is out of date, but it's presented anyway:
Make a table of the top five cities in the world by population. Include country and a population field
You can also specify certain details for the table, like field order and units. Here, I'm moving the country first and compressing the population numbers.
Make a table of the top five cities in the world by population. Include country and a population field. Display the fields in the order of rank, country, city, population. Display population in millions (with one decimal point), so 37,833,000 would display as 37.8M.
Note that I gave the AI an example of how I wanted the numbers to display.
That's about as far as the free version will take us. From now on, we're switching to the $20/month ChatGPT Plus version .
4. Create a bar chart
ChatGPT Plus with Advanced Data Analytics enabled can make line charts, bar charts, histograms, pie charts, scatter plots, heatmaps, box plots, area charts, bubble charts, Gantt charts, Pareto charts, network diagrams, Sankey diagrams, choropleth maps, radar charts, word clouds, treemaps, and 3D charts.
In this example, we're just going to make a simple bar chart.
Make a bar chart of the top five cities in the world by population
Chatty little tool, isn't it?
The eagle-eyed among you may have noticed the discrepancy in populations between the previous table shown and the results here. Notice that the table has a green icon and this graph has a purple icon. We've jumped from GPT-3.5 (the free version of ChatGPT) to GPT-4 (in ChatGPT Plus). It's interesting that the differing LLMs have slightly different data. This difference is all part of why it pays to be careful when using AIs, so double-check your work. In our case, we're just demonstrating charts, but this is a tangible example of where confidently presented data can be wrong or inconsistent.
5. Upload data
One of Advanced Data Analytics' superpowers is the ability to upload a dataset. For our example, I downloaded the Popular Baby Names dataset from Data.gov . This is a comma-separated file of New York City baby names from 2011-2014. Even though it's a decade out of date, it's fun to play with.
The dataset I chose for this article is readily available from a government site, so you can replicate this experiment on your own. There are a ton of great datasets available on Data.gov , but I found that many are far too large for ChatGPT to use.
Also: How to use ChatGPT to create an app
Once I downloaded this one, I realized it also included information on ethnicity, so we can run a number of different charts from the same dataset.
Click the little upload button and then tell it the data file you want to import.
I asked it to show me the first five lines of the file so I'd know more about the file's format.
6. Create a pie chart (and change colors)
I was curious about how the dataset distributed gender names. Here's my first prompt:
Create a pie chart showing gender as a percentage of the overall dataset
And here's the result:
Unfortunately, the dark shade of green makes the numbers difficult to read. Fortunately, you can instruct Advanced Data Analytics to use different colors. I was careful to choose colors that did not reinforce gender stereotypes.
Create a pie chart showing gender as a percentage of the overall dataset. Use light green for male and medium yellow for female.
7. Normalize data for accuracy
As we saw earlier, the data collected includes ethnicity. Here's how to see the distribution of the various ethnicities New York recorded in the early 2010s:
Show the distribution of ethnicity in the dataset using a pie chart. Use only light colors.
And here's the result. Notice anything?
Apparently, New York didn't properly normalize its data. It used "WHITE NON HISPANIC" and "WHITE NON HISP" together, "BLACK NON HISPANIC" and "BLACK NON HISP" together, and "ASIAN AND PACIFIC ISLANDER" and "ASIAN AND PACI" together. This resulted in inaccurate representations of the data.
One benefit of ChatGPT is it remembers instructions throughout a session. So I was able to give it this instruction:
For all the following requests, group "WHITE NON HISPANIC" and "WHITE NON HISP" together. Group "BLACK NON HISPANIC" and "BLACK NON HISP" together. Group "ASIAN AND PACIFIC ISLANDER" and "ASIAN AND PACI". Use the longer of the two ethnicity names when displaying ethnicity.
And it replied:
Let's try the chart again, using the same prompt.
That's better:
You need to be diligent when looking at results. For example, in a request for top baby names, the AI separated out "Madison" and "MADISON" as two different names:
For all the following requests, baby names should be case insensitive.
8. Export your graphics
Let's wrap up with a complex chart from one prompt. Here's our prompt:
For each ethnicity, present two pie charts, one for each gender. Each pie chart should list the top five baby names for that gender and that ethnicity. Use only light colors.
As it turns out, the chart generated text that was too small to read. So, to get a more useful chart, we can export it back out. I'm going to specify both file format and file width:
Export this chart as a 3000 pixel wide JPG file.
Notice that Sofia and Sophia are very popular, but are shown as two different names. But that's what makes charts so fascinating.
How much does it cost to use Advanced Data Analytics?
Advanced Data Analytics comes with ChatGPT Plus. Some of its features are available in GPT-4o for the free version of ChatGPT. ChatGPT Plus is $20/month. Advanced Data Analytics also is included with the Enterprise edition, but pricing for that hasn't been released yet.
Is the data uploaded to ChatGPT for charting kept private or is there a risk of data exposure?
Assume that there's always a privacy risk.
I asked this question to ChatGPT and this is what it told me:
Data privacy is a priority for ChatGPT. Uploaded data is used solely for the purpose of the user's current session and is not stored long-term or used for any other purposes. However, for highly sensitive data, users should always exercise caution and consider using the Enterprise version of ChatGPT, which offers enhanced data confidentiality.
Also: Generative AI brings new risks to everyone. Here's how you can stay safe
My recommendation: Don't trust ChatGPT or any generative AI tool. The Enterprise version is supposed to have more privacy controls, but I would recommend you only upload data that you won't mind finding its way to public visibility.
Can ChatGPT's Advanced Data Analysis handle real-time data or is it more suited for static datasets?
It's possible, but there are some practical limitations. First, the Plus account will throttle the number of requests you can make in a given period of time. Second, you have to upload each file individually. There is the possibility you could use a licensed ChatGPT API to do real-time analytics. But for the chatbot itself, you're looking at parsing data at rest.
You can follow my day-to-day project updates on social media. Be sure to subscribe to my weekly update newsletter on Substack , and follow me on Twitter at @DavidGewirtz , on Facebook at Facebook.com/DavidGewirtz , on Instagram at Instagram.com/DavidGewirtz , and on YouTube at YouTube.com/DavidGewirtzTV .
Artificial Intelligence
How to use chatgpt plus: from gpt-4o to interactive tables, chatgpt will put your data into interactive tables and charts with gpt-4o, how to use chatgpt to write excel formulas.
Advertisement
Supported by
Ozempic Cuts Risk of Chronic Kidney Disease Complications, Study Finds
A major clinical trial showed such promising results that the drug’s maker halted it early.
- Share full article

By Dani Blum
Dani Blum has reported on Ozempic and similar drugs since 2022.
Semaglutide, the compound in the blockbuster drugs Ozempic and Wegovy , dramatically reduced the risk of kidney complications, heart issues and death in people with Type 2 diabetes and chronic kidney disease in a major clinical trial, the results of which were published on Friday. The findings could transform how doctors treat some of the sickest patients with chronic kidney disease, which affects more than one in seven adults in the United States but has no cure.
“Those of us who really care about kidney patients spent our whole careers wanting something better,” said Dr. Katherine Tuttle, a professor of medicine at the University of Washington School of Medicine and an author of the study. “And this is as good as it gets.” The research was presented at a European Renal Association meeting in Stockholm on Friday and simultaneously published in The New England Journal of Medicine .
The trial, funded by Ozempic maker Novo Nordisk, was so successful that the company stopped it early . Dr. Martin Holst Lange, Novo Nordisk’s executive vice president of development, said that the company would ask the Food and Drug Administration to update Ozempic’s label to say it can also be used to reduce the progression of chronic kidney disease or complications in people with Type 2 diabetes.
Diabetes is a leading cause of chronic kidney disease, which occurs when the kidneys don’t function as well as they should. In advanced stages, the kidneys are so damaged that they cannot properly filter blood. This can cause fluid and waste to build up in the blood, which can exacerbate high blood pressure and raise the risk of heart disease and stroke, said Dr. Subramaniam Pennathur, the chief of the nephrology division at Michigan Medicine.
The study included 3,533 people with kidney disease and Type 2 diabetes, about half of whom took a weekly injection of semaglutide, and half of whom took a weekly placebo shot.
Researchers followed up with participants after a median period of around three and a half years and found that those who took semaglutide had a 24 percent lower likelihood of having a major kidney disease event, like losing at least half of their kidney function, or needing dialysis or a kidney transplant. There were 331 such events among the semaglutide group, compared with 410 in the placebo group.
People who received semaglutide were much less likely to die from cardiovascular issues, or from any cause at all, and had slower rates of kidney decline.
Kidney damage often occurs gradually, and people typically do not show symptoms until the disease is in advanced stages. Doctors try to slow the decline of kidney function with existing medications and lifestyle modifications, said Dr. Melanie Hoenig, a nephrologist at Beth Israel Deaconess Medical Center who was not involved with the study. But even with treatment, the disease can progress to the point that patients need dialysis, a treatment that removes waste and excess fluids from the blood, or kidney transplants.
The participants in the study were extremely sick — the severe complications seen in some study participants are more likely to occur in people the later stages of chronic kidney disease, said Dr. George Bakris, a professor of medicine at the University of Chicago Medicine and an author of the study. Most participants in the trial were already taking medication for chronic kidney disease.
For people with advanced kidney disease, in particular, the findings are promising. “We can help people live longer,” said Dr. Vlado Perkovic, a nephrologist and renal researcher at the University of New South Wales, Sydney, and another author of the study.
While the data shows clear benefits, even the researchers studying drugs like Ozempic aren’t sure how, exactly, they help the kidneys. One leading theory is that semaglutide may reduce inflammation, which exacerbates kidney disease.
And the results come with several caveats: Roughly two-thirds of the participants were men and around two-thirds were white — a limitation of the study, the authors noted, because chronic kidney disease disproportionately affects Black and Indigenous patients. The trial participants taking semaglutide were more likely to stop the drug because of gastrointestinal issues, which are common side effects of Ozempic.
Doctors said they wanted to know whether the drug might benefit patients who have kidney disease but not diabetes, and some also had questions about the potential long-term risks of taking semaglutide.
Still, the results are the latest data to show that semaglutide can do more than treat diabetes or drive weight loss. In March, the F.D.A. authorized Wegovy for reducing the risk of cardiovascular issues in some patients. And scientists are examining semaglutide and tirzepatide, the compound in the rival drugs Mounjaro and Zepbound, for a range of other conditions , including sleep apnea and liver disease.
If the F.D.A. approves the new use, it could drive even more demand for Ozempic, which has faced recurrent shortages .
“I think it’s a game changer,” Dr. Hoenig said, “if I can get it for my patients.”
Dani Blum is a health reporter for The Times. More about Dani Blum
A Close Look at Weight-Loss Drugs
Reduced Disease Complications: Semaglutide, the compound in Ozempic and Wegovy, dramatically reduced the risk of kidney complications , heart issues and death in people with Type 2 diabetes and chronic kidney disease in a major clinical trial.
Supplement Stores: GNC and the Vitamin Shoppe are redesigning displays and taking other steps to appeal to people who are taking or are interested in drugs like Ozempic and Wegovy.
Senate Investigation: A Senate committee is investigating the prices that Novo Nordisk charges for Ozempic and Wegovy, which are highly effective at treating diabetes and obesity but carry steep price tags.
A Company Remakes Itself: Novo Nordisk’s factories work nonstop turning out Ozempic and Wegovy , but the Danish company has far bigger ambitions.
Transforming a Small Danish Town: In Kalundborg, population under 17,000, Novo Nordisk is making huge investments to increase production of Ozempic and Wegovy.
In the tech world and beyond, new 5G applications are being discovered every day. From driverless cars to smarter cities, farms, and even shopping experiences, the latest standard in wireless networks is poised to transform the way we interact with information, devices and each other. What better time to take a closer look at how humans are putting 5G to use to transform their world.
What is 5G?
5G (fifth-generation mobile technology is the newest standard for cellular networks. Like its predecessors, 3G, 4G and 4G LTE, 5G technology uses radio waves for data transmission. However, due to significant improvements in latency, throughput and bandwidth, 5G is capable of faster download and upload speeds than previous networks.
Since its release in 2019, 5G broadband technology has been hailed as a breakthrough technology with significant implications for both consumers and businesses. Primarily, this is due to its ability to handle large volumes of data that is generated by complex devices that use its networks.
As mobile technology has expanded over the years, the number of data users generate every day has increased exponentially. Currently, other transformational technologies like artificial intelligence (AI), the Internet of Things (IoT ) and machine learning (ML) require faster speeds to function than 3G and 4G networks offer. Enter 5G, with its lightning-fast data transfer capabilities that allow newer technologies to function in the way they were designed to.
Here are some of the biggest differences between 5G and previous wireless networks.
- Physical footprint : The transmitters that are used in 5G technology are smaller than in predecessors’ networks, allowing for discrete placement in out-of-the-way places. Furthermore, “cells”—geographical areas that all wireless networks require for connectivity—in 5G networks are smaller and require less power to run than in previous generations.
- Error rates : 5G’s adaptive Modulation and Coding Scheme (MCS), a schematic that wifi devices use to transmit data, is more powerful than ones in 3G and 4G networks. This makes 5G’s Block Error Rate (BER)—a metric of error frequency—much lower.
- Bandwidth : By using a broader spectrum of radio frequencies than previous wireless networks, 5G networks can transmit on a wider range of bandwidths. This increases the number of devices that they can support at any given time.
- Lower latency : 5G’s low latency , a measurement of the time it takes data to travel from one location to another, is a significant upgrade over previous generations. This means that routine activities like downloading a file or working in the cloud is going to be faster with a 5G connection than a connection on a different network.
Like all wireless networks, 5G networks are separated into geographical areas that are known as cells. Within each cell, wireless devices—such as smartphones, PCs, and IoT devices—connect to the internet via radio waves that are transmitted between an antenna and a base station. The technology that underpins 5G is essentially the same as in 3G and 4G networks. But due to its lower latency, 5G networks are capable of delivering faster download speeds—in some cases as high as 10 gigabits per second (Gbps).
As more and more devices are built for 5G speeds, demand for 5G connectivity is growing. Today, many popular Internet Service Providers (ISPs), such as Verizon, Google and AT&T, offer 5G networks to homes and businesses. According to Statista, more than 200 million homes and businesses have already purchased it with that number expected to at least double by 2028 (link resides outside ibm.com).
Let’s take a look at three areas of technological improvement that have made 5G so unique.
New telecom specifications
The 5G NR (New Radio) standard for cellular networks defines a new radio access technology (RAT) specification for all 5G mobile networks. The 5G rollout began in 2018 with a global initiative known as the 3rd Generation Partnership Project (3FPP). The initiative defined a new set of standards to steer the design of devices and applications for use on 5G networks.
The initiative was a success, and 5G networks grew swiftly in the ensuing years. Today, 45% of networks worldwide are 5G compatible, with that number forecasted to rise to 85% by the end of the decade according to a recent report by Ericsson (link resides outside ibm.com).
Independent virtual networks (network slicing)
On 5G networks, network operators can offer multiple independent virtual networks (in addition to public ones) on the same infrastructure. Unlike previous wireless networks, this new capability allows users to do more things remotely with greater security than ever before. For example, on a 5G network, enterprises can create use cases or business models and assign them their own independent virtual network. This dramatically improves the user experience for their employees by adding greater customizability and security.
Private networks
In addition to network slicing, creating a 5G private network can also enhance personalization and security features over those available on previous generations of wireless networks. Global businesses seeking more control and mobility for their employees increasingly turn to private 5G network architectures rather than public networks they’ve used in the past.
Now that we better understand how 5G technology works, let’s take a closer look at some of the exciting applications it’s enabling.
Autonomous vehicles
From taxi cabs to drones and beyond, 5G technology underpins most of the next-generation capabilities in autonomous vehicles. Until the 5G cellular standard came along, fully autonomous vehicles were a bit of a pipe dream due to the data transmission limitations of 3G and 4G technology. Now, 5G’s lightning-fast connection speeds have made transport systems for cars, trains and more, faster than previous generations, transforming the way systems and devices connect, communicate and collaborate.
Smart factories
5G, along with AI and ML, is poised to help factories become not only smarter but more automated, efficient, and resilient. Today, many mundane but necessary tasks that are associated with equipment repair and optimization are being turned over to machines thanks to 5G connectivity paired with AI and ML capabilities. This is one area where 5G is expected to be highly disruptive, impacting everything from fuel economy to the design of equipment lifecycles and how goods arrive at our homes.
For example, on a busy factory floor, drones and cameras that are connected to smart devices that use the IoT can help locate and transport something more efficiently than in the past and prevent theft. Not only is this better for the environment and consumers, but it also frees up employees to dedicate their time and energy to tasks that are more suited to their skill sets.
Smart cities
The idea of a hyper-connected urban environment that uses 5G network speeds to spur innovation in areas like law enforcement, waste disposal and disaster mitigation is fast becoming a reality. Some cities already use 5G-enabled sensors to track traffic patterns in real time and adjust signals, helping guide the flow of traffic, minimize congestion, and improve air quality.
In another example, 5G power grids monitor supply and demand across heavily populated areas and deploy AI and ML applications to “learn” what times energy is in high or low demand. This process has been shown to significantly impact energy conservation and waste, potentially reducing carbon emissions and helping cities reach sustainability goals.
Smart healthcare
Hospitals, doctors, and the healthcare industry as a whole already benefit from the speed and reliability of 5G networks every day. One example is the area of remote surgery that uses robotics and a high-definition live stream that is connected to the internet via a 5G network. Another is the field of mobile health, where 5G gives medical workers in the field quick access to patient data and medical history. This enables them to make smarter decisions, faster, and potentially save lives.
Lastly, as we saw during the pandemic, contact tracing and the mapping of outbreaks are critical to keeping populations safe. 5G’s ability to deliver of volumes of data swiftly and securely allows experts to make more informed decisions that have ramifications for everyone.
5G paired with new technological capabilities won’t just result in the automation of employee tasks, it will dramatically improve them and the overall employee experience . Take virtual reality (VR) and augmented reality (AR), for example. VR (digital environments that shut out the real world) and AR (digital content that augments the real world) are already used by stockroom employees, transportation drivers and many others. These employees rely on wearables that are connected to a 5G network capable of high-speed data transfer rates that improve several key capabilities, including the following:
- Live views : 5G connectivity provides live, real-time views of equipment, events, and even people. One way in which this feature is being used in professional sports is to allow broadcasters to remotely call a sporting event from outside the stadium where the event is taking place.
- Digital overlays : IoT applications in a warehouse or industrial setting allow workers that are equipped with smart glasses (or even just a smartphone) to obtain real-time insights from an application. This includes repair instructions or the name and location of a spare part.
- Drone inspections : Right now, one of the leading causes of employee injury is inspection of equipment or project sites in remote and potentially dangerous areas. Drones, which are connected via 5G networks, can safely monitor equipment and project sites and even take readings from hard-to-reach gauges.
Edge computing , a computing framework that allows computations to be done closer to data sources, is fast becoming the standard for enterprises. According to this Gartner white paper (link resides outside ibm.com), by 2025, 75% of enterprise data will be processed at the edge (compared to only 10% today). This shift saves businesses time and money and enables better control over large volumes of data. It would be impossible without the new speed standards that are generated by 5G technology.
Ultra-reliable edge computing and 5G enable the enterprise to achieve faster transmission speeds, increased control and greater security over massive volumes of data. Together, these twin technologies will help reduce latency while increasing speed, reliability and bandwidth, resulting in faster, more comprehensive data analysis and insights for businesses everywhere.
5G solutions with IBM Cloud Satellite
5G presents significant opportunities for the enterprise, but first, you need a platform that can handle its speed. IBM Cloud Satellite® lets you deploy and run apps consistently across on-premises, edge computing and public cloud environments on a 5G network. And it’s all enabled by secure and auditable communications within the IBM Cloud®.
Get the latest tech insights and expert thought leadership in your inbox.
Get our newsletters and topic updates that deliver the latest thought leadership and insights on emerging trends.
How hard is it to buy a home right now? The new NBC News Home Buyer Index measures the market

Why is it so hard to buy a home? Prices have far outpaced middle-class incomes. Mortgage rates are above 7% for the first time since 2002. And 3 out of 10 homes are sold above listing price.
But none of those factors fully captures the variety of challenges buyers nationwide face in the current market. The conditions on the ground can vary widely across state and even county lines.
To better capture how housing market conditions shift at the local level — as comprehensively and in as close to real time as possible — we’re introducing a new monthly gauge: the NBC News Home Buyer Index.
The Home Buyer Index, which NBC News developed with the guidance of a real estate industry analyst, a bank economist from the Federal Reserve Bank of Atlanta and other experts, is a number on a scale of 0 to 100 representing the difficulty a potential buyer faces trying to buy a home. The higher the index value, the higher the difficulty.
A low index value, of 10 for example, suggests better purchasing conditions for a buyer — low interest rates, ample homes for sale. Chambers County, Texas, near Houston, is one of the 50 least difficult places to buy in in the country, with low scores on scarcity, cost and competition.
A high value closer to 90 suggests extremely tough conditions, which can result from intense bidding, high insurance costs or steep jumps in home prices relative to income. Prices are soaring in Coconino County, Arizona, making it one of the 25 most difficult counties to buy a home in. Five years ago it was ranked 300, but the median sale price has increased 81%, nearly twice the national figure.
The index measures difficulty nationwide, as well as on the county level, in the counties where there’s enough homebuying data to make informed assessments.
The national index, presented below, captures the big-picture market and economic conditions that affect homebuying across the U.S.
This index consists of four factors:
- Cost: How much a home costs relative to incomes and inflation — as well as how related expenses, such as insurance costs, are changing.
- Competition: How many people are vying for a home — and how aggressive the demand is. This is measured through observations including the percentage of homes sold above list price and the number that went under contract within two weeks of being listed.
- Scarcity: The number of homes that are on the market — and how many more are expected to enter the market in the coming month.
- Economic instability: Market volatility, unemployment and interest rates — reflecting the broader climate in which home shoppers are weighing their decisions.
For April, the overall Home Buyer Index nationally was 82.4, up slightly from March and about 5 points lower than it was this time one year ago.
Improvements in market competitiveness and the broader economy have eased conditions somewhat within the past year. However, high costs and continued housing shortages have kept overall homebuying difficulty high.
The index updates monthly on the Thursday after the third Saturday of the month. The next update is June 20.
Methodology
The NBC News Home Buyer Index combines real estate and financial data with forecasting techniques to assess market conditions from a buyer’s perspective.
The perspective is framed as a combination of factors shaping a buyer’s experience of the housing market: cost, scarcity, competition and overall economic instability.
Each factor is measured by a monthly analysis that takes the following approach:
- Data is collected from sources including Redfin , the Census Bureau, the Bureau of Labor Statistics and the Federal Reserve Bank of St. Louis.
- The data is then cleaned, filtered for quality and transformed to address properties that are needed for statistical analysis, including stationarity and seasonality.
- The data is then brought to a monthly frequency where appropriate, among other steps.
- The data is scaled to make component variables comparable.
- Finally, the data is combined to generate a single, aggregate measure of homebuyer difficulty. The final output is a single value between 0 and 100, where 0 represents the least difficult market possible and 100 is the most difficult.
NBC News worked with real estate industry experts to refine the data that would best answer the question ‘How difficult is it to buy a home in the U.S.?’ The experts came from the Federal Reserve Bank of Atlanta, and Redfin.
Caveats to this analysis include variation in data availability at the county level, which is generally tied to market size, which correlates with regional characteristics such as population count. Therefore, systematic gaps affect low-population counties, leading them to be underrepresented.
In addition, recent index values may shift slightly in future releases as final data comes in.
Jasmine Cui is a reporter for NBC News.
IMAGES
VIDEO
COMMENTS
Qualitative data analysis is a process of gathering, structuring and interpreting qualitative data to understand what it represents. Qualitative data is non-numerical and unstructured. Qualitative data generally refers to text, such as open-ended responses to survey questions or user interviews, but also includes audio, photos and video.
Steps. Download Article. 1. Examine and describe the business environment relevant to the case study. Describe the nature of the organization under consideration and its competitors. Provide general information about the market and customer base.
7) The Use of Dashboards For Data Interpretation. 8) Business Data Interpretation Examples. Data analysis and interpretation have now taken center stage with the advent of the digital age… and the sheer amount of data can be frightening. In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 trillion gigabytes!
In business terms, the interpretation of data is the execution of various processes. This process analyzes and revises data to gain insights and recognize emerging patterns and behaviors. These conclusions will assist you as a manager in making an informed decision based on numbers while having all of the facts at your disposal.
propose an approach to the analysis of case study data by logically linking the data to a series of propositions and then interpreting the subsequent information. Like the Yin (1994) strategy, the Miles and Huberman (1994) process of analysis of case study data, although quite detailed, may still be insufficient to guide the novice researcher.
Case study reporting is as important as empirical material collection and interpretation. The quality of a case study does not only depend on the empirical material collection and analysis but also on its reporting (Denzin & Lincoln, 1998). A sound report structure, along with "story-like" writing is crucial to case study reporting.
How to Analyze a Case Study Adapted from Ellet, W. (2007). The case study handbook. Boston, MA: Harvard Business School. A business case simulates a real situation and has three characteristics: 1. a significant issue, 2. enough information to reach a reasonable conclusion, 3. no stated conclusion. A case may include 1. irrelevant information 2.
Case studies tend to focus on qualitative data using methods such as interviews, observations, and analysis of primary and secondary sources (e.g., newspaper articles, photographs, official records). Sometimes a case study will also collect quantitative data. Example: Mixed methods case study. For a case study of a wind farm development in a ...
This article is a practical introduction to statistical analysis for students and researchers. We'll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between variables. Example: Causal research question.
A case study is a research method that involves an in-depth analysis of a real-life phenomenon or situation. Learn how to write a case study for your social sciences research assignments with this helpful guide from USC Library. Find out how to define the case, select the data sources, analyze the evidence, and report the results.
A case study is an in-depth investigation of a single person, group, event, or community. This research method involves intensively analyzing a subject to understand its complexity and context. The richness of a case study comes from its ability to capture detailed, qualitative data that can offer insights into a process or subject matter that ...
To answer any of these questions, you would collect data from a group of relevant participants and then analyze it. Thematic analysis allows you a lot of flexibility in interpreting the data, and allows you to approach large data sets more easily by sorting them into broad themes. However, it also involves the risk of missing nuances in the data.
Read more: What Does a Data Analyst Do? A Career Guide. Types of data analysis (with examples) Data can be used to answer questions and support decisions in many different ways. To identify the best way to analyze your date, it can help to familiarize yourself with the four types of data analysis commonly used in the field.
ing sense of large amounts of data—reducing raw data, identifying what is significant, and constructing a framework for communicat-ing the essence of what the data reveal. This was the task of chapter 4. The challenge now becomes one of digging into the findings to develop some understanding of what lies beneath them; that is, what information we
Give the answer or the key insights the interviewer is looking for ( "I see three key insights,….". ). Discuss the implications of the data, the 'so-what' for the client problem you are trying to figure out and find a recommendation for. Tie those findings to the case and your analysis and interpret their implications.
Rich data: Case study research can generate rich and detailed data, including qualitative data such as interviews, observations, and documents. This can provide a nuanced understanding of the case and its complexity. ... Subjectivity: Case studies rely on the interpretation of the researcher, which can introduce subjectivity into the analysis ...
At Examine, we dig through hundreds of studies per week — thousands of studies per year! It's a full-time job even for a team of scientists, but don't let that daunt you. In this guide, we give you the 101 on how to approach, question, and interpret a study. Our Examine Membership gives access to summaries of the latest, most important ...
Box: Key questions to ask when assessing clinical data. What are the study's limitations? Looking at the level of blinding (e.g. open label, single blind, double blind), the number of participants in the study and the confidence interval (i.e. a wide confidence interval indicates uncertainty in the results) will help here;
Interpreting the Confidence Interval. Meaning of a confidence interval. A CI can be regarded as the range of values consistent with the data in a study. Suppose a study conducted locally yields an RR of 4.0 for the association between intravenous drug use and disease X; the 95% CI ranges from 3.0 to 5.3.
Case studies are helpful tools when you want to illustrate a specific point or concept. They can be used to show how a data science project works in real life, or they can be used as an example of what to avoid. Data science case studies help students, and entry-level data scientists understand how professionals have approached previous ...
The analysis and interpretation of data is carried out in two phases. The. first part, which is based on the results of the questionnaire, deals with a quantitative. analysis of data. The second, which is based on the results of the interview and focus group. discussions, is a qualitative interpretation.
Histograms are graphs that display the distribution of your continuous data. They are fantastic exploratory tools because they reveal properties about your sample data in ways that summary statistics cannot. For instance, while the mean and standard deviation can numerically summarize your data, histograms bring your sample data to life.
Read more about the ATP's methodology. We supplemented the data from the survey with data on EVs and charging stations from the U.S. Energy Department, specifically the Office of Energy Efficiency & Renewable Energy and its Alternative Fuels Data Center. This dataset is updated frequently; we accessed it for this study on Feb. 27, 2024.
The company estimates a potential carbon footprint reduction of 34% from the project. In 2022, Pierre-Etienne Bindschedler, the president and third-generation owner of Soprema, set a goal to ...
ChatGPT Plus with Advanced Data Analytics enabled can make line charts, bar charts, histograms, pie charts, scatter plots, heatmaps, box plots, area charts, bubble charts, Gantt charts, Pareto ...
Still, the results are the latest data to show that semaglutide can do more than treat diabetes or drive weight loss. In March, the F.D.A. authorized Wegovy for reducing the risk of cardiovascular ...
IBM Cloud Satellite® lets you deploy and run apps consistently across on-premises, edge computing and public cloud environments on a 5G network. And it's all enabled by secure and auditable communications within the IBM Cloud®. A look at the applications and use cases that 5G is enabling to transform the world.
Studies involving foot-and-mouth disease virus revealed that heat inactivation of virus-positive milk samples required higher temperature or longer incubation times (or both) than heat ...
Black Americans feel left out. STAT teamed up with Word In Black, a network of 10 Black news publishers, to report over the past year on the impact of new weight loss drugs on Black America. J ...
The national index, presented below, captures the big-picture market and economic conditions that affect homebuying across the U.S. This index consists of four factors: Cost: How much a home costs ...